【题解】Solution Set - NOIP2024集训Day20 DP常⻅模型1「序列」
【题解】Solution Set - NOIP2024集训Day20 DP常⻅模型1「序列」
https://www.becoder.com.cn/contest/5503
「JOI 2022 Final」Let's Win the Election
挺典的类型,先贪心排序,然后 dp。
考虑两个州。
分讨一下:(FAKE
-
如果需要
-
如果需要
显然选
直接不太好贪,还是得先想点性质。
先把不去的州删去,最后的决策一定是 BBBBBBAAAAAA。
如果是 BBBABBB,中间的 A 移到末尾一定不劣。
所以我们考虑枚举 B 的个数,显然如果我们确定了那些选了 B,肯定会优先选择
先按
然后还需要一次 dp。注意到选票个数其实是不必要的(因为一定是前缀)只需要定义
最后再枚举一下最后一个
「JOISC 2015 Day1」Growing Vegetables is Fun 2
最后状态下,能结果的那些草一定是山峰状的。
可以前后分别跑一遍上升的,然后枚举最高点。
考虑一个最简单的 dp,
有转移:
但是这样是错的。因为我们并不能保证在
比如:
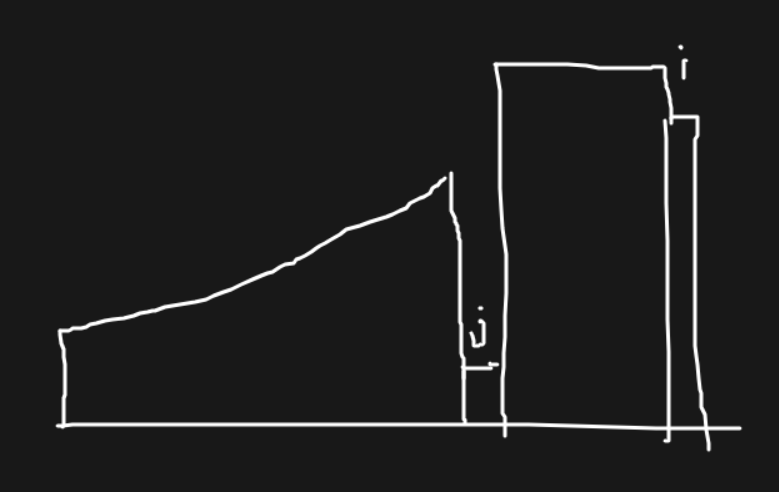
这个时候肉眼可见,我们不会去选
实际上是可以修正的。错其实是因为
另解:(当时以为整个做法都错了,然后就换解法了。
回到最原始的想法:按照值域来设计状态。
有转移:
这个转移对了。bf
发现最后两个其实只是对上一次的状态区间修改,而第一个只需要查询一下前缀最大值,然后单点修改就行了。
考虑用线段树维护第二维,时间复杂度
「美团 CodeM 复赛」配对游戏
假期望。拆贡献,答案就应该是每个人留下来的概率求和。
考虑求出每个人被删去的概率
对于
那么
转移如下:
所以就死了,因为状态设计的不完备,转移的时候会重复。
https://www.becoder.com.cn/submission/2594703
转移见代码。
「PA2021 Round1 A」Od deski do deski
考虑满足条件的序列有什么性质。
我们把每对相同元素的位置看成一个区间,那么我们就是要求这些区间中的其中一些,并集是
dp[0] = 1;
for (int i = 1; i <= n; i++)
for (int j = 1; j < i; j++)
if (a[i] == a[j])
dp[i] |= dp[j-1];
这个性质好像有跟没有一样。😥
为了避免重复统计,我们钦定每个状态从分段数最少的来转移。
所以定义
还是没用,很难保证分段数最小是哪个。
借鉴题解的定义:
这个状态定义的是真的妙。
根据刚才那个 check 的 dp 来定义(?(也算不上吧。
答案显然是
https://www.luogu.com.cn/article/38i5rv5t
真的妙,完全不知道怎么想到的。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话