摘要:
 TensorFlow Runtime,简称 TFRT,它提供了统一的、可扩展的基础架构层,可以极致地发挥CPU多线程性能,支持全异步编程(无锁队列+异步化语义)。TFRT 可以减少开发、验证和部署企业级模型所需的时间。 阅读全文
TensorFlow Runtime,简称 TFRT,它提供了统一的、可扩展的基础架构层,可以极致地发挥CPU多线程性能,支持全异步编程(无锁队列+异步化语义)。TFRT 可以减少开发、验证和部署企业级模型所需的时间。 阅读全文
TensorFlow Runtime,简称 TFRT,它提供了统一的、可扩展的基础架构层,可以极致地发挥CPU多线程性能,支持全异步编程(无锁队列+异步化语义)。TFRT 可以减少开发、验证和部署企业级模型所需的时间。 阅读全文
posted @ 2020-12-25 20:08
Aurelius84
阅读(2037)
评论(0)
推荐(0)
 一、问题描述 在大模型训练中,后预训练技术(Post-pretraining)通常指的是在模型的初始预训练阶段和最终的微调阶段之间进行的一个额外训练步骤。这个步骤的目的是进一步调整模型,使其能够更好地适应特定领域或任务,同时保持或增强其从大规模预训练数据中学到的通用知识和特征表示。 1.1 主要特点
一、问题描述 在大模型训练中,后预训练技术(Post-pretraining)通常指的是在模型的初始预训练阶段和最终的微调阶段之间进行的一个额外训练步骤。这个步骤的目的是进一步调整模型,使其能够更好地适应特定领域或任务,同时保持或增强其从大规模预训练数据中学到的通用知识和特征表示。 1.1 主要特点  回顾复盘五年来的研发经历,愈发认同身边同事强调的“第一性原理”思维,仅做浅浅记录和分享 一、定义与理论介绍 第一性原理(First Principles),又称基本原理,是指从最基本的假设和定义出发,通过逻辑推理和演绎得出结论的一种思维方法。它强调对事物的本质和根源进行深入的理解,不受已有的经验、知
回顾复盘五年来的研发经历,愈发认同身边同事强调的“第一性原理”思维,仅做浅浅记录和分享 一、定义与理论介绍 第一性原理(First Principles),又称基本原理,是指从最基本的假设和定义出发,通过逻辑推理和演绎得出结论的一种思维方法。它强调对事物的本质和根源进行深入的理解,不受已有的经验、知 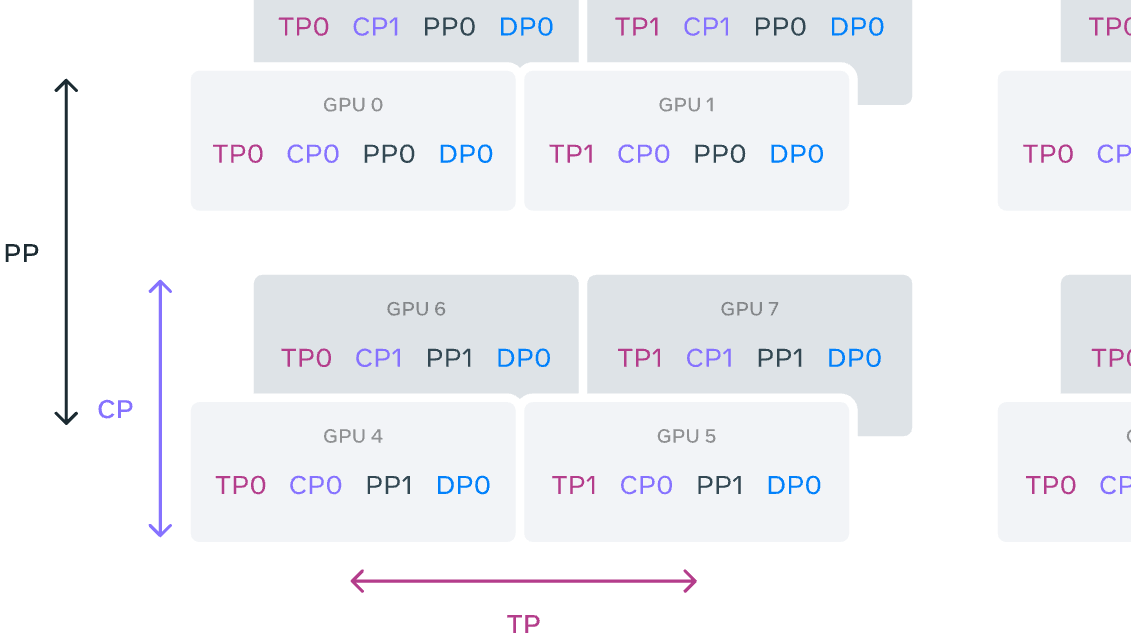 一、 引言概述(Intro & Overview) Llama3是一系列基于Transformer结构的大型多语言模型,通过优化数据质量、训练规模和模型架构,旨在提升模型在各种语言理解任务中的表现。 通过引入更优质的数据和更高效的训练方法,Llama3展示了在自然语言处理领域的巨大潜力。其创新点在于
一、 引言概述(Intro & Overview) Llama3是一系列基于Transformer结构的大型多语言模型,通过优化数据质量、训练规模和模型架构,旨在提升模型在各种语言理解任务中的表现。 通过引入更优质的数据和更高效的训练方法,Llama3展示了在自然语言处理领域的巨大潜力。其创新点在于 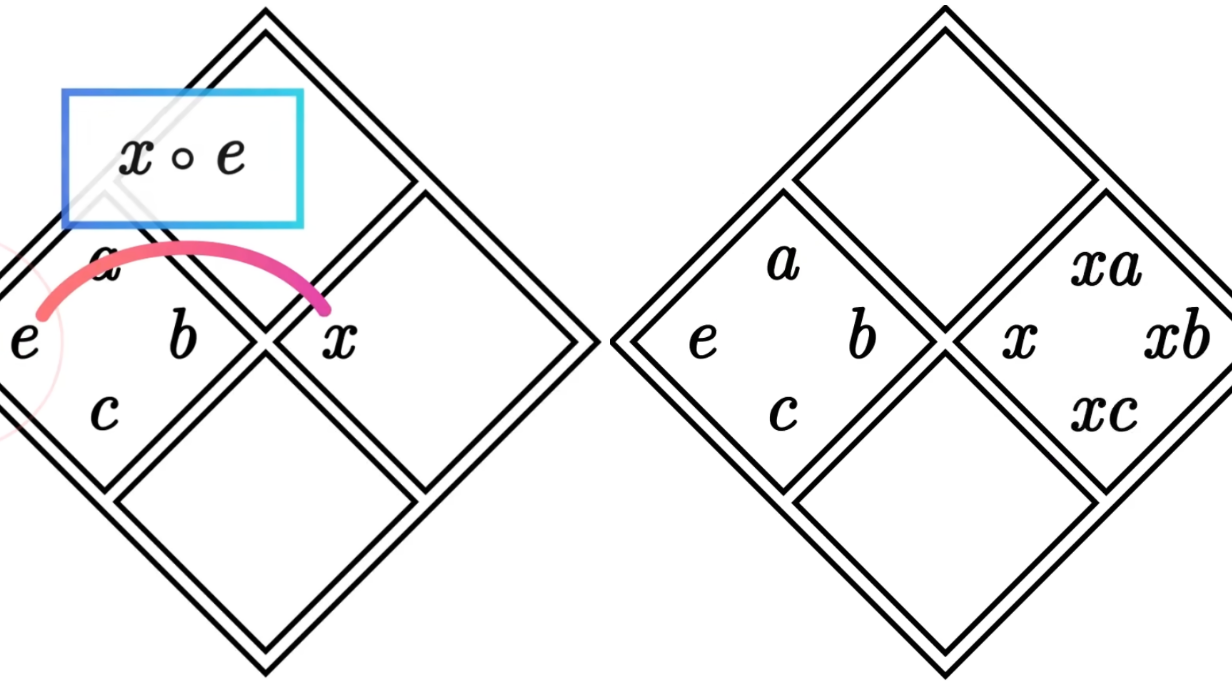 一、重要性 1.1 领域意义 群论是数学的一个分支,主要研究代数结构中的群、环、域等。尽管它看似抽象,但在编程领域,群论有着广泛的应用和深刻的意义。 算法设计与优化:群论在算法设计中发挥着重要作用。例如,在密码学中,群论被用于设计安全的加密算法,如椭圆曲线密码学,它依赖于椭圆曲线上的群结构;在图论和
一、重要性 1.1 领域意义 群论是数学的一个分支,主要研究代数结构中的群、环、域等。尽管它看似抽象,但在编程领域,群论有着广泛的应用和深刻的意义。 算法设计与优化:群论在算法设计中发挥着重要作用。例如,在密码学中,群论被用于设计安全的加密算法,如椭圆曲线密码学,它依赖于椭圆曲线上的群结构;在图论和  本文章涉及的Megatron-llm的XMind思维导图源文件和PDF文件,可在网盘下载: https://pan.baidu.com/s/1xRZD-IP95y7-4Fn0C_VJMg 提取码: qxff 一、引言 Megatron-Core 是一个基于 PyTorch 的开源库,专为在 NVID
本文章涉及的Megatron-llm的XMind思维导图源文件和PDF文件,可在网盘下载: https://pan.baidu.com/s/1xRZD-IP95y7-4Fn0C_VJMg 提取码: qxff 一、引言 Megatron-Core 是一个基于 PyTorch 的开源库,专为在 NVID  一、目标 1.1 背景 AI工具库生态的碎片化:随着AI技术的快速发展,市场上涌现出了多种深度学习框架,如TensorFlow、PyTorch、PaddlePaddle等。每种框架都有其独特的优势和生态系统,但这也导致了AI工具库生态的碎片化。不同框架之间的模型和数据格式互不兼容,使得模型迁移和部署
一、目标 1.1 背景 AI工具库生态的碎片化:随着AI技术的快速发展,市场上涌现出了多种深度学习框架,如TensorFlow、PyTorch、PaddlePaddle等。每种框架都有其独特的优势和生态系统,但这也导致了AI工具库生态的碎片化。不同框架之间的模型和数据格式互不兼容,使得模型迁移和部署 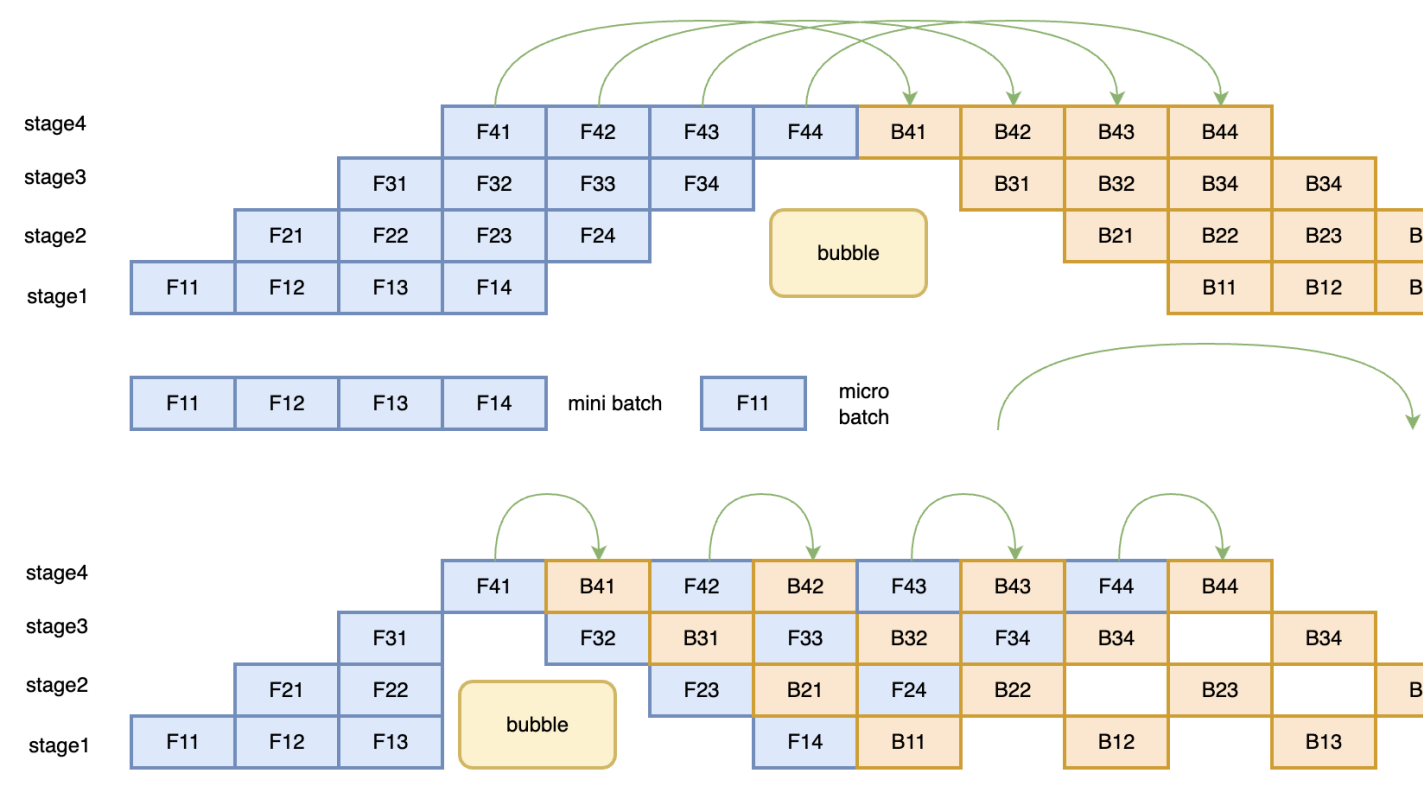 为个人参与深度学习框架飞桨PaddlePaddle 开发时,梳理的个人笔记。 一、并行方式 1.数据并行(Batch维度) 数据并行分为了两种模式:Data Parallel(DP) 和 Distributed Data Parallel(DDP) 。 1.1 Data Parallel DP是一种
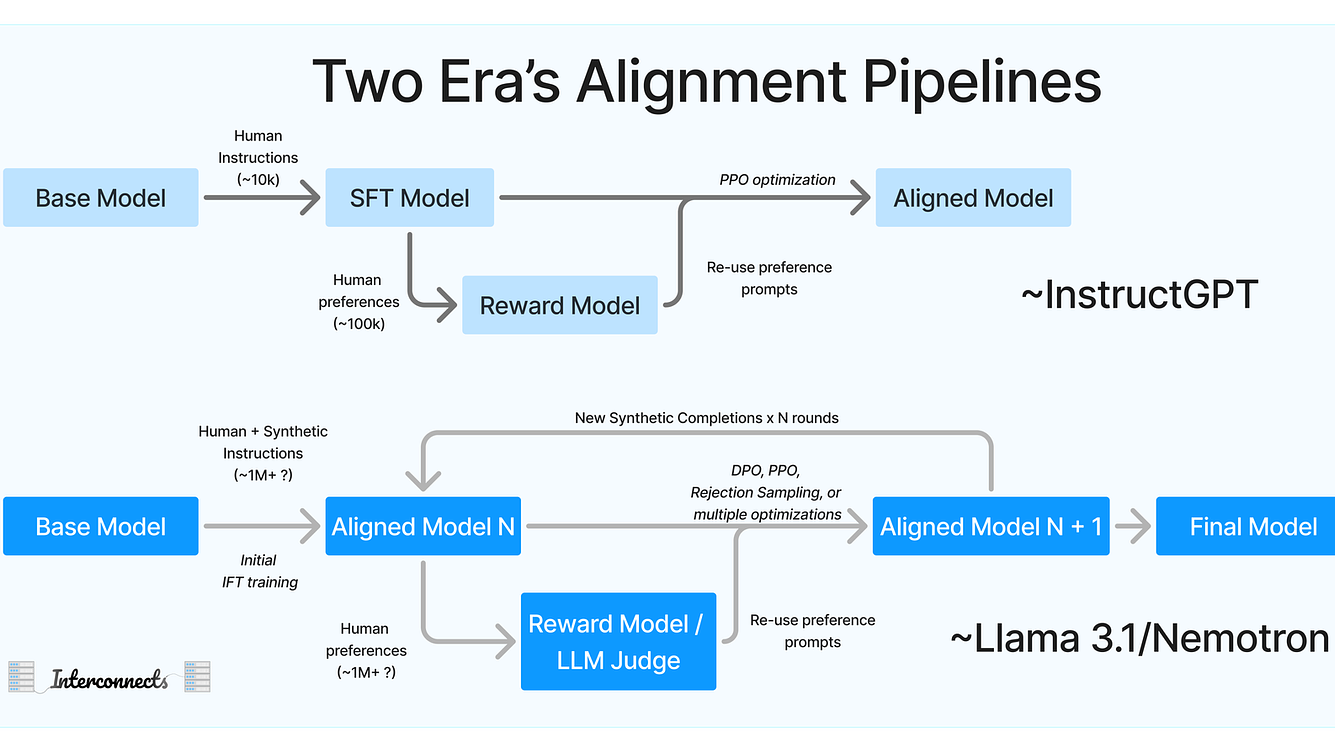
为个人参与深度学习框架飞桨PaddlePaddle 开发时,梳理的个人笔记。 一、并行方式 1.数据并行(Batch维度) 数据并行分为了两种模式:Data Parallel(DP) 和 Distributed Data Parallel(DDP) 。 1.1 Data Parallel DP是一种 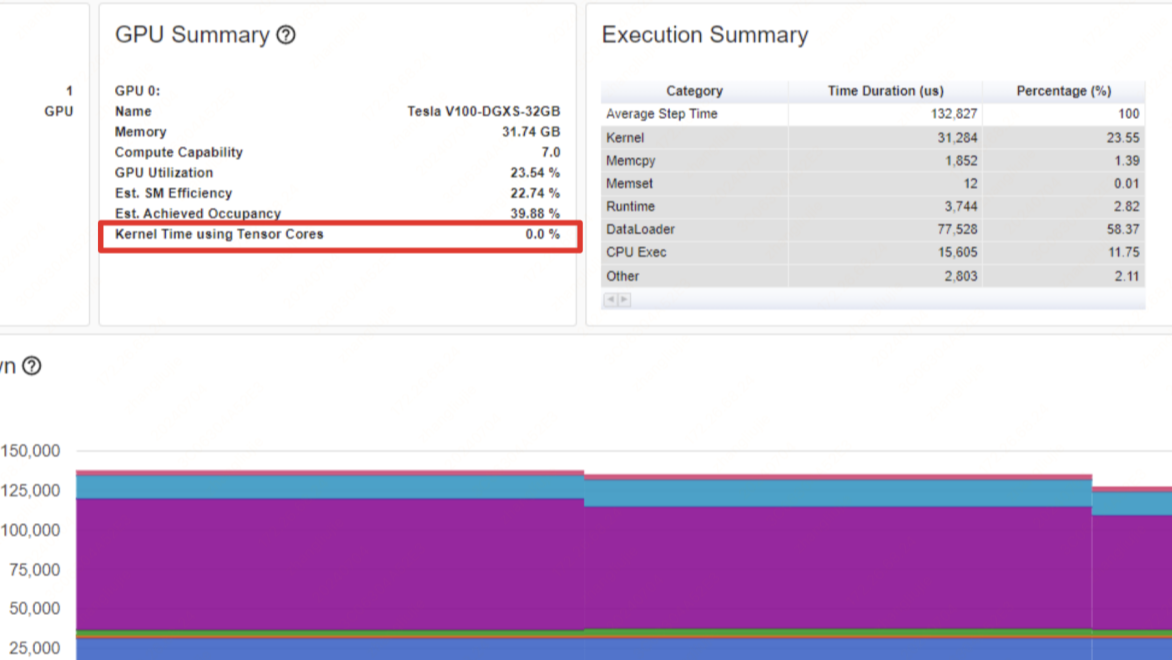 一、问题背景 随着AIGC领域的兴起,各大厂商都在训练和推出自研的大模型结构,并结合业务进行落地和推广。在大模型分布式训练场景中,主流的主要是基于英伟达GPU进行训练(如A100),如何有效地压榨GPU的计算能力,提升训练效率,降低训练成本,是一个非常重要的实践优化问题。 1.1 直接目标 最直接地
一、问题背景 随着AIGC领域的兴起,各大厂商都在训练和推出自研的大模型结构,并结合业务进行落地和推广。在大模型分布式训练场景中,主流的主要是基于英伟达GPU进行训练(如A100),如何有效地压榨GPU的计算能力,提升训练效率,降低训练成本,是一个非常重要的实践优化问题。 1.1 直接目标 最直接地  注:如下是在做深度学习框架开发时,用到的火焰图pprof和 CUDA Nsys 配置指南,可能对大家有一些帮助,就此分享。一些是基于飞桨的Docker镜像配置的。 一、环境 & 工具配置 0. 开发机配置 # 1.构建镜像, 记得映射端口,可以多映射几个;记得挂载ssd目录,因为数据都在ssd盘上
注:如下是在做深度学习框架开发时,用到的火焰图pprof和 CUDA Nsys 配置指南,可能对大家有一些帮助,就此分享。一些是基于飞桨的Docker镜像配置的。 一、环境 & 工具配置 0. 开发机配置 # 1.构建镜像, 记得映射端口,可以多映射几个;记得挂载ssd目录,因为数据都在ssd盘上  浙公网安备 33010602011771号
浙公网安备 33010602011771号