Redis中
1. ### LIMITS限制 ###
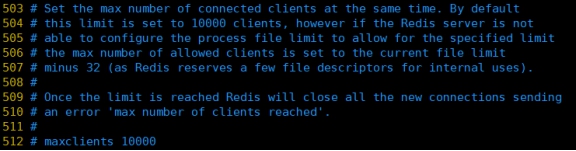
1. maxclients
-
设置redis同时可以与多少个客户端进行连接。
-
默认情况下为10000个客户端。
-
如果达到了此限制,redis则会拒绝新的连接请求,并且向这些连接请求方发出“max
number of clients reached”以作回应。
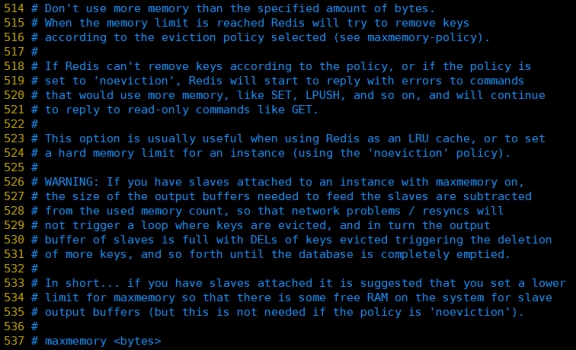
- maxmemory
-
建议必须设置,否则,将内存占满,造成服务器宕机
-
设置redis可以使用的内存量。一旦到达内存使用上限,redis将会试图移除内部数据,移除规则可以通过maxmemory-policy来指定。
-
如果redis无法根据移除规则来移除内存中的数据,或者设置了“不允许移除”,那么redis则会针对那些需要申请内存的指令返回错误信息,比如SET、LPUSH等。
-
但是对于无内存申请的指令,仍然会正常响应,比如GET等。如果你的redis是主redis(说明你的redis有从redis),那么在设置内存使用上限时,需要在系统中留出一些内存空间给同步队列缓存,只有在你设置的是“不移除”的情况下,才不用考虑这个因素。
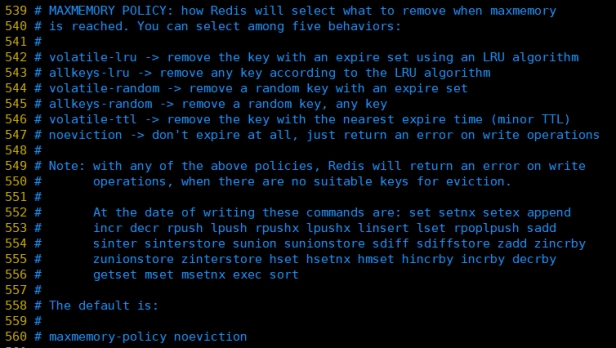
- maxmemory-policy
-
volatile-lru:使用LRU算法移除key,只对设置了过期时间的键;(最近最少使用)
-
allkeys-lru:在所有集合key中,使用LRU算法移除key
-
volatile-random:在过期集合中移除随机的key,只对设置了过期时间的键
-
allkeys-random:在所有集合key中,移除随机的key
-
volatile-ttl:移除那些TTL值最小的key,即那些最近要过期的key
-
noeviction:不进行移除。针对写操作,只是返回错误信息
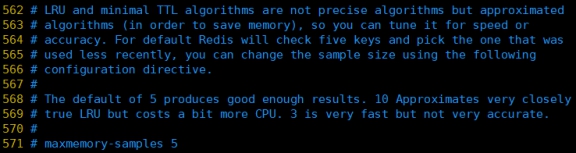
- maxmemory-samples
-
设置样本数量,LRU算法和最小TTL算法都并非是精确的算法,而是估算值,所以你可以设置样本的大小,redis默认会检查这么多个key并选择其中LRU的那个。
-
一般设置3到7的数字,数值越小样本越不准确,但性能消耗越小。
-
Redis的发布和订阅
- 什么是发布和订阅
Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub)
接收消息。
Redis 客户端可以订阅任意数量的频道。
- Redis的发布和订阅
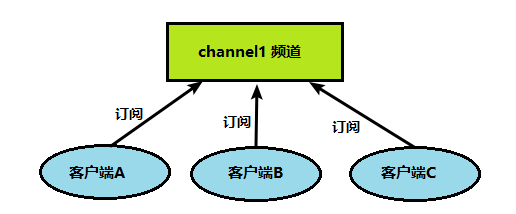
1、客户端可以订阅频道如下图
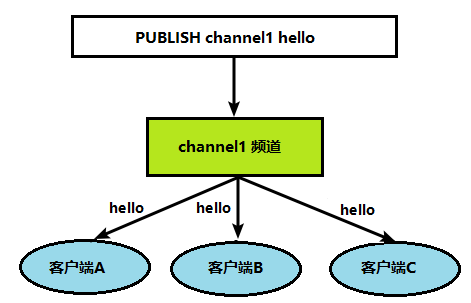
2、当给这个频道发布消息后,消息就会发送给订阅的客户端
-
发布订阅命令行实现
-
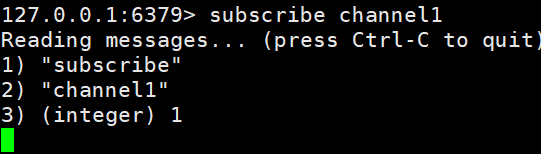
打开一个客户端订阅channel1
SUBSCRIBE channel1
2、打开另一个客户端,给channel1发布消息hello
publish channel1 hello

返回的1是订阅者数量
3、打开第一个客户端可以看到发送的消息
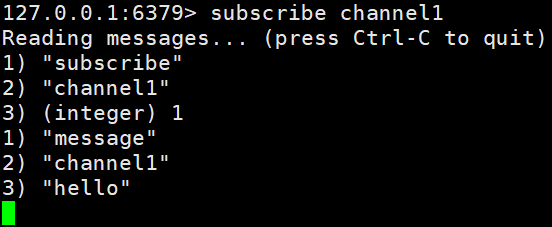
注:发布的消息没有持久化,如果在订阅的客户端收不到hello,只能收到订阅后发布的消息
-
Redis新数据类型
-
Bitmaps
- 简介
-
现代计算机用二进制(位) 作为信息的基础单位, 1个字节等于8位,
例如“abc”字符串是由3个字节组成, 但实际在计算机存储时将其用二进制表示,
“abc”分别对应的ASCII码分别是97、 98、 99, 对应的二进制分别是01100001、
01100010和01100011,如下图

合理地使用操作位能够有效地提高内存使用率和开发效率。
Redis提供了Bitmaps这个“数据类型”可以实现对位的操作:
-
Bitmaps本身不是一种数据类型, 实际上它就是字符串(key-value) ,
但是它可以对字符串的位进行操作。 -
Bitmaps单独提供了一套命令,
所以在Redis中使用Bitmaps和使用字符串的方法不太相同。
可以把Bitmaps想象成一个以位为单位的数组, 数组的每个单元只能存储0和1,
数组的下标在Bitmaps中叫做偏移量。

- 命令
1、setbit
(1)格式
setbit<key><offset><value>设置Bitmaps中某个偏移量的值(0或1)

*offset:偏移量从0开始
(2)实例
每个独立用户是否访问过网站存放在Bitmaps中, 将访问的用户记做1,
没有访问的用户记做0, 用偏移量作为用户的id。
设置键的第offset个位的值(从0算起) , 假设现在有20个用户,userid=1, 6, 11,
15, 19的用户对网站进行了访问, 那么当前Bitmaps初始化结果如图
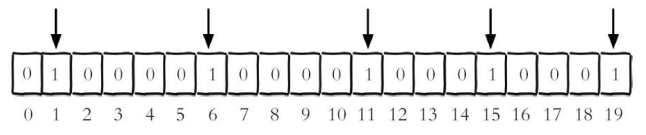
unique:users:20201106代表2020-11-06这天的独立访问用户的Bitmaps
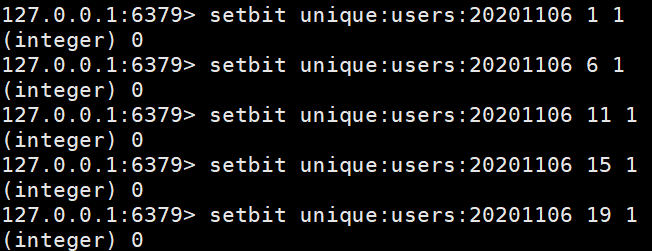
注:
很多应用的用户id以一个指定数字(例如10000) 开头,
直接将用户id和Bitmaps的偏移量对应势必会造成一定的浪费,
通常的做法是每次做setbit操作时将用户id减去这个指定数字。
在第一次初始化Bitmaps时, 假如偏移量非常大, 那么整个初始化过程执行会比较慢,
可能会造成Redis的阻塞。
2、getbit
(1)格式
getbit<key><offset>获取Bitmaps中某个偏移量的值

获取键的第offset位的值(从0开始算)
(2)实例
获取id=8的用户是否在2020-11-06这天访问过, 返回0说明没有访问过:
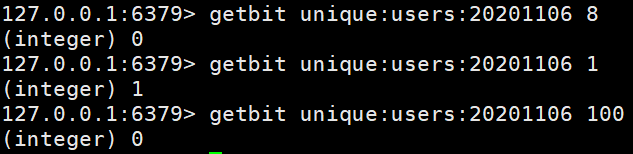
注:因为100根本不存在,所以也是返回0
3、bitcount
统计字符串被设置为1的bit数。一般情况下,给定的整个字符串都会被进行计数,通过指定额外的
start 或 end 参数,可以让计数只在特定的位上进行。start 和 end
参数的设置,都可以使用负数值:比如 -1 表示最后一个位,而 -2
表示倒数第二个位,start、end 是指bit组的字节的下标数,二者皆包含。
(1)格式
bitcount<key>[start end] 统计字符串从start字节到end字节比特值为1的数量

(2)实例
计算2022-11-06这天的独立访问用户数量

start和end代表起始和结束字节数,
下面操作计算用户id在第1个字节到第3个字节之间的独立访问用户数,
对应的用户id是11, 15, 19。

举例: K1 【01000001 01000000 00000000 00100001】,对应【0,1,2,3】
bitcount K1 1 2 : 统计下标1、2字节组中bit=1的个数,即01000000 00000000
--》bitcount K1 1 2 --》1
bitcount K1 1 3 : 统计下标1、2字节组中bit=1的个数,即01000000 00000000 00100001
--》bitcount K1 1 3 --》3
bitcount K1 0 -2 : 统计下标0到下标倒数第2,字节组中bit=1的个数,即01000001
01000000 00000000
--》bitcount K1 0 -2 --》3
注意:redis的setbit设置或清除的是bit位置,而bitcount计算的是byte位置。
4、bitop
(1)格式
bitop and(or/not/xor) <destkey> [key…]

bitop是一个复合操作, 它可以做多个Bitmaps的and(交集) 、 or(并集) 、
not(非) 、 xor(异或) 操作并将结果保存在destkey中。
(2)实例
2020-11-04 日访问网站的userid=1,2,5,9。
setbit unique:users:20201104 1 1
setbit unique:users:20201104 2 1
setbit unique:users:20201104 5 1
setbit unique:users:20201104 9 1
2020-11-03 日访问网站的userid=0,1,4,9。
setbit unique:users:20201103 0 1
setbit unique:users:20201103 1 1
setbit unique:users:20201103 4 1
setbit unique:users:20201103 9 1
计算出两天都访问过网站的用户数量
bitop and unique:users:and:20201104_03
unique:users:20201103unique:users:20201104

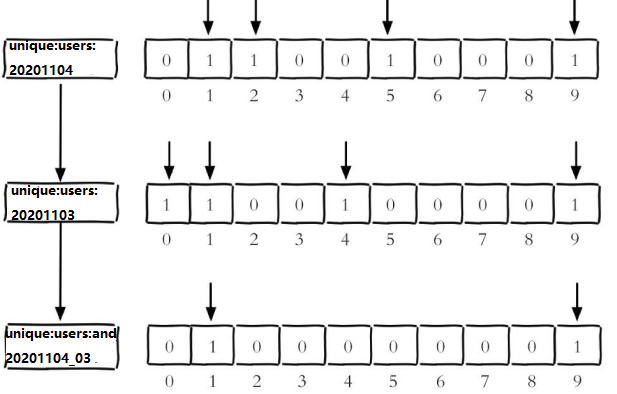
计算出任意一天都访问过网站的用户数量(例如月活跃就是类似这种) ,
可以使用or求并集

- Bitmaps与set对比
假设网站有1亿用户, 每天独立访问的用户有5千万,
如果每天用集合类型和Bitmaps分别存储活跃用户可以得到表
| set和Bitmaps存储一天活跃用户对比 | |||
|---|---|---|---|
| 数据 类型 | 每个用户id占用空间 | 需要存储的用户量 | 全部内存量 |
| 集合 类型 | 64位 | 50000000 | 64位*50000000 = 400MB |
| Bitmaps | 1位 | 100000000 | 1位*100000000 = 12.5MB |
很明显, 这种情况下使用Bitmaps能节省很多的内存空间,
尤其是随着时间推移节省的内存还是非常可观的
| set和Bitmaps存储独立用户空间对比 | |||
|---|---|---|---|
| 数据类型 | 一天 | 一个月 | 一年 |
| 集合类型 | 400MB | 12GB | 144GB |
| Bitmaps | 12.5MB | 375MB | 4.5GB |
但Bitmaps并不是万金油, 假如该网站每天的独立访问用户很少,
例如只有10万(大量的僵尸用户) , 那么两者的对比如下表所示, 很显然,
这时候使用Bitmaps就不太合适了, 因为基本上大部分位都是0。
| set和Bitmaps存储一天活跃用户对比(独立用户比较少) | |||
|---|---|---|---|
| 数据类型 | 每个userid占用空间 | 需要存储的用户量 | 全部内存量 |
| 集合类型 | 64位 | 100000 | 64位*100000 = 800KB |
| Bitmaps | 1位 | 100000000 | 1位*100000000 = 12.5MB |
-
HyperLogLog
- 简介
在工作当中,我们经常会遇到与统计相关的功能需求,比如统计网站PV(PageView页面访问量),可以使用Redis的incr、incrby轻松实现。
但像UV(UniqueVisitor,独立访客)、独立IP数、搜索记录数等需要去重和计数的问题如何解决?这种求集合中不重复元素个数的问题称为基数问题。
解决基数问题有很多种方案:
(1)数据存储在MySQL表中,使用distinct count计算不重复个数
(2)使用Redis提供的hash、set、bitmaps等数据结构来处理
以上的方案结果精确,但随着数据不断增加,导致占用空间越来越大,对于非常大的数据集是不切实际的。
能否能够降低一定的精度来平衡存储空间?Redis推出了HyperLogLog
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog
的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64
个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以
HyperLogLog 不能像集合那样,返回输入的各个元素。
什么是基数?
比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8},
基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
- 命令
1、pfadd
(1)格式
pfadd <key>< element> [element ...] 添加指定元素到 HyperLogLog 中

(2)实例
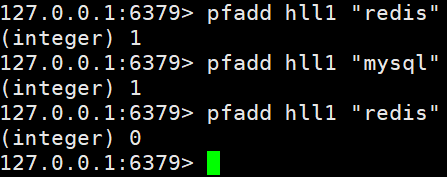
将所有元素添加到指定HyperLogLog数据结构中。如果执行命令后HLL估计的近似基数发生变化,则返回1,否则返回0。
2、pfcount
(1)格式
pfcount<key> [key ...]
计算HLL的近似基数,可以计算多个HLL,比如用HLL存储每天的UV,计算一周的UV可以使用7天的UV合并计算即可

(2)实例
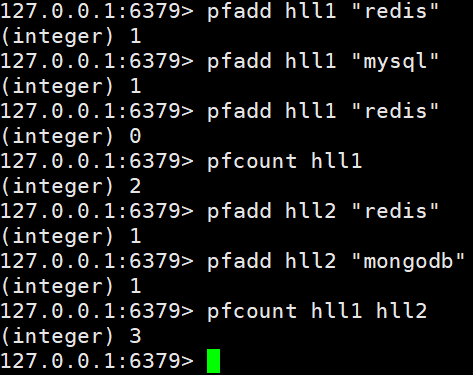
3、pfmerge
(1)格式
pfmerge<destkey><sourcekey> [sourcekey ...]
将一个或多个HLL合并后的结果存储在另一个HLL中,比如每月活跃用户可以使用每天的活跃用户来合并计算可得

(2)实例
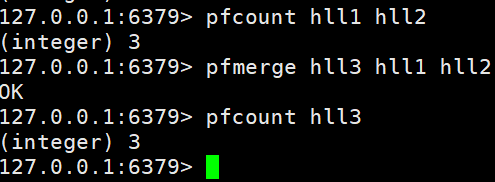
-
Geospatial
- 简介
Redis 3.2
中增加了对GEO类型的支持。GEO,Geographic,地理信息的缩写。该类型,就是元素的2维坐标,在地图上就是经纬度。redis基于该类型,提供了经纬度设置,查询,范围查询,距离查询,经纬度Hash等常见操作。
- 命令
1、geoadd
(1)格式
geoadd<key>< longitude><latitude><member> [longitude latitude member...]
添加地理位置(经度,纬度,名称)

(2)实例
geoadd china:city 121.47 31.23 shanghai
geoadd china:city 106.50 29.53 chongqing 114.05 22.52 shenzhen 116.38 39.90
beijing

两极无法直接添加,一般会下载城市数据,直接通过 Java 程序一次性导入。
有效的经度从 -180 度到 180 度。有效的纬度从 -85.05112878 度到 85.05112878 度。
当坐标位置超出指定范围时,该命令将会返回一个错误。
已经添加的数据,是无法再次往里面添加的。
2、geopos
(1)格式
geopos <key><member> [member...] 获得指定地区的坐标值

(2)实例

3、geodist
(1)格式
geodist<key><member1><member2> [m|km|ft|mi ] 获取两个位置之间的直线距离

(2)实例
获取两个位置之间的直线距离

单位:
m 表示单位为米[默认值]。
km 表示单位为千米。
mi 表示单位为英里。
ft 表示单位为英尺。
如果用户没有显式地指定单位参数, 那么 GEODIST 默认使用米作为单位
4、georadius
(1)格式
georadius<key>< longitude><latitude>radius m|km|ft|mi
以给定的经纬度为中心,找出某一半径内的元素

经度 纬度 距离 单位
(2)实例

-
Redis_Jedis_测试
- Jedis所需要的jar包
| <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>3.2.0</version> </dependency> |
|---|
- 连接Redis注意事项
禁用Linux的防火墙:Linux(CentOS7)里执行命令
systemctl stop/disable firewalld.service
redis.conf中注释掉bind 127.0.0.1 ,然后 protected-mode no
-
Jedis常用操作
- 创建动态的工程
-
创建测试程序
| package com.atguigu.jedis; import redis.clients.jedis.Jedis; public class Demo01 { public static void main(String[] args) { Jedis jedis = new Jedis("192.168.137.3",6379); String pong = jedis.ping(); System.out.println("连接成功:"+pong); jedis.close(); } } |
|---|
-
测试相关数据类型
- Jedis-API: Key
| jedis.set("k1", "v1"); jedis.set("k2", "v2"); jedis.set("k3", "v3"); Set<String> keys = jedis.keys("*"); System.out.println(keys.size()); for (String key : keys) { System.out.println(key); } System.out.println(jedis.exists("k1")); System.out.println(jedis.ttl("k1")); System.out.println(jedis.get("k1")); |
|---|
- Jedis-API: String
| jedis.mset("str1","v1","str2","v2","str3","v3"); System.out.println(jedis.mget("str1","str2","str3")); |
|---|
- Jedis-API: List
| List<String> list = jedis.lrange("mylist",0,-1); for (String element : list) |
|---|
- Jedis-API: set
| jedis.sadd("orders", "order01"); jedis.sadd("orders", "order02"); jedis.sadd("orders", "order03"); jedis.sadd("orders", "order04"); Set<String> smembers = jedis.smembers("orders"); for (String order : smembers) { System.out.println(order); } jedis.srem("orders", "order02"); |
|---|
- Jedis-API: hash
| jedis.hset("hash1","userName","lisi"); System.out.println(jedis.hget("hash1","userName")); Map<String,String> map = new HashMap<String,String>(); map.put("telphone","13810169999"); map.put("address","atguigu"); map.put("email","abc@163.com"); jedis.hmset("hash2",map); List<String> result = jedis.hmget("hash2", "telphone","email"); for (String element : result) |
|---|
- Jedis-API: zset
| jedis.zadd("zset01", 100d, "z3"); jedis.zadd("zset01", 90d, "l4"); jedis.zadd("zset01", 80d, "w5"); jedis.zadd("zset01", 70d, "z6"); Set<String> zrange = jedis.zrange("zset01", 0, -1); for (String e : zrange) |
|---|
-
Redis_Jedis_实例
- 完成一个手机验证码功能
要求:
1、输入手机号,点击发送后随机生成6位数字码,2分钟有效
2、输入验证码,点击验证,返回成功或失败
3、每个手机号每天只能输入3次
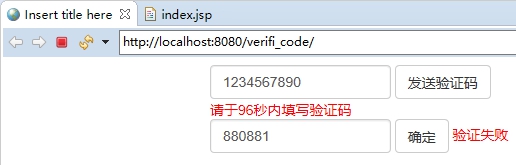
-
Redis与Spring Boot整合
Spring Boot整合Redis非常简单,只需要按如下步骤整合即可
- 整合步骤
-
在pom.xml文件中引入redis相关依赖
| *<!-- redis --> *<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> *<!-- spring2.X集成redis所需common-pool2--> *<dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-pool2</artifactId> <version>2.6.0</version> </dependency> |
|---|
- application.properties配置redis配置
| *#Redis服务器地址 spring.redis.host=*192.168.140.136 **#Redis服务器连接端口 spring.redis.port=6379 ***#Redis数据库索引(默认为0) *spring.redis.database= **0 **#连接超时时间(毫秒) spring.redis.timeout=1800000 **#连接池最大连接数(使用负值表示没有限制) spring.redis.lettuce.pool.max-active=20 **#最大阻塞等待时间(负数表示没限制) spring.redis.lettuce.pool.max-wait=-1 **#连接池中的最大空闲连接 spring.redis.lettuce.pool.max-idle=5 #连接池中的最小空闲连接 spring.redis.lettuce.pool.min-idle=0 |
|---|
- 添加redis配置类
| @EnableCaching @Configuration public class RedisConfig extends CachingConfigurerSupport { @Bean public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) { RedisTemplate<String, Object> template = new RedisTemplate<>(); RedisSerializer<String> redisSerializer = new StringRedisSerializer(); Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class); ObjectMapper om = new ObjectMapper(); om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY); om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL); jackson2JsonRedisSerializer.setObjectMapper(om); template.setConnectionFactory(factory); //key序列化方式 * template.setKeySerializer(redisSerializer); //value序列化 * template.setValueSerializer(jackson2JsonRedisSerializer); //value hashmap序列化 * template.setHashValueSerializer(jackson2JsonRedisSerializer); return template; } @Bean public CacheManager cacheManager(RedisConnectionFactory factory) { RedisSerializer<String> redisSerializer = new StringRedisSerializer(); Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class); //解决查询缓存转换异常的问题 * ObjectMapper om = new ObjectMapper(); om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY); om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL); jackson2JsonRedisSerializer.setObjectMapper(om); // 配置序列化(解决乱码的问题),过期时间600秒 * RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig() .entryTtl(Duration.ofSeconds(600)) .serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(redisSerializer)) .serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer)) .disableCachingNullValues(); RedisCacheManager cacheManager = RedisCacheManager.builder*(factory) .cacheDefaults(config) .build(); return cacheManager; } } |
|---|
4、测试一下
RedisTestController中添加测试方法
| @RestController @RequestMapping("/redisTest") public class RedisTestController { @Autowired private RedisTemplate redisTemplate; @GetMapping public String testRedis() { *//设置值到redis * redisTemplate.opsForValue().set("name","lucy"); *//从redis获取值 * String name = (String)redisTemplate.opsForValue().get("name"); return name; } } |
|---|
-
Redis_事务_锁机制_秒杀
- Redis的事务定义

Redis事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
Redis事务的主要作用就是串联多个命令防止别的命令插队。
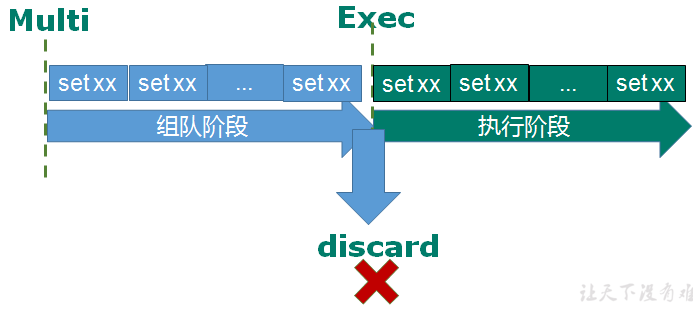
- Multi、Exec、discard
从输入Multi命令开始,输入的命令都会依次进入命令队列中,但不会执行,直到输入Exec后,Redis会将之前的命令队列中的命令依次执行。
组队的过程中可以通过discard来放弃组队。
案例:
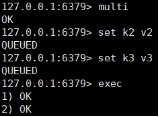 组队成功,提交成功 组队成功,提交成功 |
|---|
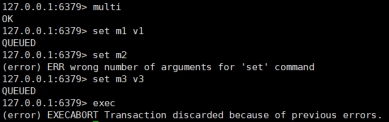 组队阶段报错,提交失败 组队阶段报错,提交失败 |
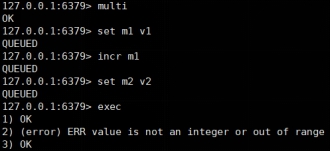 组队成功,提交有成功有失败情况 组队成功,提交有成功有失败情况 |
- 事务的错误处理
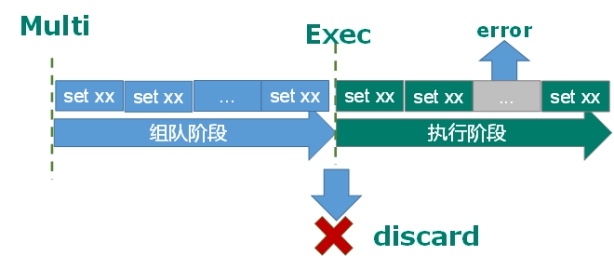
组队中某个命令出现了报告错误,执行时整个的所有队列都会被取消。
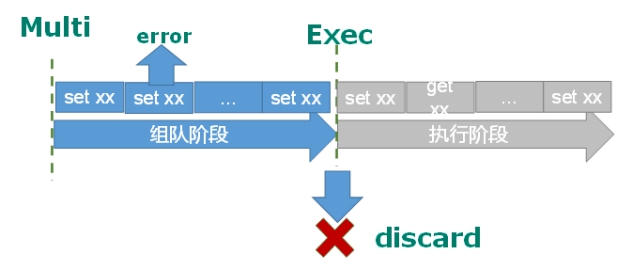
如果执行阶段某个命令报出了错误,则只有报错的命令不会被执行,而其他的命令都会执行,不会回滚。
- 为什么要做成事务
想想一个场景:有很多人有你的账户,同时去参加双十一抢购
-
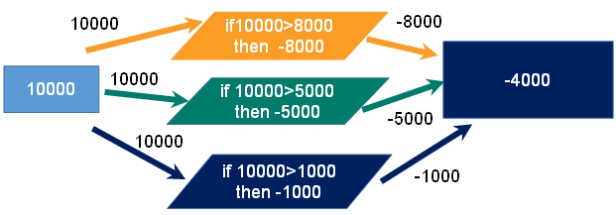
事务冲突的问题
- 例子
一个请求想给金额减8000
一个请求想给金额减5000
一个请求想给金额减1000
- 悲观锁
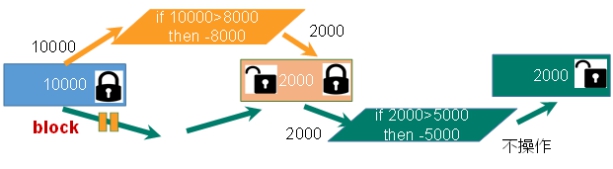
悲观锁(Pessimistic Lock),
顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
- 乐观锁
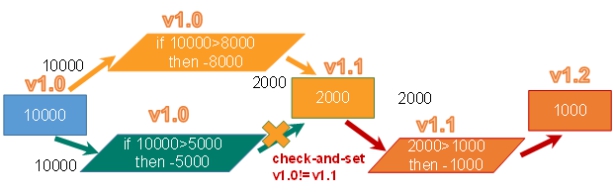
乐观锁(Optimistic Lock),
顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量。Redis就是利用这种check-and-set机制实现事务的。
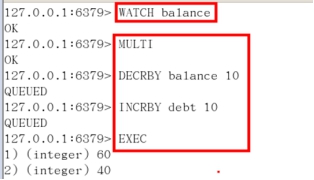
- WATCH key [key ...]
在执行multi之前,先执行watch key1 [key2],可以监视一个(或多个) key
,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。
- unwatch
取消 WATCH 命令对所有 key 的监视。
如果在执行 WATCH 命令之后,EXEC 命令或DISCARD
命令先被执行了的话,那么就不需要再执行UNWATCH 了。
http://doc.redisfans.com/transaction/exec.html
- Redis事务三特性
-
单独的隔离操作
- 事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
-
没有隔离级别的概念
- 队列中的命令没有提交之前都不会实际被执行,因为事务提交前任何指令都不会被实际执行
-
不保证原子性
- 事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚
-
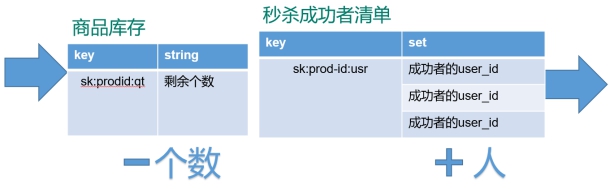
Redis_事务_秒杀案例
- 解决计数器和人员记录的事务操作
- Redis事务--秒杀并发模拟
使用工具ab模拟测试
CentOS6 默认安装
CentOS7需要手动安装
-
联网:yum install httpd-tools
- 无网络
(1) 进入cd /run/media/root/CentOS 7 x86_64/Packages(路径跟centos6不同)
(2) 顺序安装
apr-1.4.8-3.el7.x86_64.rpm
apr-util-1.5.2-6.el7.x86_64.rpm
httpd-tools-2.4.6-67.el7.centos.x86_64.rpm
-
测试及结果
- 通过ab测试
vim postfile 模拟表单提交参数,以&符号结尾;存放当前目录。
内容:prodid=0101&
ab -n 2000 -c 200 -k -p ~/postfile -T application/x-www-form-urlencoded
http://192.168.2.115:8081/Seckill/doseckill
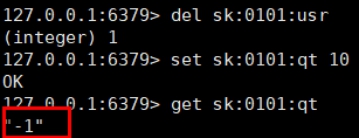
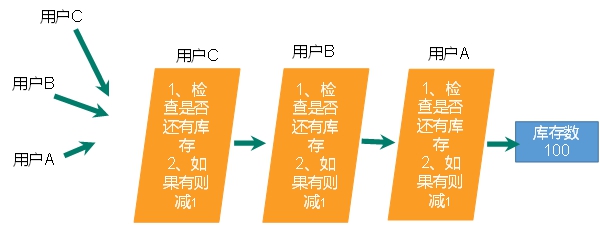
- 超卖
 |
 |
|---|
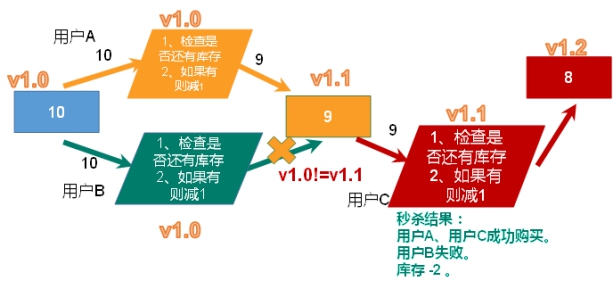
- 超卖问题
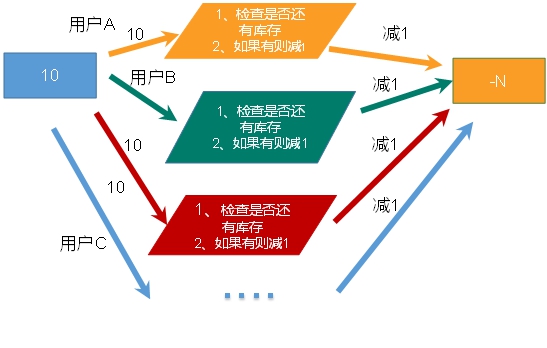
- 利用乐观锁淘汰用户,解决超卖问题。
| //增加乐观锁 jedis.watch(qtkey); //3.判断库存 String qtkeystr = jedis.get(qtkey); if(qtkeystrnull || "".equals(qtkeystr.trim())) { System.out.println("未初始化库存"); jedis.close(); return false ; } int qt = Integer.parseInt(qtkeystr); if(qt<=0) { System.err.println("已经秒光"); jedis.close(); return false; } //增加事务 Transaction multi = jedis.multi(); //4.减少库存 //jedis.decr(qtkey); multi.decr(qtkey); //5.加人 //jedis.sadd(usrkey, uid); multi.sadd(usrkey, uid); //执行事务 List<Object> list = multi.exec(); //判断事务提交是否失败 if(listnull || list.size()==0) { System.out.println("秒杀失败"); jedis.close(); return false; } System.err.println("秒杀成功"); jedis.close(); | 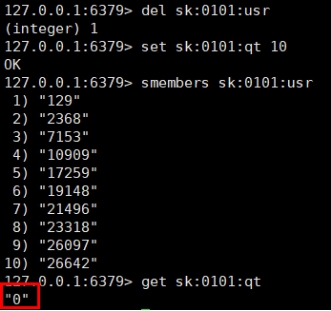  |
|---|
-
继续增加并发测试
- 连接有限制
ab -n 2000 -c 200 -k -p postfile -T 'application/x-www-form-urlencoded'
http://192.168.140.1:8080/seckill/doseckill

增加-r参数,-r Don't exit on socket receive errors.
ab -n 2000 -c 100 -r -p postfile -T 'application/x-www-form-urlencoded'
http://192.168.140.1:8080/seckill/doseckill
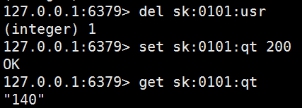
- 已经秒光,可是还有库存
ab -n 2000 -c 100 -p postfile -T 'application/x-www-form-urlencoded'
http://192.168.137.1:8080/seckill/doseckill
已经秒光,可是还有库存。原因,就是乐观锁导致很多请求都失败。先点的没秒到,后点的可能秒到了。
- 连接超时,通过连接池解决

- 连接池
节省每次连接redis服务带来的消耗,把连接好的实例反复利用。
通过参数管理连接的行为
代码见项目中
-
链接池参数
-
MaxTotal:控制一个pool可分配多少个jedis实例,通过pool.getResource()来获取;如果赋值为-1,则表示不限制;如果pool已经分配了MaxTotal个jedis实例,则此时pool的状态为exhausted。
-
maxIdle:控制一个pool最多有多少个状态为idle(空闲)的jedis实例;
-
MaxWaitMillis:表示当borrow一个jedis实例时,最大的等待毫秒数,如果超过等待时间,则直接抛JedisConnectionException;
-
testOnBorrow:获得一个jedis实例的时候是否检查连接可用性(ping());如果为true,则得到的jedis实例均是可用的;
-
解决库存遗留问题
- LUA脚本
-

Lua 是一个小巧的脚本语言,Lua脚本可以很容易的被C/C++
代码调用,也可以反过来调用C/C++的函数,Lua并没有提供强大的库,一个完整的Lua解释器不过200k,所以Lua不适合作为开发独立应用程序的语言,而是作为嵌入式脚本语言。
很多应用程序、游戏使用LUA作为自己的嵌入式脚本语言,以此来实现可配置性、可扩展性。
这其中包括魔兽争霸地图、魔兽世界、博德之门、愤怒的小鸟等众多游戏插件或外挂。
- LUA脚本在Redis中的优势
将复杂的或者多步的redis操作,写为一个脚本,一次提交给redis执行,减少反复连接redis的次数。提升性能。
LUA脚本是类似redis事务,有一定的原子性,不会被其他命令插队,可以完成一些redis事务性的操作。
但是注意redis的lua脚本功能,只有在Redis 2.6以上的版本才可以使用。
利用lua脚本淘汰用户,解决超卖问题。
redis 2.6版本以后,通过lua脚本解决争抢问题,实际上是redis
利用其单线程的特性,用任务队列的方式解决多任务并发问题。
本文来自博客园,作者:Cn_FallTime,转载请注明原文链接:https://www.cnblogs.com/CnFallTime/p/16151079.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号