【源码研读】MLIR Dialect 分层设计
以「疑问 - 求解」的形式来组织调研,此处记录整个过程。
1. MLIR 中的 Dialect 是「分层」设计的么?
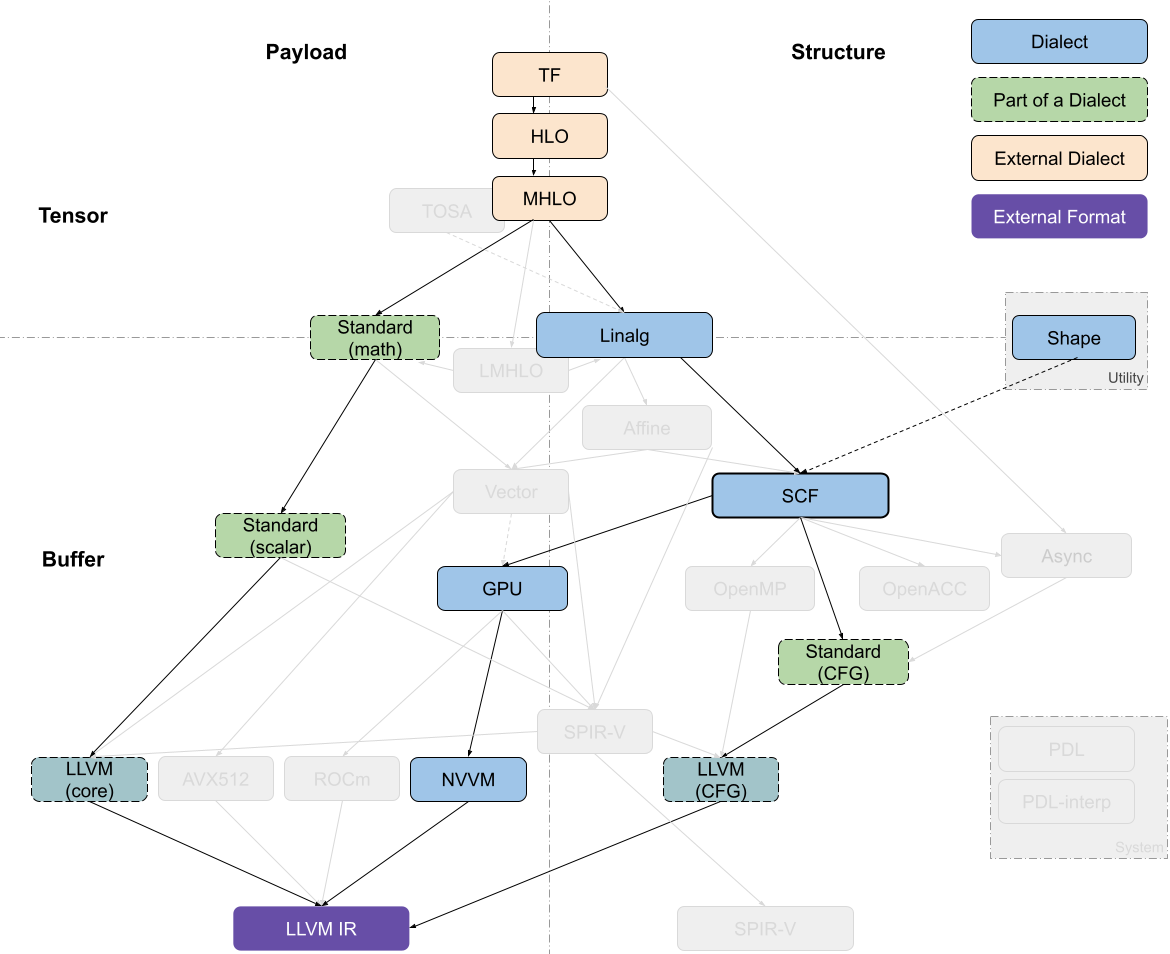
先问是不是,再谈为什么。从 LLVM 社区 可以看出,至少在做 Codegen 时,是采用了「分层」的思想来逐步 Lowering 的(具体见下图)。MLIR 为编译优化而生,分层 Lowering 是比较符合设计直觉的,在多硬件、多场景的 Dialect 扩展性上具有天然优势。
在 MLIR 的设计初衷里,「扩展性」是非常强烈的需求考量,要能够纵向支撑用户不同的场景,也要横向支撑不同硬件接入进来,低成本地编译优化。如此,MLIR 社区才有可能做大做强。
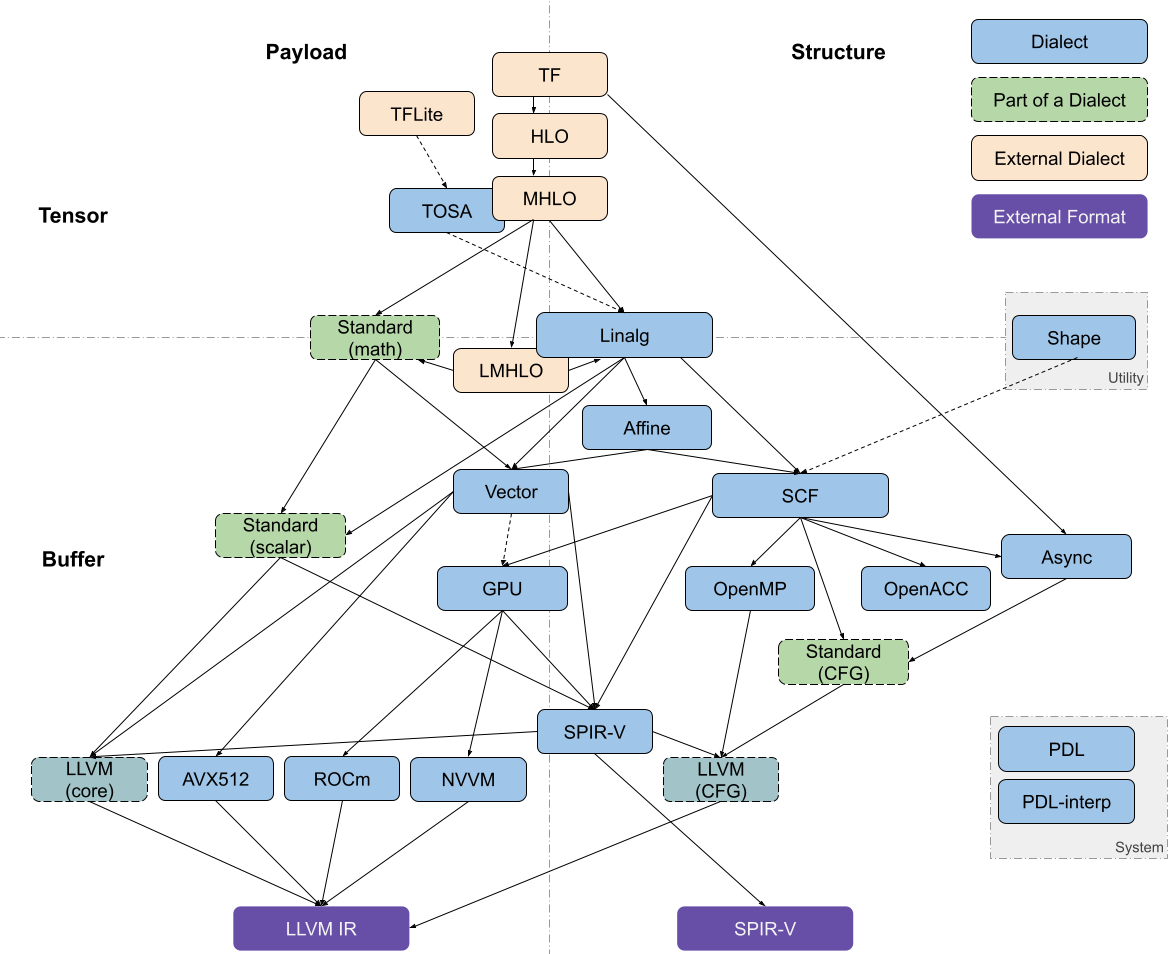
另外,在 MLIR 核心开发者 ZhangLei 的技术博客里,也提到了 MLIR 的宏观图景,原文表述如下:
从类型的角度,恰当分层的软件栈需要支持对张量、buffer、向量、标量等进行建模以及一步步分解和递降(即 Lowering)。 从操作的角度,我们需要计算和控制流。控制流可以是显式的基础块跳转,也可以内含于结构化操作之中。
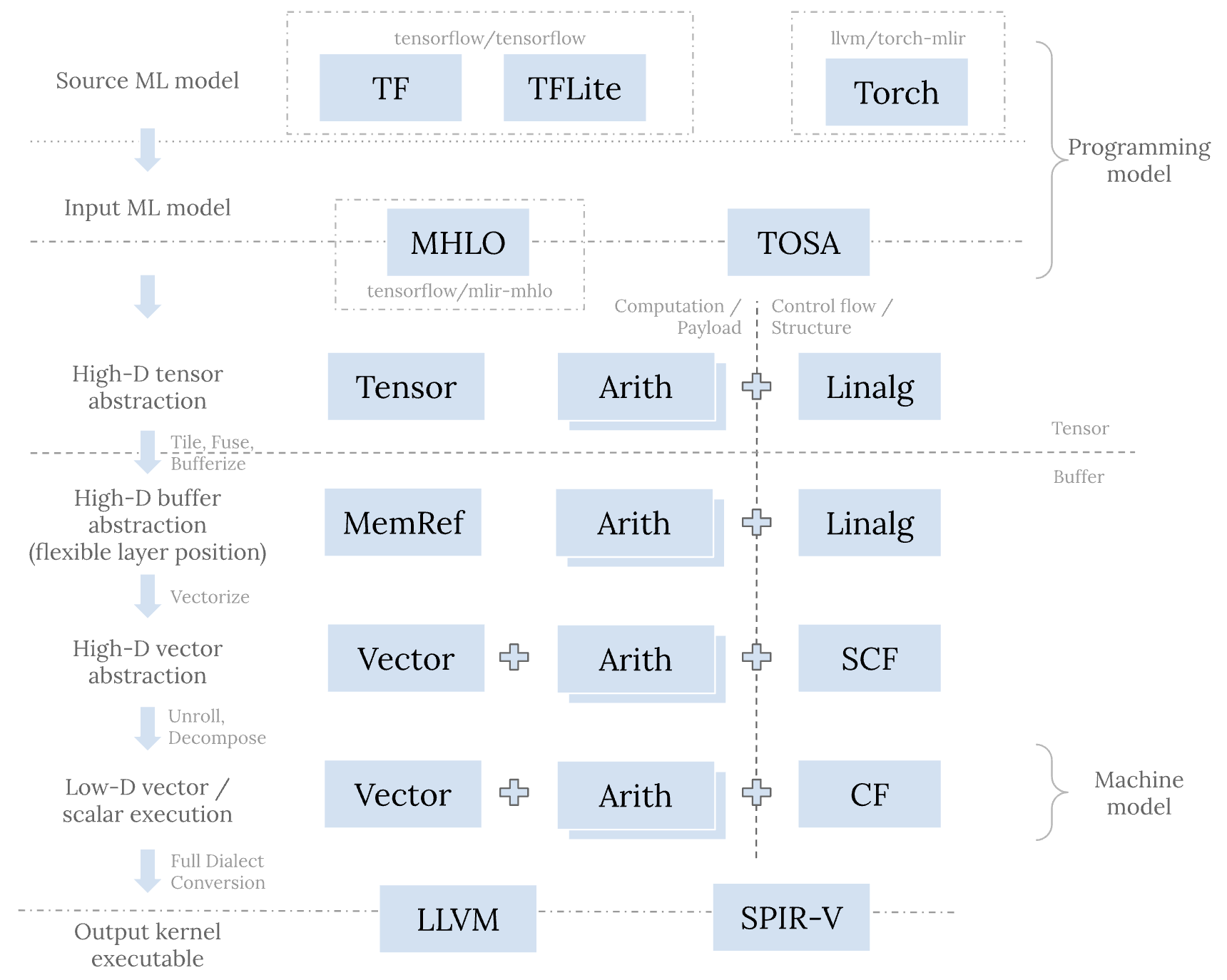
从上图来对比飞桨现有的新 IR 体系设计,以及考虑未来新增的「分层」Dialect:
- TF、TFLite 层对应于新 IR 体系中的 PaddleDialect ? 即组网编译期高层表示(与主框架耦合紧密,放到 paddle 目录下)
- MHLO、TOSA 层面是为了「屏蔽非常多的框架」信息,起到「沙漏」的作用,以形成某种协调的「规范」(个人理解类似ONNX角色,是第一层屏蔽的协议)
也对应于PaddleDialect,但仅对应于「规范的」Type和Operation子集。对于飞桨而言,其实应该要考虑规范化这一层,而不是仅仅满足于支持自己的框架 - 中间层 Dialect 设计的优势在于:「独立且灵活」。
- 原文描述: 高层和低层的 dialect 通常处于 MLIR 系统的边界,所以需要准确地描述某一 MLIR 之外的标的。 中间层的 dialect 则没有这样的限制,所以中间层的 dialect 具有更大的设计空间以及更高的设计灵活性。传统的中间表示,如 LLVM IR 或者 SPIR-V,通常都是完整 (complete) 的; 它们包含所需的所有指令来表示整个 CPU 后者 GPU 程序。相较而言,中间层的 dialect 则可以认为是部分 (partial) 中间表示。 这种组织结构有助于解耦 (decoupling) 和可组合性—我们可以通过混用这一层的不同 dialect 来表示原始模型,同时不同 dialect 可以独立发展演进。 这些dialect 有的用来表示计算或者负载 (payload),有的则表示控制流或者某种结构 (structure)。
- linalg dialect 是用以表示结构的重要 dialect 之一,linalg dialect 的文档中还有许多其他不错的设计考虑值得一读(TODO)
- 分为两大类:generic op和named op
- 其 op 既可以操作 Tensor,也可以操作 buffer,两者分别对应于 MLIR 中的 tensor and memref 类型。 两者皆是高维的抽象,并都可以支持 dynamic shape。
- MHLO、TOSA Dialect 可以转换为 linalg Dialect,这种转换会保持在张量这一抽象层级,所以其目的并非递降,而是为接下来的转换做准备。
- 从文档里给出的代码来看,linalg 更像是为编译器而生的,比较类似CINN的Lowering,但作者明确说了,这一层并未 Lowering?
**初步结论:*8 无论是从 Type 体系的宏观图景,还是 Codegen 时的流程,都能捕捉到 MLIR 在设计上有「分层设计」的思想。
2. 从TF、Torch、LLVM 源码中来看,各个 Dialect 的组织形式是什么样子的?
2.1 TF 中的 Dialect
从上述仓库的首页介绍来看,mlir-hlo 有两个托管地址:
- TF 主仓库:
tensorflow/compiler/xla/mlir_hlo,援引的mlir_hlo 独立仓库,随 TF 编包 - 独立仓库:
https://github.com/tensorflow/mlir-hlo,为了方便开发者不依赖 TF 庞大的包
子问题:mlir-hlo 是什么?TF 已经有 XLA+HLO,为什么还要孵化 mlir-hlo 呢?
以下是参阅了官网资料后的一些「依据」收集,和粗浅的理解。
① 用于 XLA 风格编译的 MLIR 方言
其定义了三种方言来支持使用 MLIR 的类似 HLO 的Compile pipline:
- chlo:“客户端”HLO 方言,旨在更接近前端(包括隐式广播语义)。
- mhlo:“元”-HLO 方言;与 类似xla_hlo,但具有动态形状支持的扩展。(是基于 Tensor 层面)
- lmhlo:“late”-“meta”-HLO,是执行缓冲区(即 buffer)分配后的IR。在 XLA 中,缓冲区分配是一个辅助数据结构,用于跟踪这些信息,而这种单独的方言在 IR 中将其具体化。(是基于Buffer层面的)
个人理解,基本流程是:hlo → chlo → mhlo → Linalg → bufferization → lmhlo
从代码目录组织上,也能看出 mhlo、lhlo、thlo(这是啥?)
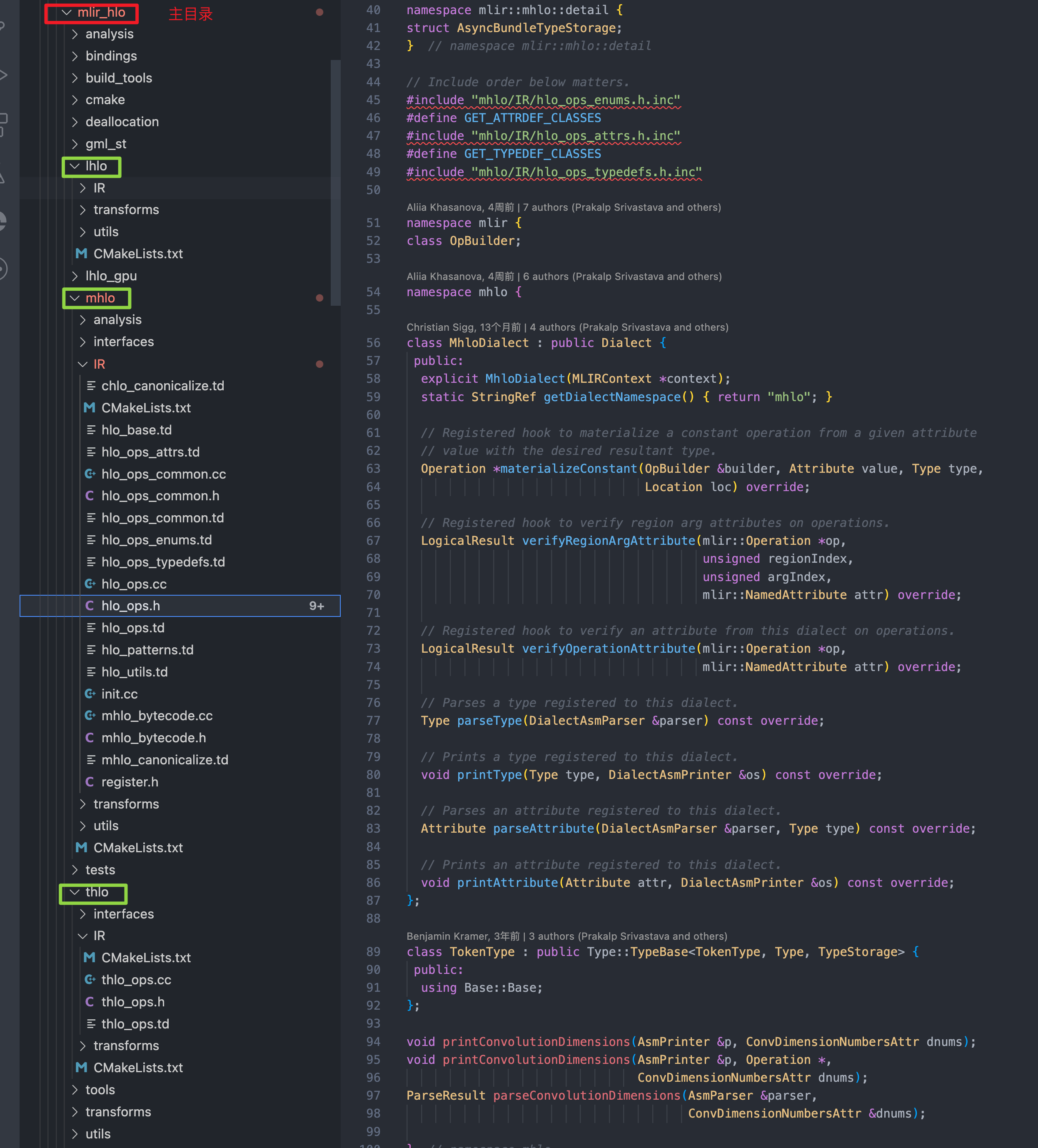
以 mhlo 目录中的 CMakeLists.txt 和 hlo_ops.h/.cc 为例,评估 MHLODialect 的编译依赖。
- Dialect 定义中的头文件依赖比较清晰,均为 LLVM 和 mlir 底层目录的依赖
CMakeLists.txt中也没有明显发现对于 TF 主框架数据结构的依赖(可能跟 mlir-hlo 独立仓库有关系)
其他的一些疑问待求解:
- 除了 lhlo,还有单独的一个 lhlo_gpu 目录,定义了
LmhloGpuDialect方言,这个是做什么的?
2.2 Torch 中的 Dialect
目前 torch-mlir 是放在 llvm 组织下的,但尚未正式化到 llvm project 里,也是一个「中间代理人」的角色,支撑Pytorch、JAX 模型能够借助此模块流畅地接入到 MLIR 体系下,然后复用 MLIR 的多硬件编译器优化的能力。
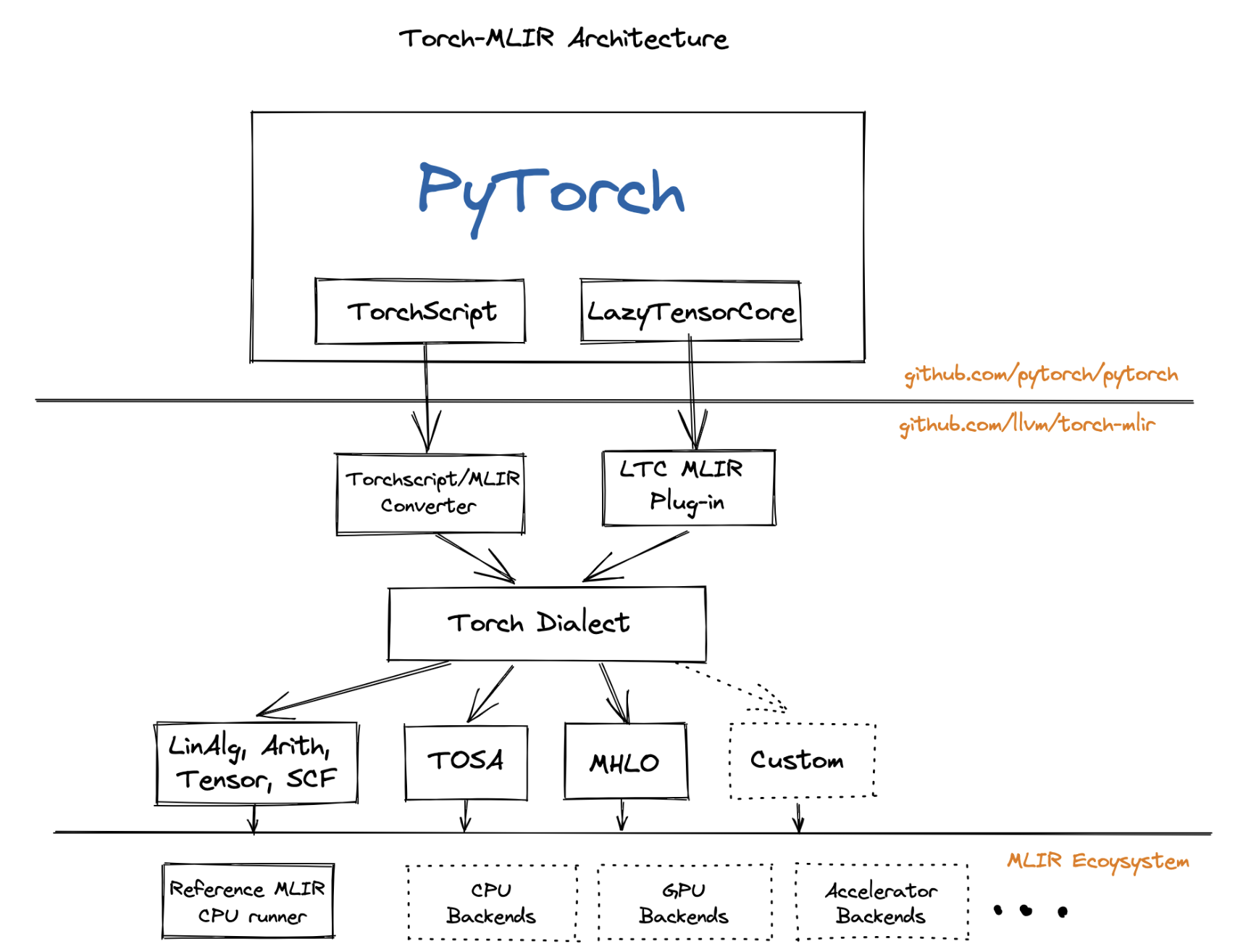
从目录结构上,Dialect 下只有两个目录,分别是 Torch 和TorchConversion:
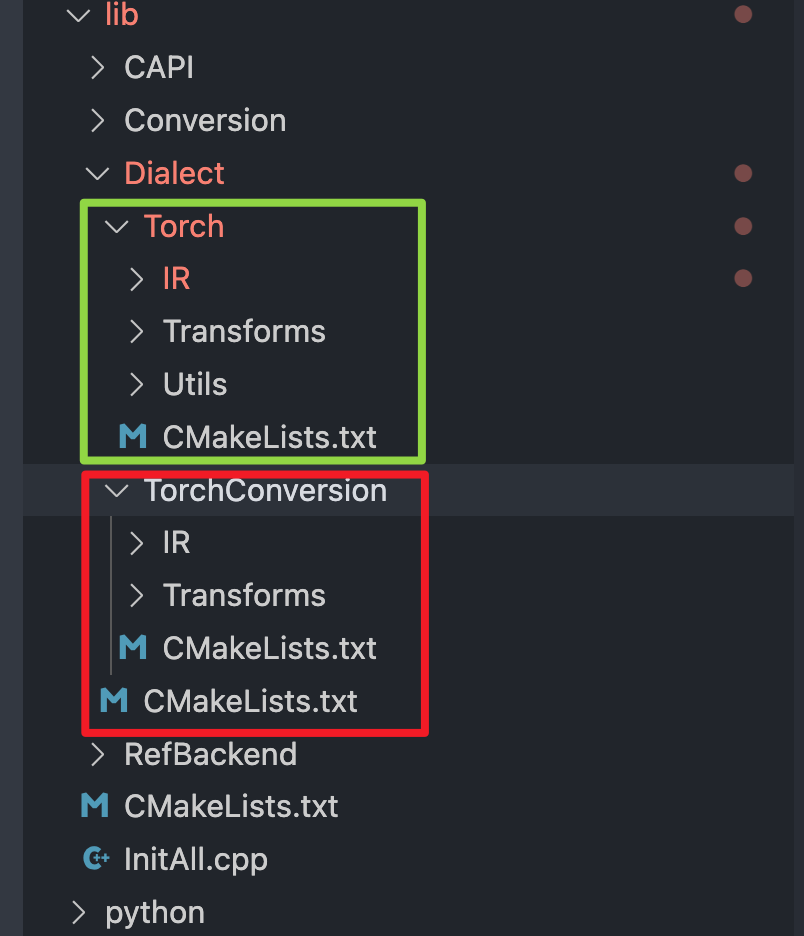
对于 Torch Dialect,从TorchOps.td可以看出其Operation的定义与 TorchScript 有者千丝万缕的联系,其中定义了如下核心的 Operation:
- NnModuleOp,NnModuleTerminatorOp、SlotOp:表示 torch.nn.Module
- ClassTypeOp,ClassTypeTerminatorOp:用于辅助建模 torch.nn.Module
- MethodOp,AttrOp,GlobalSlotOp,GlobalSlotModuleInitializerOp,GlobalSlotGetOp,GlobalSlotSetOp
- PrimListUnpackOp,PrimTupleConstructOp,PrimCreateObjectOp,PrimGetAttrOp等
- PrimLoopOp,PrimLoopConditionOp,PrimIfOp,PrimIfYieldOp
- PrimLoadOp,PrimEnterOp,PrimExitOp
- ConstantStrOp,ConstantDeviceOp,ConstantIntOp,ConstantNumberOp
- DerefineOp,OperatorOp,LinearParamsCreateOp, ValueTensorLiteralOp,CopyToValueTensorOp
- OverwriteTensorContentsOp,PromoteDtypesOp
- ShapeCalculateOp,ShapeCalculateYieldOp,ShapeCalculateYieldShapesOp
- DtypeCalculateOp,DtypeCalculateYieldOp,DtypeCalculateYieldDtypesOp
举一个栗子,熟悉 TorchScript 的同学也许能很快地理解为什么需要上面这些 Operation 的定义:
// 用于理解 NnModuleOp,SlotOp的作用
%2 = torch.nn_module {
torch.slot "b", %bool_true : !torch.bool
torch.slot "i", %int3 : !torch.int
torch.slot "f", %float : !torch.float
torch.slot "t", %t : !torch.tensor
torch.slot "submodule", %1 : !torch.nn.Module
} : !torch.nn.Module<"my_class_name">
// 用于理解 ClassTypeOp 的作用
// A simple empty torch.class_type, with corresponding torch.nn_module.
torch.class_type @empty {}
%submodule = torch.nn_module {} : !torch.nn.Module<"empty">
// A class type with many members.
torch.class_type @test {
torch.attr "b" : !torch.bool
torch.attr "i" : !torch.int
torch.attr "f" : !torch.float
torch.attr "t" : !torch.tensor
torch.attr "submodule" : !torch.nn.Module<"empty">
torch.method "method", @f
}
torch.nn_module {
// These must match the order and names in the `torch.class_type`.
torch.slot "b", %bool_true : !torch.bool
torch.slot "i", %int3 : !torch.int
torch.slot "f", %float : !torch.float
torch.slot "t", %t : !torch.tensor
torch.slot "submodule", %submodule : !torch.nn.Module<"empty">
} : !torch.nn.Module<"test">
也许从「问题空间」的角度也更好理解:如何解决用户持有 TorchScript 得到的模型表示后的 MLIR 转换问题,需要如何定义一个「算子集合」来承接表示 TorchScript 中的每个「操作」Operation?
另外,Torch Dialect 下 Transforms目录下定义了非常多的「转换」规则:
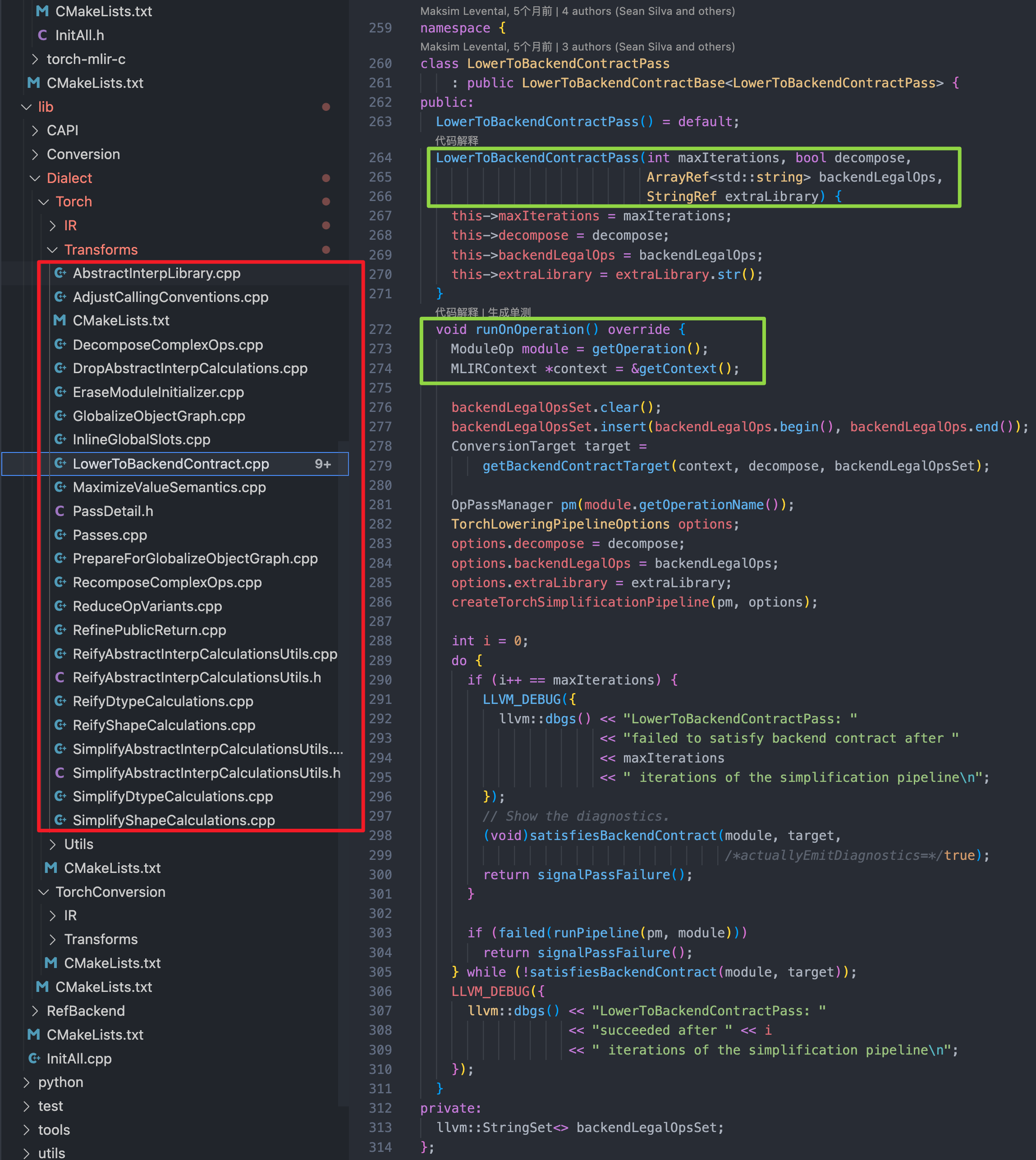
此时,我们再看 TorchConversion Dialect 目录下的源码,和其定位,如下是 TorchConversionBase.td 里描述。可以看出这是一个「转换相关」的Dialect。
- 这里似乎与 TF MHLO 不同。在 MHLO 里每层的 Dialect 定义是有明确的「表示含义」的,所有的「转换」操作是放在
transforms里的 - 而 Torch 的 Transforms目录放的是 Pass(也与转换有关系),但这里却单独定义了一个「转换」相关的 Dialect (有点费解)
def TorchConversion_Dialect : Dialect {
// `torch_conversion` is too verbose.
let name = "torch_c";
let cppNamespace = "::mlir::torch::TorchConversion";
let description = [{
This dialect contains ops and transforms for converting from the Torch
backend contract to the linalg-on-tensors backend contract.
This mainly consists of converting ops and types from `torch` dialect
to the mix of dialects of the linalg-on-tensors backend contract, such as
tensor ops being converted linalg-on-tensors and `!torch.vtensor` being
converted to the builtin `tensor` type.
}];
let hasConstantMaterializer = 1;
}
在 TorchConversionOps.td 里定义了转换 Dialect 相关的Ops:
- ToBuiltinTensorOp:用于 !torch.vtensor→ tensor
- FromBuiltinTensorOp:用于 tensor→ !torch.vtensor
- ToI1Op:用于!torch.bool→ i1
- FromI1Op:用于i1→ !torch.bool
- TorchConversionWithSideEffect_Op:用于处理 side effect(这个不是「过程式」吗?)
2.3 LLVM 中的 Dialect
有别于TF、Torch 深度学习框架独特的领域特性,LLVM 中 mlir 的众多 Dialect 的分层更加清晰,目前有至少 38 个 Dialect 目录。
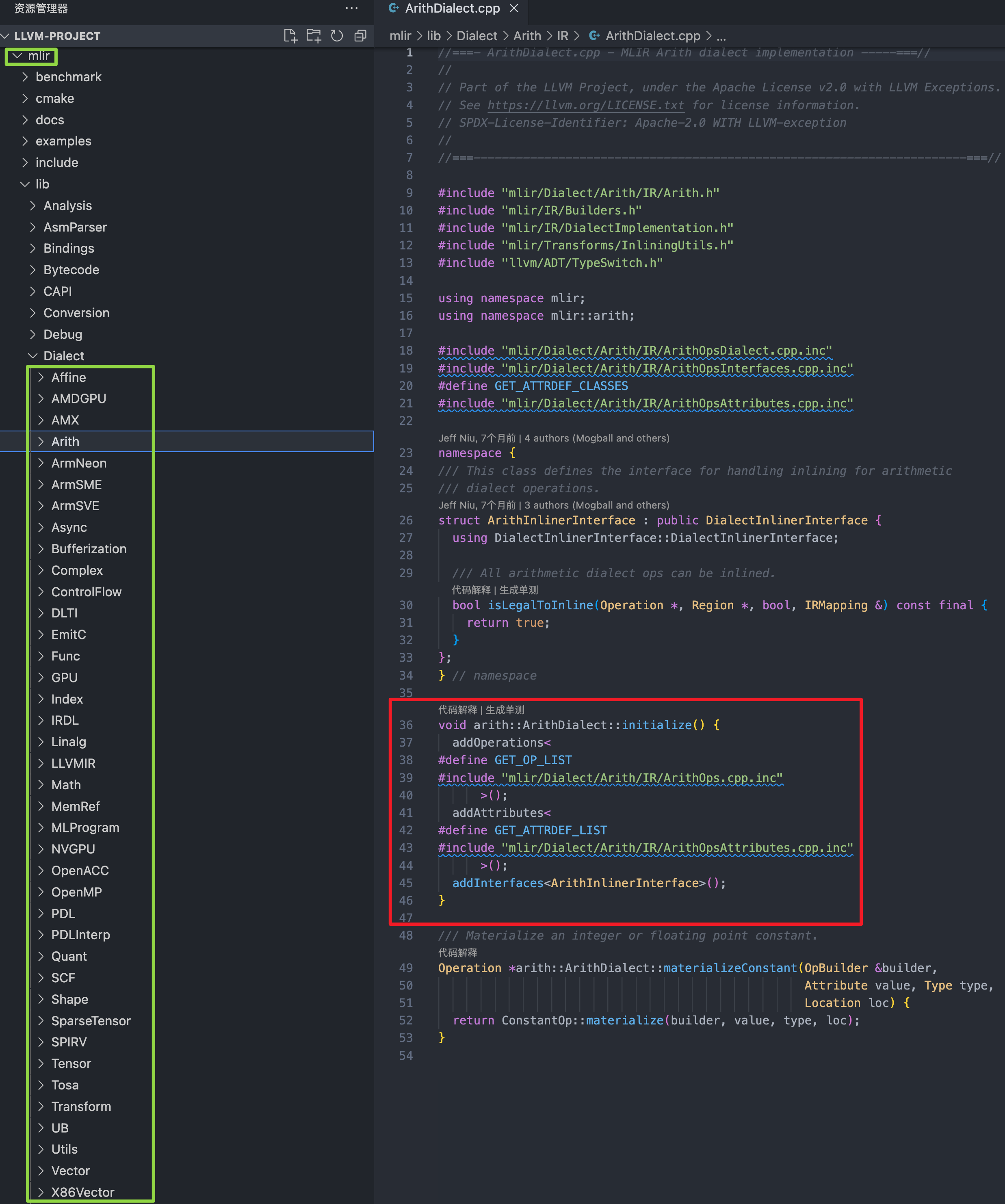
除了上述的目录外,还有一个「基石」作用的目录:mlir/lib/IR,其与 Dialect 总目录是平级关系,里面定义了 IR 核心基础的数据结构(有趣的是,Shape Dialect 并未在此目录下)
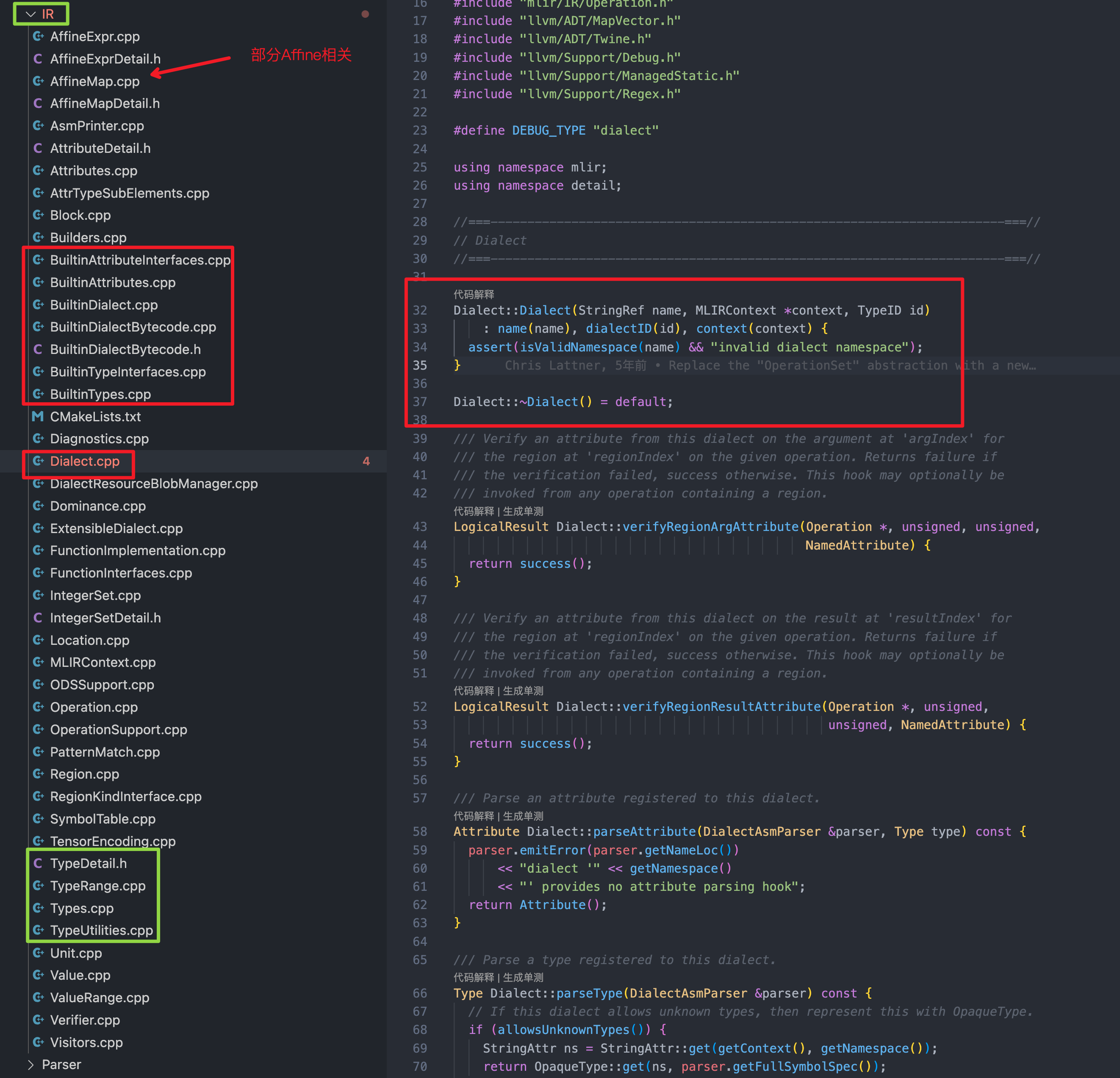
我们把视角拔高,总览全景看下在LLVM 中与上述 IR、Dialect 平级别还有哪些目录,会有助于我们理解 LLVM mlir 的组织形式。

3.不同 Dialect 之间的转换是怎么做的?
3.1 TF 的 mlir_hlo
首先是 TF XLA 中的 HLO → LHLO Dialect 的转换。在 lhlo/transforms 目录里有二者之间的算子映射关系:
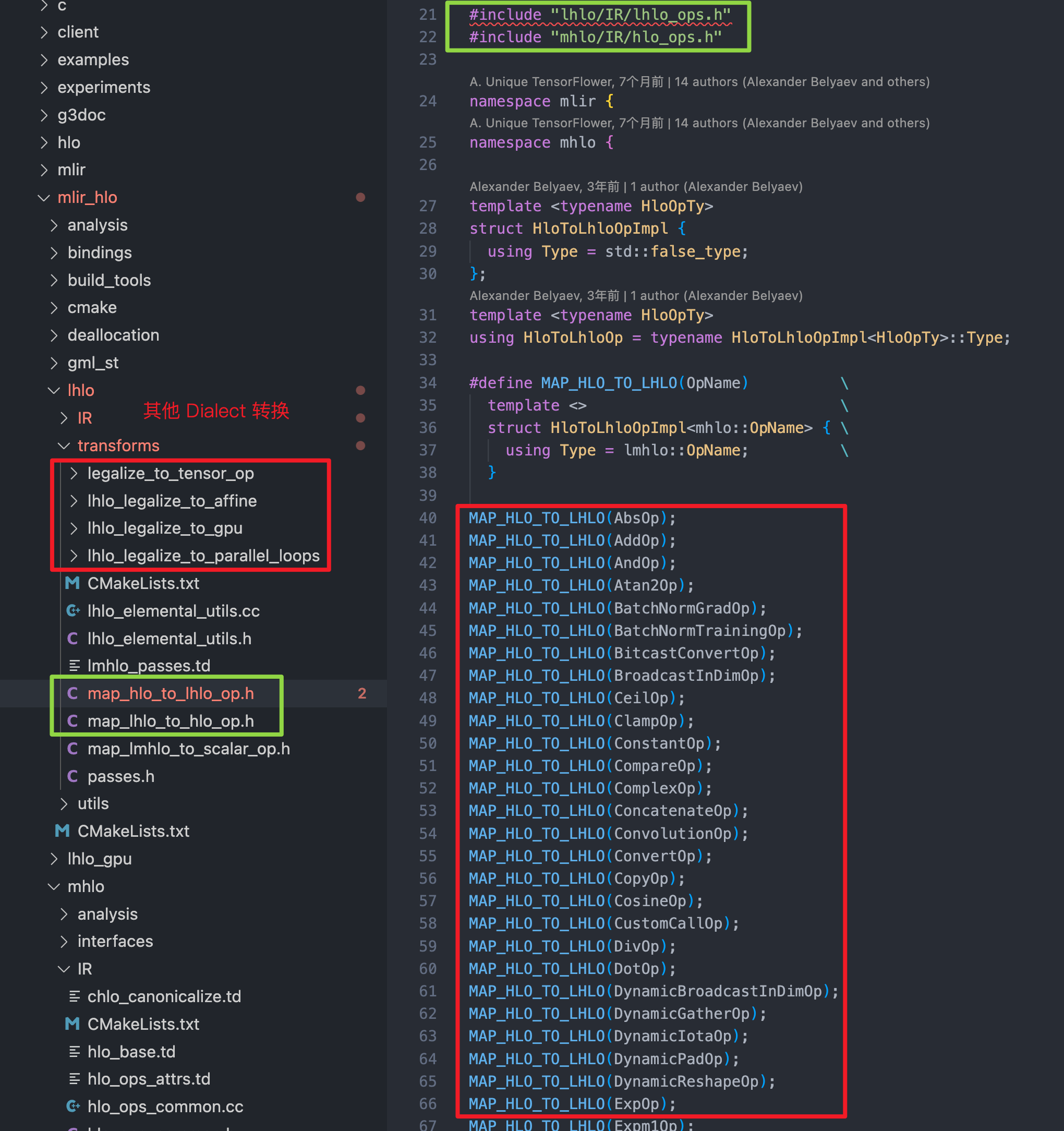
上图中对于 lhlo 到 gpu、affine等其他 Dialect 方言的转换是通过 pass 来实现的:
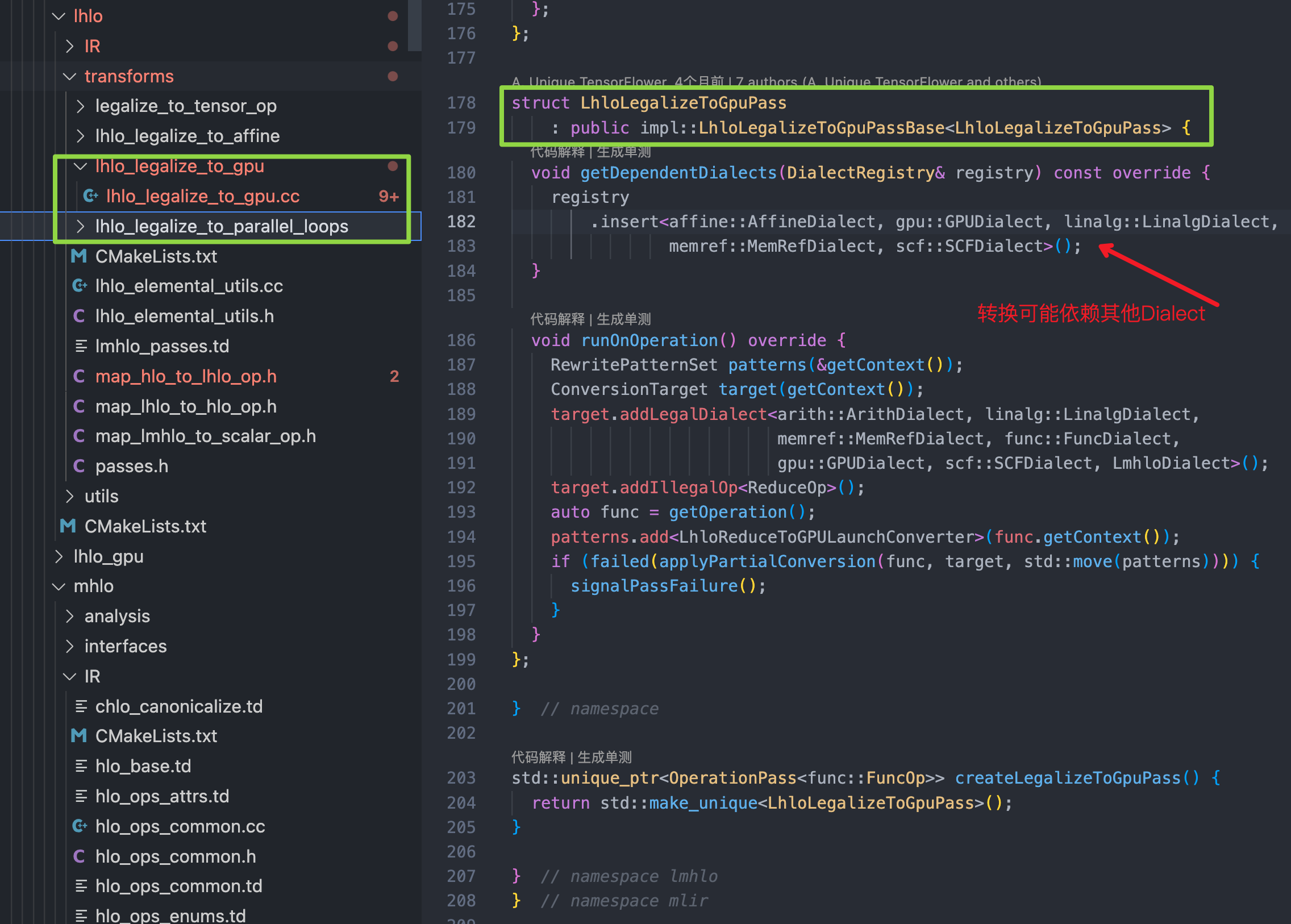
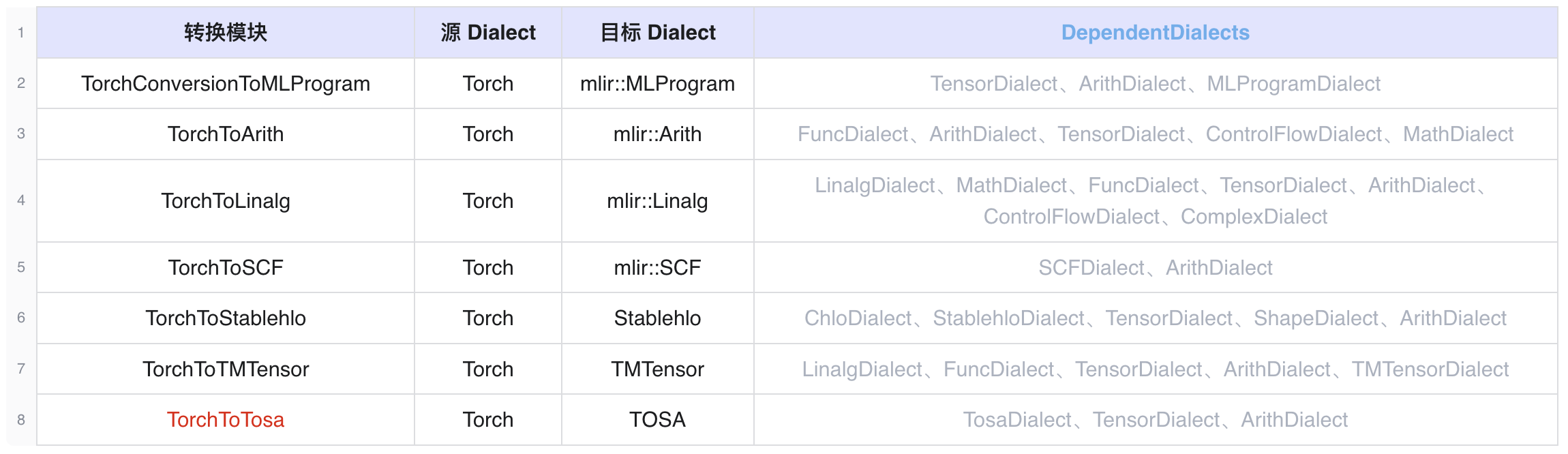
3.2 torch-mlir
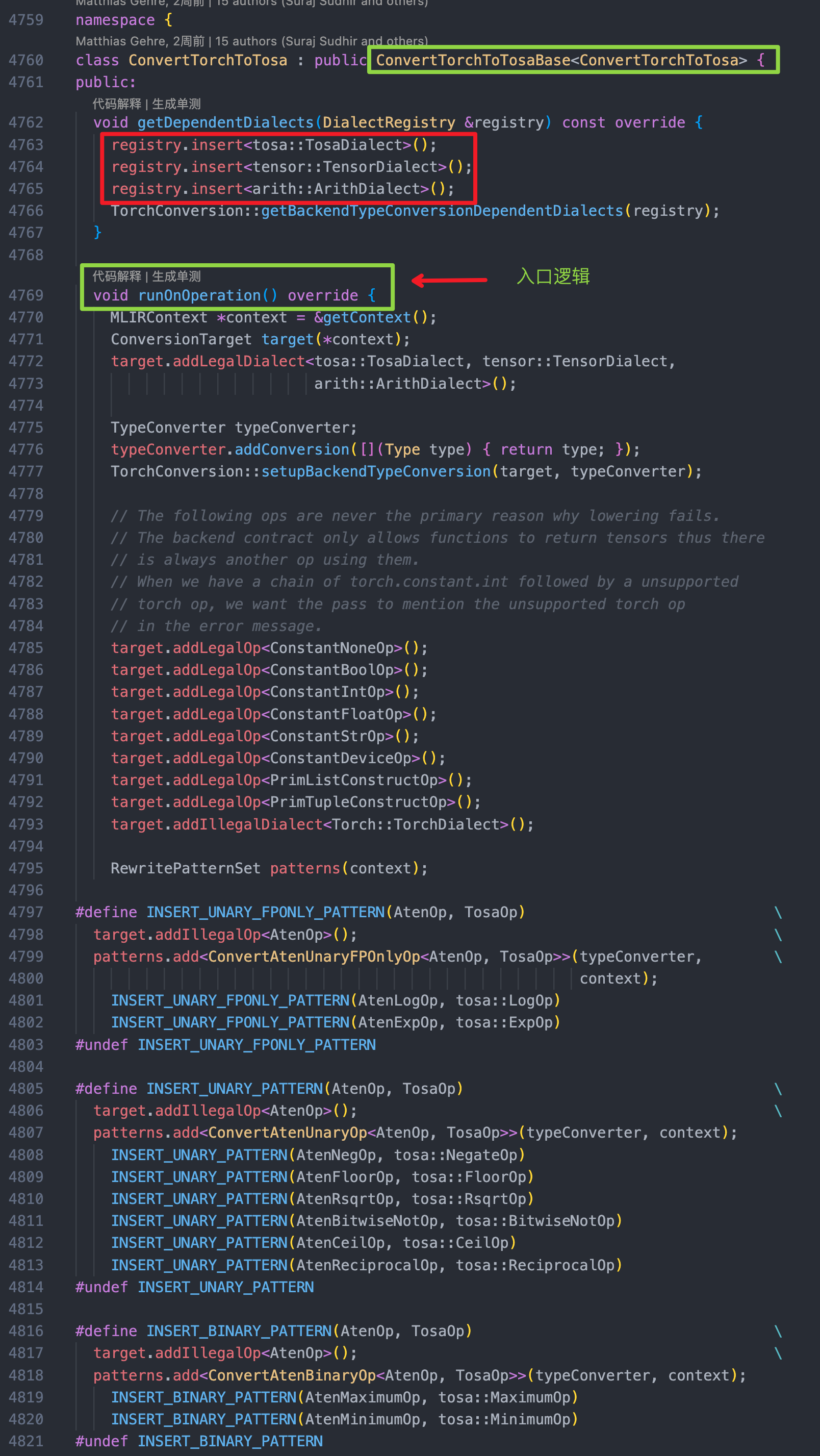
在 lib/Conversion 目录下目前包括了如下若干不同 Dialect 之间的转换 Pass。没错,是通过继承类似 ConvertTorchToTosaBase 的Pass 来实现的。
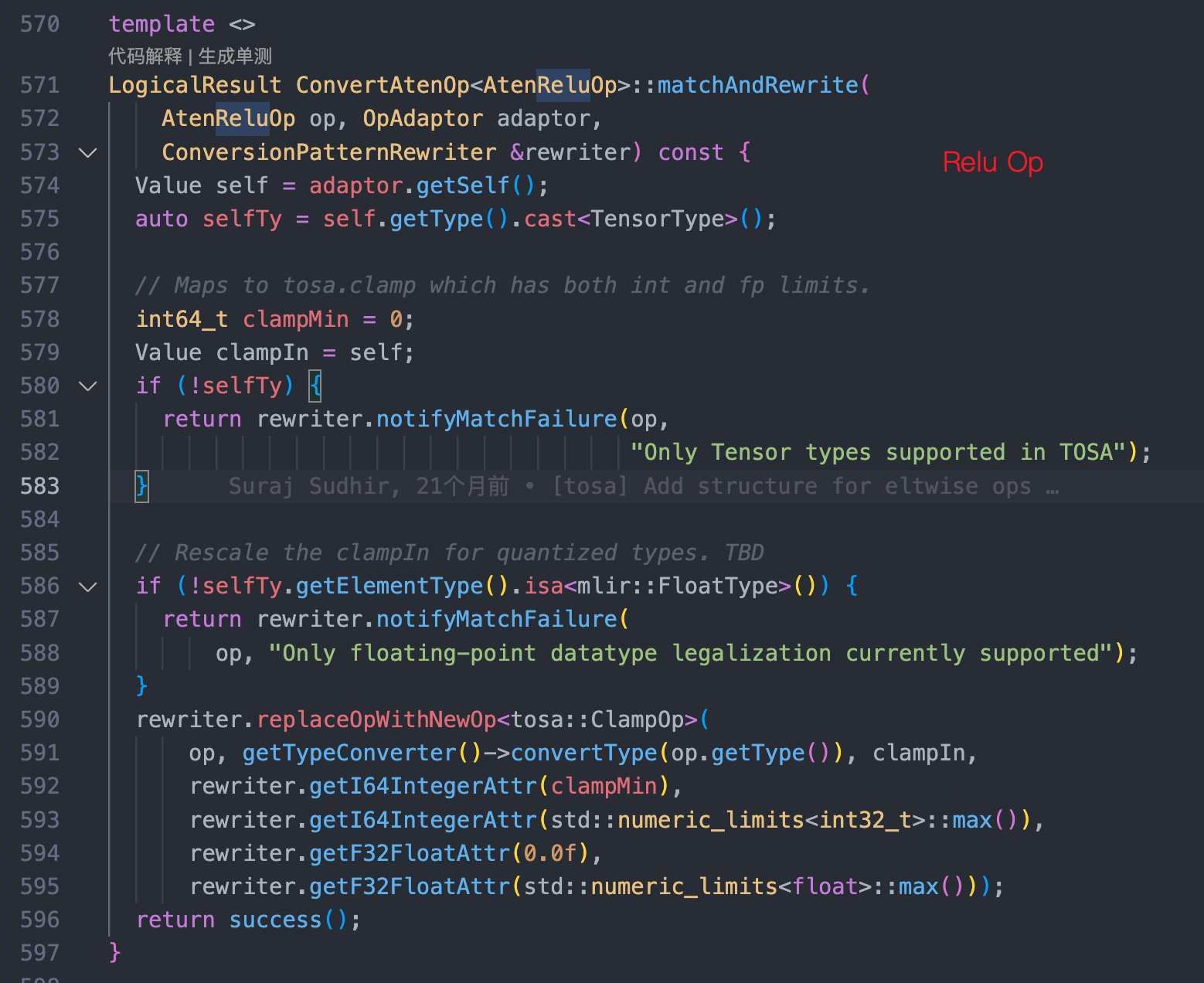
以TorchToTosa 为例,在其实现的 cpp 文件里有超过4500 行的 Torch → TOSA 的 Operation 级别的转换规则定义,如 AtenReluOp → tosa::ClampOp 转换规则:
在顶层视角上,是通过一个Convert Pass 来触发 Dialect 里所有 Operation 的转换的:
- 问题一:
getDependentDialects里关联的其他 Dialect 是为了什么?(待详细看源码) - 问题二:这种基于 Pattern 的 MatchAndRewriter 不会很低效么?(感觉总要是O{N},边遍历,边Match,边Rewrite?)
4.Dialect 的边界是如何界定的?如何在飞桨新 IR 迭代中遵循规范,良好的组织组件分层和目录管理?
从 mlir 已经竞品TF、Torch 的 ir dialect 分布来看,驱动新增 dialect 的主要需求包括(自底向上来看):
- 不同硬件 Backend:如GPU、NVGPU等在 mlir 里都是单独的 Dialect
- 不同优化库支持:如 OpenMP、OpenACC 相关的 Dialect
- 特定优化策略:如 Vector、X86Vector、Async 相关的Dialect
- 计算数据相关:如 Bufferization、MemRef 相关的 Dialect
- 计算流表示:如 Tensor、Linalg、Affine、Arith 相关的Dialect
- 控制流表示:如SCF、ControlFlow 相关的Dialect
- 深度学习框架中间层:Tosa、mlho、MLProgram 相关的 Dialect
- 深度学习框架最上层:Torch 、XLA-HLO 相关的Dialect
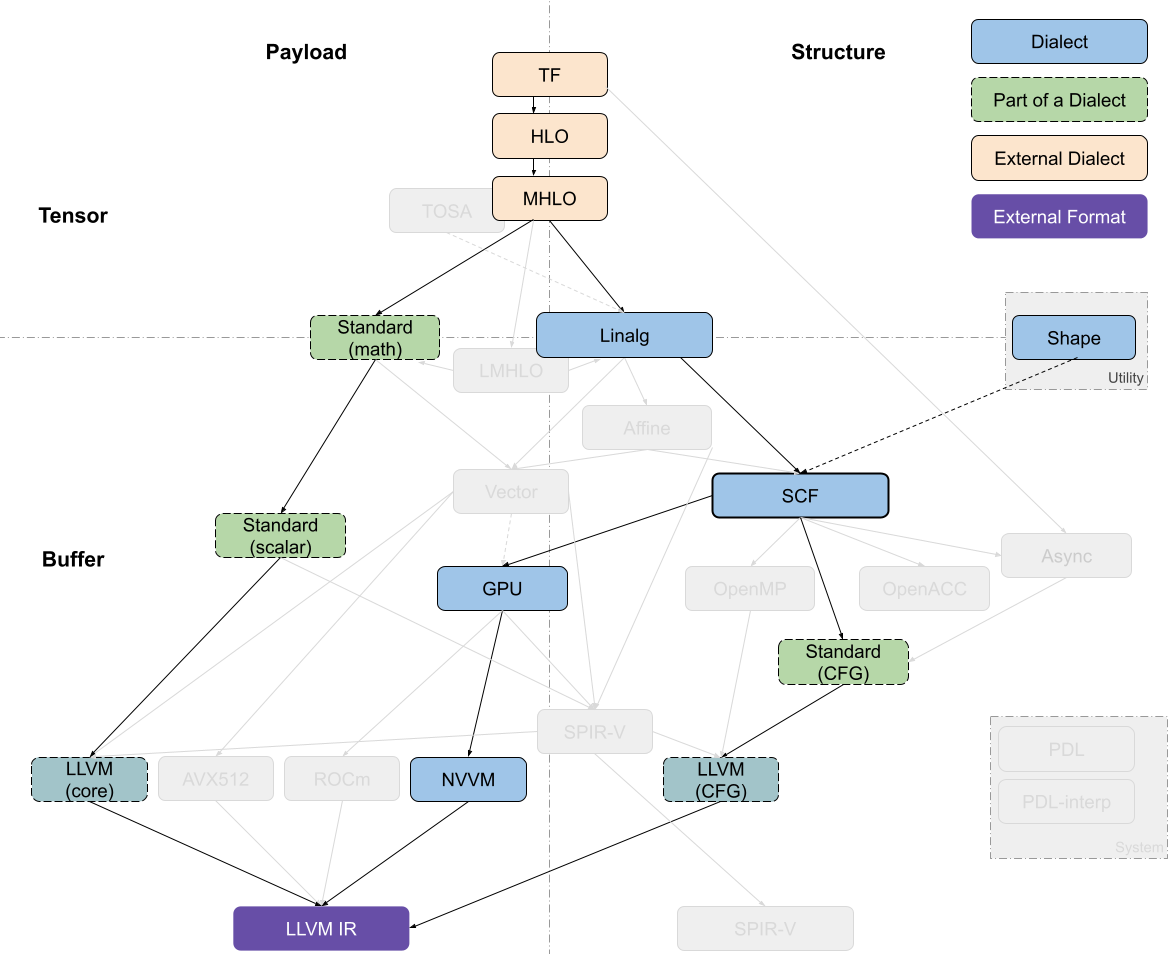
结合上面,我们重新 review下 TF 和 Torch 的两张流程图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号