深度学习框架火焰图pprof和CUDA Nsys配置指南
注:如下是在做深度学习框架开发时,用到的火焰图pprof和 CUDA Nsys 配置指南,可能对大家有一些帮助,就此分享。一些是基于飞桨的Docker镜像配置的。
一、环境 & 工具配置
0. 开发机配置
# 1.构建镜像, 记得映射端口,可以多映射几个;记得挂载ssd目录,因为数据都在ssd盘上
nvidia-docker run -it --name=profile_dev --shm-size 128G --ulimit core=-1 --cap-add ALL -v $PWD:/workspace -v /ssd1:/ssd1 -v /ssd2:/ssd2 -v /ssd3:/ssd3 --net=host -p 9422:22 -p 9423:9423 -p 9424:9424 registry.baidubce.com/paddlepaddle/paddle:latest-dev-cuda11.2-cudnn8-gcc82 /bin/bash
# 2.更新设置,安装vim
apt update
apt install vim
# 3. 将代理保存到 ~/.my_profile
# 4.安装zsh 和 oh_my_zsh
apt install zsh
sh -c "$(curl -fsSL https://raw.github.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"
# 5. 自动初始化个性化设置
vim ~/.zshrc
# 最后一行添加 source ~/.my_profile
# 6. 配置性能优化工具
apt install libgoogle-perftools-dev
# 7. 创建全局python3.7 沙盒
virtualenv env3.7 --python=python3.7
source env3.7/bin/activate
# 8. 配置pprof
rm -rf /usr/local/go
tar -xzf go1.16.4.linux-amd64.tar.gz -C /usr/local
export GOROOT=/usr/local/go
export PATH=/root/gopath/bin:$GOROOT/bin:$PATH
go version
go get github.com/google/pprof
1. NsightSyetem 工具
1.1 前序准备
NsightSystem 是一个集终端 CUDA Profile 日志生成和 前端可视化 timeline 分析的强大工具。安装 nsys 需要分别下载适合Unix 的 Installer 和 Mac/Windows 的可视化终端。
- Step 1: 注册 Nvidia 账号(略)
- Step 2:下载 Linux Installer
- 下载页面在 此处
- Step 3:下载桌面客户端
- MAC:Nvidia NSight Systems
1.2 安装过程
首先,在创建 docker 镜像时,需要加上 --privileged=true,否则可能无权限读取Performance Counter。比如:
- 现在不允许加
--privileged=true了,只需要加--cap-add ALL即可 - doacker 容器命令前文档最前面
然后,在 docker 容器中的命令行下,安装 nsys:
# step 1: 此处是旧的,推荐大家下载最新的按照包
bash NsightSystems-linux-public-2020.4.1.144-20fdc64.run
# step 2: 然后 Enter 键,并翻页到最后,键入 ACCEPT 接受协议
# step 3: 输入安装路径,或者回车使用默认路径,完成安装。
Enter install path: [ default is /opt/nvidia/nsight-systems/2020.4.1 ]:
...
========================================
To uninstall the Nsight Systems 2020.4.1, please delete "/opt/nvidia/nsight-systems/2020.4.1"
Installation Complete
# step 4: 将安装路径加入PATH
$ export PATH=/opt/nvidia/nsight-systems/2020.4.1/bin:$PATH
$ which nsys
/opt/nvidia/nsight-systems/2020.4.1/bin/nsys
注:桌面可视化的客户端安装非常简单,和安装其他软件无差别。
1.3 基础用法
常用命令如下:
nsys profile -w true -t cuda,nvtx,osrt,cudnn,cublas -s cpu --cud -x true python abs.py
"""
–stats=true,表示在收集完信息后,会在终端输出本次profiling的统计概要。
-t cuda,用于指定待profiling的 API.可以设置为cublas, cuda, cudnn, nvtx, opengl, openacc, openmp, osrt, mpi, vulkan, none
"""
注:更多用法,可以参考:nsys文档。
命令执行完,会在当前路径下生成一个 *.qdrep文件,将其拖入 NSight GUI 工具即可。
2. 火焰图
2.1 yep 库
C++的性能分析工具非常多。常见的包括gprof, valgrind, google-perftools。但是调试Python中使用的动态链接库与直接调试原始二进制相比增加了很多复杂度。幸而Python的一个第三方库yep提供了方便的和google-perftools交互的方法。于是这里使用yep进行Python与C++混合代码的性能分析。
使用yep前需要安装google-perftools与yep包。ubuntu下安装命令为:
apt update
apt install libgoogle-perftools-dev
pip install yep
因为C++与Python不同,编译时可能会去掉调试信息,运行时也可能因为多线程产生混乱不可读的性能分析结果。为了生成更可读的性能分析结果,可以采取下面几点措施:
- 编译时指定
-g生成调试信息。使用cmake的话,可以将CMAKE_BUILD_TYPE指定为RelWithDebInfo - 编译时一定要开启优化。单纯的
Debug编译性能会和-O2或者-O3有非常大的差别。Debug模式下的性能测试是没有意义的 - 运行性能分析的时候,先从单线程开始,再开启多线程,进而多机。毕竟单线程调试更容易。可以设置
OMP_NUM_THREADS=1这个环境变量关闭openmp优化
2.2 pprof 命令
在运行完性能分析后,会生成性能分析结果文件。我们可以使用pprof来显示性能分析结果。注意,这里使用了用Go语言重构后的pprof,因为这个工具具有web服务界面,且展示效果更好。
首先,安装 GO 环境,以Linux为例:
# step 1: 下载较新的的 GO 安装文件
wget https://golang.org/dl/go1.16.4.linux-amd64.tar.gz
# step 2: 删除系统旧版的 go
rm -rf /usr/local/go
# step 3: 解压到 /usr/local 目录
tar -xzf go1.16.4.linux-amd64.tar.gz -C /usr/local
# step 4: 设置环境变量
export GOROOT=/usr/local/go
export PATH=/root/gopath/bin:$GOROOT/bin:$PATH
# step 5: 验证安装
go version
然后,安装 pprof 命令:
go get github.com/google/pprof
2.3 基础用法
生成日志文件:
python -m yep -- model.py --device=GPU ....
可以启动一个服务,查看火焰图:
pprof -http=0.0.0.0:8878 `which python` ./main.py.prof
二、模型性能分析
1. 日志生成
1.1 Profiler timeline
对于模型代码,需要在训练的 for 循环中,添加如下代码:
if iter == 100:
profiler.start_profiler("All", "OpDetail")
if iter == 110:
profiler.stop_profiler("total", "./profile")
return
其中
start_profiler的 trace_option 建议设置为 “Default“ 或 “OpDetail“ ,取10次迭代数据。
执行完之后,会在终端输出日志汇总结果,同时也会生成一个文件。该文件的路径为./profile

执行如下命令,可以生成 timeline 文件,方便在 chrom 浏览器中查看:
python Paddle/tools/timeline.py --profile_path=./profile --timeline_path=timeline
- 访问 chrome://tracing/
- 点击 load 按钮,加载 timeline文件
1.2 NSight timeline
在模型训练相关的 for 循环中,添加如下代码:
- 使用
nvprof_start()和core.nvprof_stop()控制profile的开始和结束 - 使用
core.nvprof_nvtx_push()和core.nvprof_nvtx_pop()添加要统计的特定event。在event开始前push event 的名称,在event结束后,进行 pop。 - 例如下面代码,使用迭代次数作为事件的名称。
for iter_id, data in enumerate(train_loader):
if iter_id == 100:
core.nvprof_start()
core.nvprof_enable_record_event()
core.nvprof_nvtx_push(str(iter_id))
if iter_id == 110:
core.nvprof_nvtx_pop()
core.nvprof_stop()
if iter_id > 100 and iter_id < 110:
core.nvprof_nvtx_pop()
core.nvprof_nvtx_push(str(iter_id))
执行如下命令生成 timeline 文件(参考:Paddle 30567):
nsys profile -o my_report -w true -t cuda,nvtx,osrt,cudnn,cublas -s cpu --capture-range=cudaProfilerApi --stop-on-range-end=true --cudabacktrace=true -x true -o my_profile python train.py
在可视化客户端中加载此文件,效果如下:
2. 性能分析
2.1 如何看profile report
Profile Report中可以重点关注OP的调用次数,CPU时间和GPU时间。
- 调用次数多的OP,很难从report中确定是否有优化空间,需要进一步结合timeline去发现是否有耗时异常的kernel。

- 调用次数少,但是时间上占比不低的OP,可能是需要优化的

- OP的CPU时间远远大于GPU时间,可能的原因一般有:
- 框架执行调度问题,比较难排查,需要通过添加更细致的event,以及结合timeline去排查
- OP运行过程中,引入了设备间的数据拷贝,在report中会直接打印出来。案例PR25810

- OP的Compute中某部分CPU耗时较多,可以通过在c++端添加event去确认
2.2 如何看timeline
2.2.1 认识模型的timeline构成
timeline展示了模型训练过程中各个事件在时间轴上情况,模型训练时每一个step经历的阶段都是具有规律的,比如下图中的动态图模型timeline大致具有以下阶段:
数据读取 →前向计算→反向计算→optimizer参数更新→ClearGradient

我们可以根据需要,通过nvprof_nvtx_push为一个step的不同阶段打上标记。
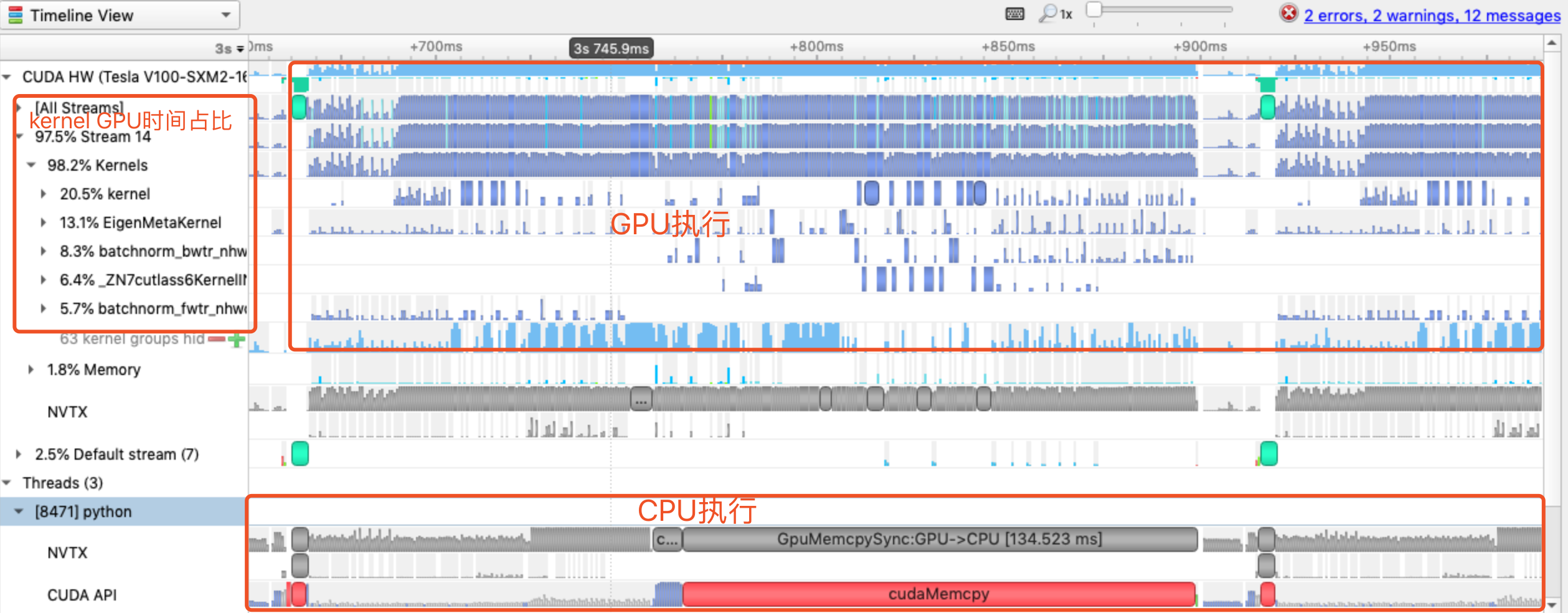
模型分析时,我们要关注timeline的哪些信息呢?
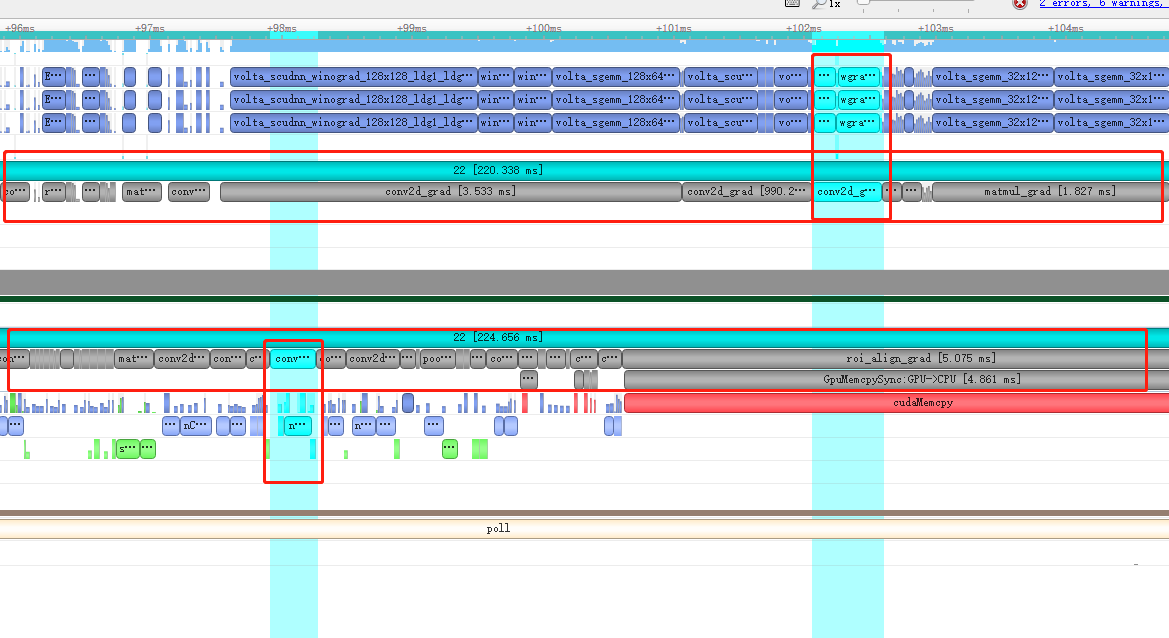
图中蓝色的矩形块显示了CUDA Kernel的执行,下面是CPU执行,左侧展示出了Kernel的GPU时间占比,可以结合这3部分确定模型的性能瓶颈。
2.2.2 timeline常见的问题表现
timeline的表现可能有以下4种:下图中上面一行表示CPU执行,下面一行表示GPU执行
- 理想场景:CPU和GPU资源都被充分利用
- 问题场景1:CPU计算较快,GPU事件较高,通过优化CUDA Kernel缩短GPU时间,就缩短了一次迭代的耗时
- 问题场景2:CPU计算较慢,GPU出现等待,timeline上会发现GPU Kernel之间有大段空白
- 问题场景3:存在wait,比如上文中提到的设备间的数据拷贝等,需要等待GPU执行完,CPU才能开始执行
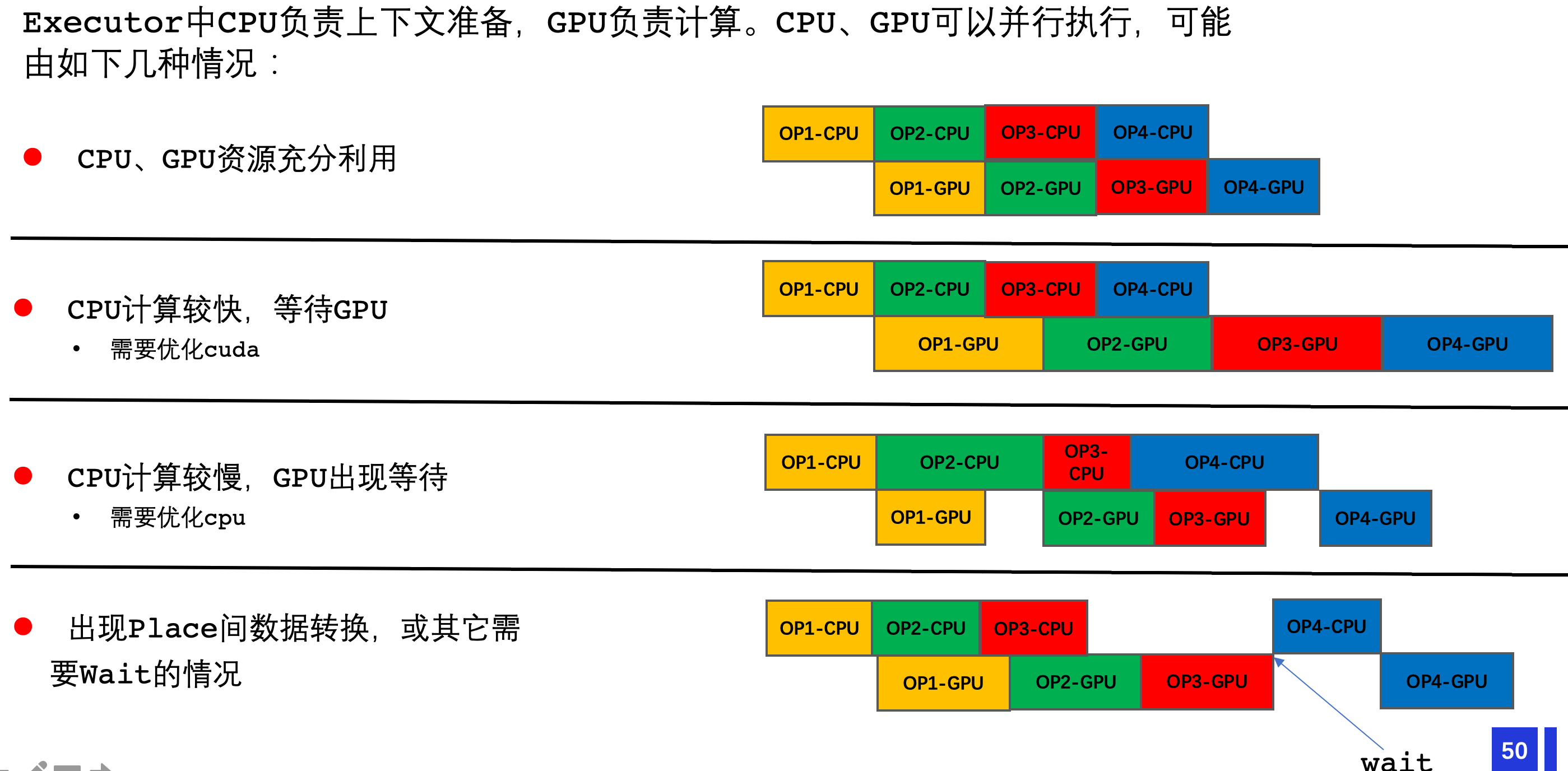
模型中可能是多种问题的混合。
2.3 如何发现性能瓶颈
前面提到的Profile Report可以给我们相对宏观的统计信息,要定位具体的性能瓶颈,常常还需要结合timeline的表现。通常可以按照以下技巧:
- 确认reader耗时的占比:两个step之间的间隔如果较大, 可能是reader的耗时比较大。Paddle使用DataLoader加载数据,该API的
num_workers>0时,使用多进程方式异步加载数据。如果发现两个step间隔较大,可尝试调大这个参数。 - 查看占比高的Kernel,如果耗时异常,这类kernel需要优化:
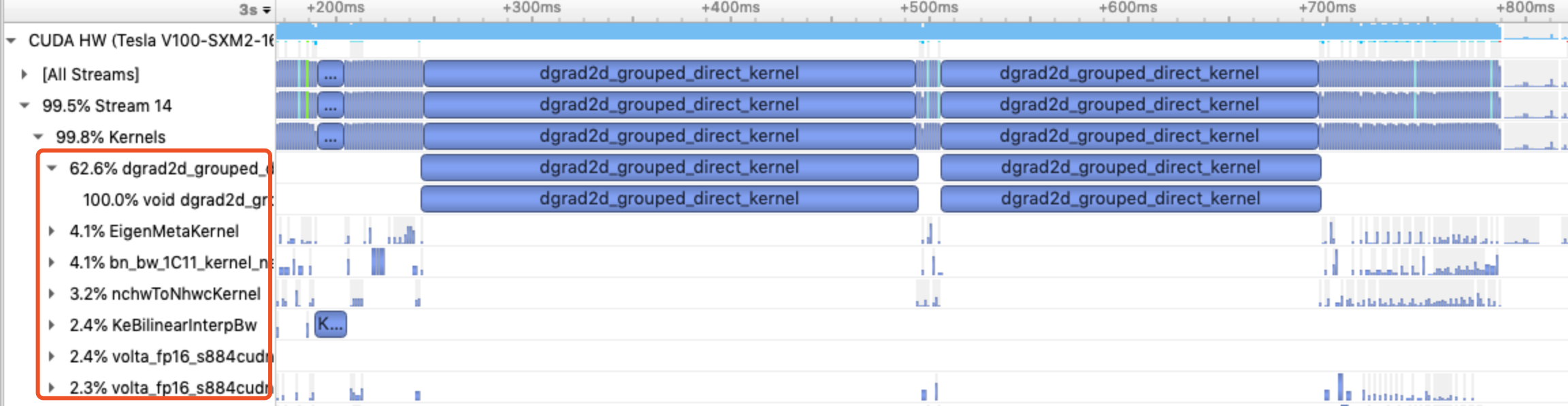
- 占比高,耗时异常:下图中drad2d_grouped_direct_kernel占比高达62.6%,实际上这是conv_grad中调用的cuDNN的kernel。conv在CV模型中调用次数非常高,我们通过对比会发现这个kernel的执行时间远远高于其他conv_grad。
- 占比高,耗时无明显异常,:batch_norm占比排第3,但是如果放大timeline去看,其实kernel的耗时并没有特别异常的。

- 占比高,耗时异常:下图中drad2d_grouped_direct_kernel占比高达62.6%,实际上这是conv_grad中调用的cuDNN的kernel。conv在CV模型中调用次数非常高,我们通过对比会发现这个kernel的执行时间远远高于其他conv_grad。
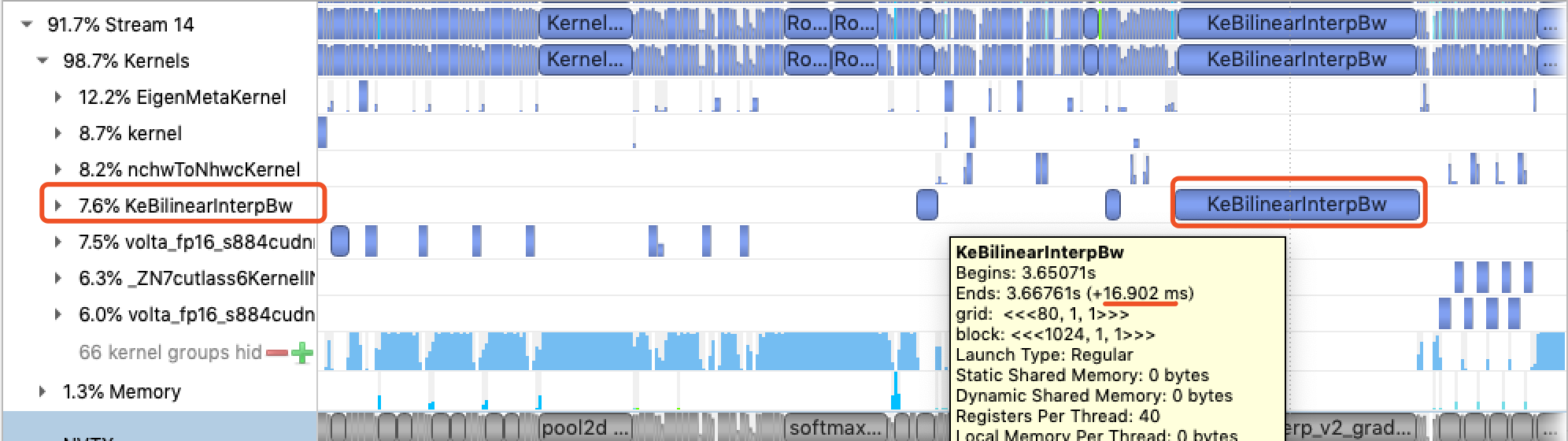
- 有些Kernel在特定的API配置下计算很慢,需要优化:例如下图中,占比7.6%的kernel,1个step调用了3次,但是其中最后一次耗时16 ms,而另外2个大概是几百us。这意味着,如果找出这个耗时异常的配置,对Kernel进行优化,模型的性能就会有比较明显的提升。
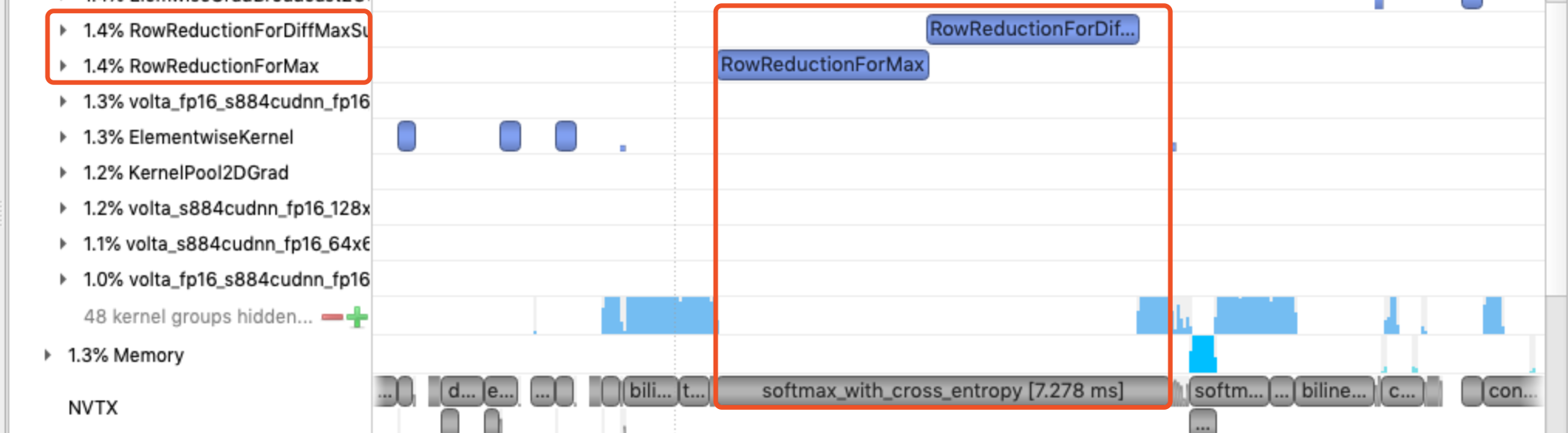
- 不要忽略单个占比并不高的kernel:下图中有两个占比分别为1.4%的kernel。结合右侧timeline,会发现这2个kernel在1个step中都分别调用了1次,是在softmax_with_cross_entropy op里调用的,这个OP的GPU时间需要将这些kernel统计进去。
- timeline上的空白:如果空白占比非常高,优化后会有比较明显的收益。
- 静态图模型:如果kernel之间有较大空白,一般可以认为是框架开销。在一个GPU Kernel执行之前,框架会完成内存分配、组建ExecutionContext,InferShape,prepare data(可能存在设备间的数据拷贝),launch kernel。这些都是CPU时间,如果这段时间较长,那当前的这个kernel和上一个GPU Kernel之间可能就存在空白。
- 动态图模型:还会受python端code的影响,当发现timeline上存在空白,需要结合python code去排查。
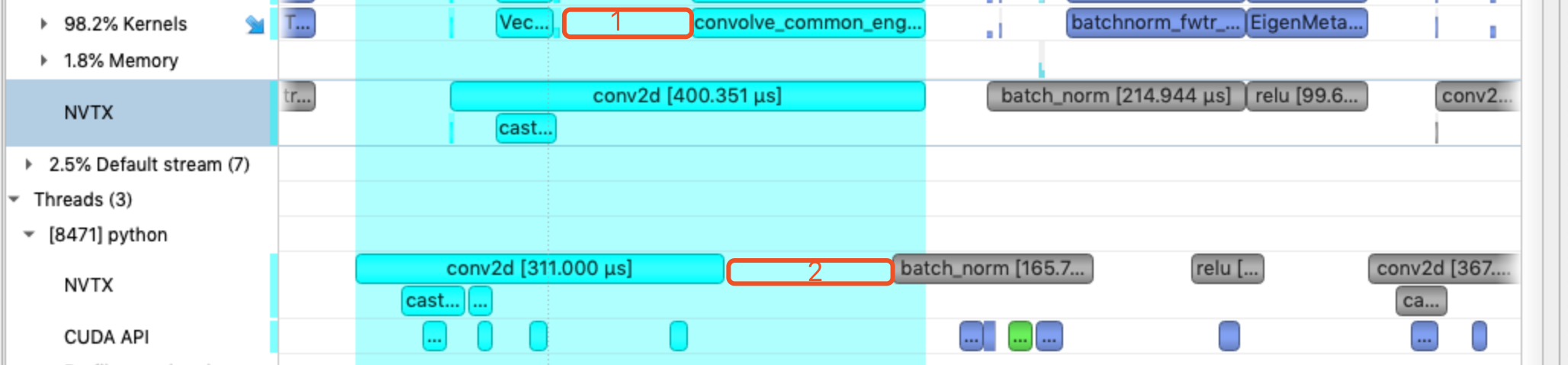
- 一个例子:下图是一个动态图的timeline,最下面是CPU事件,可以看到记录的OP和OP之间都有空白,比如空白标记2。由于我们的profile是从c++端op run开始标记,在2个OP run之间,python端的开销,或者框架上其他的开销,都未被记录在timeline上。框架开销通常也比较难优化,但可以通过简单的方法排查是否有相对异常的?如果浏览timeline,发现CPU执行的部分,某个空白远大于其他的空白,可以优先排查下是不是python API的code造成了较大开销。对于空白1,它发生在conv2d这个OP中的2个GPU Kernel之间,如果要确认,可以优先在OP的compute中,添加一些event去看看哪段代码造成了这段空白。
2.4 其他问题
-
如何评估一个优化点的性能收益
- 确定一个step的平均时间,通常可以看模型的log中的batch_cost
- 确定这项优化工作预期能将开销降低到多少,比如优化OP时我们可以通过对比竞品,大概知道这个OP的耗时能降低多少,估计出优化后的batch_cost,算出性能收益
-
当timeline上发现某个kernel耗时严重,如何确认它的配置是什么?
- 收集模型中该OP的所有配置,用op-benchmark跑一遍,找出耗时异常的OP。但收集过程会相对麻烦,目前动态图只能通过打印log。
- 通过timeline分析OP在模型中的大概位置,然后结合模型的结构图,或者python代码,定位到这个配置。【举个栗子 pool2d】
-
有一些OP占比高,就只能通过优化CUDA Kernel吗?
- 不一定,例如混合精度训练中,常常出现,某个OP不支持float16类型,导致频繁的cast。假设OP2支持float32类型计算,其他OP都是float16算,那么混合精度训练中,将会像下面第2行类似,插入了较多的cast。
- 明确原因后,我们可以对OP2支持float16类型,那么就能去除掉这些cast。
OP1 -> OP2 -> OP3 -> OP4 -> OP2 -> OP5OP1 -> cast_to_float32 -> OP2 -> cast_to_float16 -> OP3 -> OP4 -> cast_to_float32 -> OP2 -> cast_to_float16 -> OP5
- 竞品Torch的profile教程
- 执行命令:
nsys profile -w true -t cuda,nvtx,osrt,cudnn,cublas -s cpu --capture-range=cudaProfilerApi --**stop**-**on**-range-**end**=true --cudabacktrace=true -x true -o my_profile python main.py
- 执行命令:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号