Linux — 物理内存管理
物理内存的组织方式
- 物理内存是由连续的一页一页的块组成,每个物理页都有页号
- 每个页由
struct page表示,放进数组里——平坦内存模型
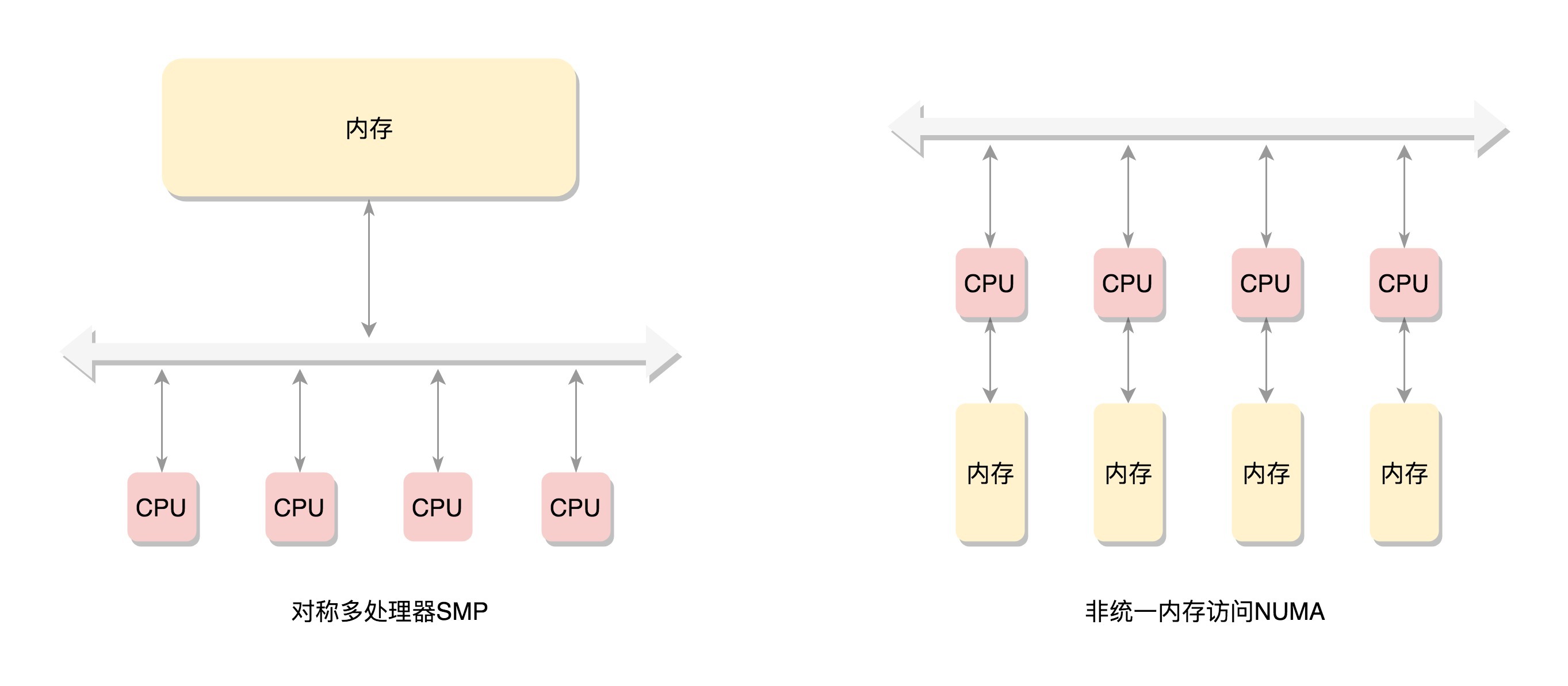
SMP和NUMA
- SMP中,总线会称为瓶颈,因为数据都要经过它
- NUMA中
- 每个CPU都有本地内存,CPU访存不用过总线
- 但本地内存不足时,每个CPU可以去另外的NUMA节点申请内存,延时较长
- NUMA基本是非连续内存模型,非连续内存模型不一定就是NUMA
typedef struct pglist_data
{
struct zone node_zones[MAX_NR_ZONES]; // 每个节点还会分成一个个区域zone
struct zonelist node_zonelists[MAX_ZONELISTS]; // 备用节点
int nr_zones;
struct page *node_mem_map; // 此节点的struct page数组
unsigned long node_start_pfn; // 起始页号
unsigned long node_present_pages; /* total number of physical pages */
unsigned long node_spanned_pages; /* total size of physical page range, including holes */
int node_id; // 自己的id
......
} pg_data_t;
举个例子:
64M 物理内存隔着一个 4M 的空洞,然后是另外的 64M 物理内存。 换算成页面数目就是,16K 个页面隔着 1K 个页面,然后是另外 16K 个页面。这种情况下,
node_spanned_pages就是 33K 个页面,node_present_pages就是 32K 个页面。
ZONE_DMA
ZONE_DMA可用于做直接内存存取的内存。
DMA机制:
要把外设的数据读入内存或把内存的数据传送到外设,原来都要通过 CPU 控制完成,但是这会占用 CPU,影响 CPU 处理其他事情,所以有了 DMA 模式。CPU 只需向 DMA 控制器下达指令,让 DMA 控制器来处理数据的传送,数据传送完毕再把信息反馈给 CPU,这样就可以解放 CPU。
64位系统有两个DMA系统,除了ZONE_DMA还有ZONE_DMA32
区域
上面把内存分成了节点,把节点分成了区域。区域zone的定义:
struct zone {
......
struct pglist_data *zone_pgdat;
struct per_cpu_pageset __percpu *pageset; // 用于区分冷热页
unsigned long zone_start_pfn; // 表示属于这个zone的第一页
/*
* spanned_pages is the total pages spanned by the zone, including
* holes, which is calculated as:
* spanned_pages = zone_end_pfn - zone_start_pfn;
*
* present_pages is physical pages existing within the zone, which
* is calculated as:
* present_pages = spanned_pages - absent_pages(pages in holes);
*
* managed_pages is present pages managed by the buddy system, which
* is calculated as (reserved_pages includes pages allocated by the
* bootmem allocator):
* managed_pages = present_pages - reserved_pages;
*
*/
unsigned long managed_pages; // 此zone被伙伴系统管理的所有page数目
unsigned long spanned_pages; // 包括中间的物理内存空洞
unsigned long present_pages; // 物理内存中真实存在的page数
const char *name;
......
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER];
/* zone flags, see below */
unsigned long flags;
/* Primarily protects free_area */
spinlock_t lock;
......
} ____cacheline_internodealigned_in_
什么是冷热页?
x86 体系结构中,为了让 CPU 快速访问段描述符,在 CPU 里面有段描述符缓存。CPU 访问这个缓存的速度比内存快得多。同样对于页来讲,也是这样的。如果一个页被加载到 CPU 高速缓存里面,这就是一个热页(Hot Page),CPU 读起来速度会快很多,如果没有就是冷页(Cold Page)。由于每个 CPU 都有自己的高速缓存,因而 per_cpu_pageset 也是每个 CPU 一个。
页(Page)
一个物理页面可以使用多种模式:
- 要用就用一整页
- 匿名页:一整页的内存,或者直接和虚拟地址空间建立映射关系
- 内存映射文件:或者用于关联一个文件,然后再和虚拟地址空间建立映射关系
- 每个进程都有自己的页表
- 仅需分配小块内存
- Linux采用了slab allocator 的技术,用于分配称为slab的小块内存
- 基本原理:
- 从内存管理模块申请一整块页
- 划分成多个小块的存储池,用复杂的队列维护小块的状态
- 状态包括:被分配了/被放回池子/应该被回收
Linux中把所有空闲页分为了11个页块链表,每个块链表分别包含很多个大小的页块,有1、2、4、8、16、32、64、128、512和1024个连续的页块。
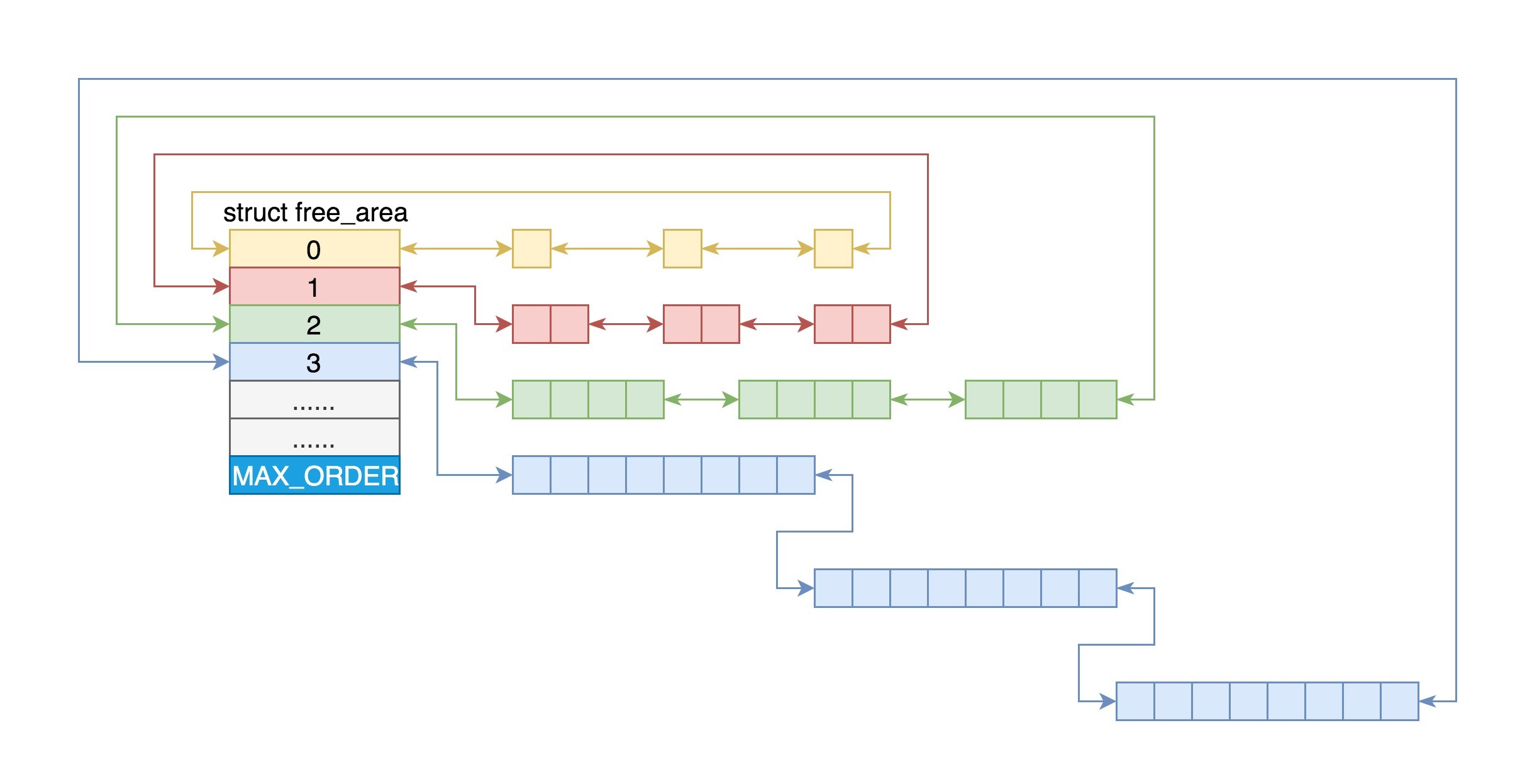
请求分配页块时,依次按照更大的页块链表去找。分配的页块有多余的页时,伙伴系统会根据多余的页块大小,插入到对应的空闲页块链表中。
举个栗子:
要请求一个 128 个页的页块时,先检查 128 个页的页块链表是否有空闲块。如果没有,则查 256 个页的页块链表;如果有空闲块的话,则将 256 个页的页块分成两份,一份使用,一份插入 128 个页的页块链表中。如果还是没有,就查 512 个页的页块链表;如果有的话,就分裂为 128、128、256 三个页块,一个 128 的使用,剩余两个插入对应页块链表。
小结
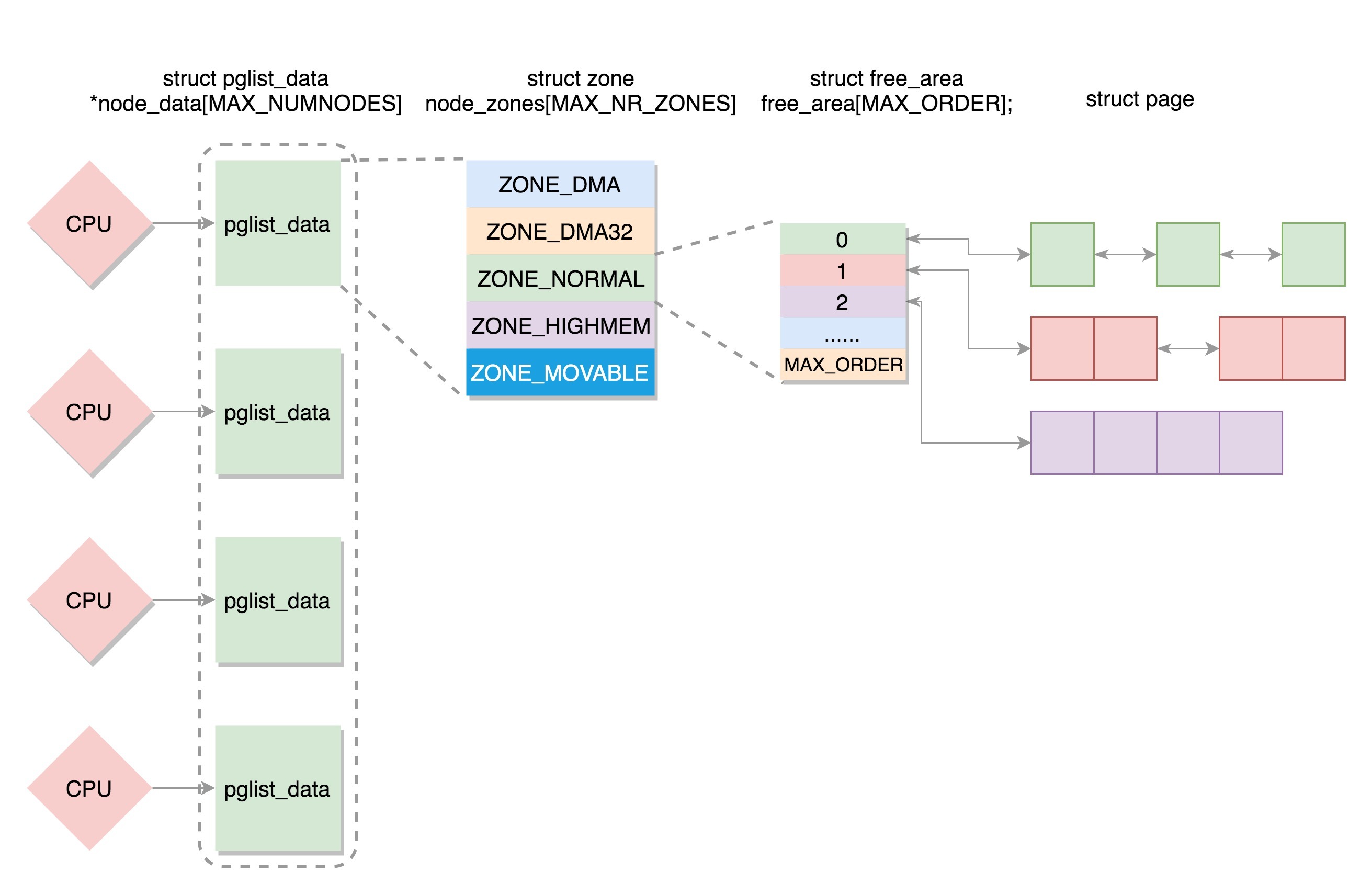
- 如果有多个 CPU,那就有多个节点。每个节点用 struct pglist_data 表示,放在一个数组里面。
- 每个节点分为多个区域,每个区域用 struct zone 表示,也放在一个数组里面。
- 每个区域分为多个页。为了方便分配,空闲页放在 struct free_area 里面,使用伙伴系统进行管理和分配,每一页用 struct page 表示。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号