
实战丨打造一个双端自动发布的博客体系(上)
项目背景
对于很多开发小GG 来说,云开发不仅仅是一个云服务,更是帮助他们实现心中梦想,脑中灵感的利器,这不,这就有个开发 GG 拿云开发结合 Git 打造了一个可以自动发布、构建,并进行多端发布的博客体系。只要简单写一篇文章,就可以实现一次编写,多平台自动发布。

本文通过对markdown内容发布、同步、展示由浅入深的分析与实践,构建出一个相对可靠的博文编写、知识沉淀工作流,精简工具的同时提升阅读体验,更好的记录、分享和交流传播。
需求分析
- 专注于用Markdown写文档,为了实现正常解析,使用通用语法支持;
- 一端书写,多端同步:小程序、静态站点,高效的持续集成;
- 快速的资源加载,优雅的排版。
但是要明晰项目边界:
- 不需要满足随时随地写文章,因为随时随地写的大部分是随笔、记录一类的帖子,若要呈现出来,必然要经过整理;
- 不需要自定义主题风格,博客就主体业务类型(除了评论、点赞、收藏)而言受众个性色彩不强。
- 控制台入口:云开发控制台
系统设计
1.概要设计
1.1 架构设计
主要思路是本地编辑文章,通过git进行增删改管理,通过云端同步构建到小程序和静态站点。因此,这种思路适用于静态构建markdown文档的框架如hexo、jekyll等。
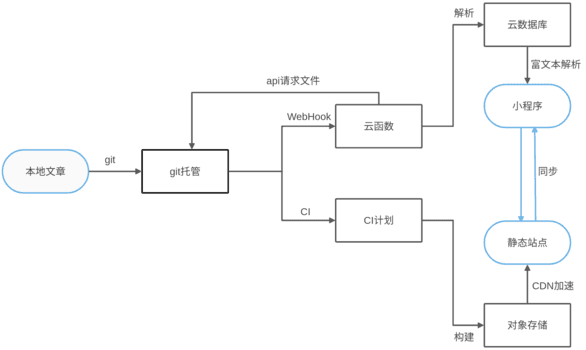
1.2 技术选型与开发框架
在开发框架上,由于首次应用于微信小程序,可能存在未知问题,故使用原生开发,不使用多端或其他预编译框架。在小程序UI上,参考但不依赖WeUI组件库,因由于封装不必要的特性可能造成代码包的冗余。
| 类型 | 方案 | 备注 |
|---|---|---|
| 代码托管 | Coding | github api访问较大概率慢且不稳定 |
| 云开发 | 腾讯云TCB | 含小程序云开发服务 |
| 持续集成 | Coding CI | 使用Jenkinsfile定义pipeline |
| 静态托管 | 腾讯云COS | 直接使用云开发提供的静态网站托管,使用对象存储配合内容分发加速。 |
| Markdown解析 | markdown-it | 也可使用markdjs,但markdown-it支持拓展插件 |
| 富文本渲染 | parser | 比原生rich-text功能丰富且效果稳定 |
1.3 开发规范
有以下几点原则:
- 渐进式,先实现基本功能,再考虑抽离和组件化;
- 能用简单的逻辑实现就不抽离组件,能使用成熟库就不自行创建组件,能通过配置或迁就性使用就不修改外部库以保证平滑更新;
- 对于功能实现的方式,要考虑服务角色,权衡计算复杂度、网络延时和用户感知程度:
小程序端做简单计算
- canvas绘制海报
- 基本格式转换
服务端(云开发)做复杂处理,非实时性计算,或可预生成的内容
- markdown转html
- 目录
- 对于读写数据库,尽量将写操作放在云函数中。
2 详细设计
2.1 数据源
安全校验,保证云函数触发来源及方式可信:
// 查看请求头
if (!req.headers['user-agent'].includes('Coding.net Hook') ||
!('x-coding-signature' in req.headers) || req.headers['x-coding-signature'].indexOf('sha1=')
!('x-coding-event' in req.headers) || 'POST' !== req.httpMethod ) {
return false;
}
// 计算和比对签名
const theirSignature = req.headers['x-coding-signature'];
const payload = req.body;
const secret = process.env.HOOKTOKEN;
const ourSignature = `sha1=${crypto.createHmac('sha1', secret).update(payload).digest('hex')}`;
return crypto.timingSafeEqual(Buffer.from(theirSignature), Buffer.from(ourSignature));
在每次commit推送新的代码时,WebHook会push以下信息(限于篇幅,略去非必要信息)
{
"ref": "refs/heads/master",
"commits": [
{
"id": "8a175afab1cf117f2e1318f9b7f0bc5d4dd54d45",
"timestamp": 1592488968000,
"author": {
"name": "memakergytcom",
"email": "me@makergyt.com",
"username": "memakergytcom"
},
...
]}
],
"head_commit":{
"added": [
"source/_drafts/site.md"
],
"removed": [],
"modified": [
"package.json",
"scripts/fix.js",
"source/_posts/next.yml",
"source/_posts/typesetting.md"
]
},
"pusher",
"sender",
"repository"
}
保持最新状态故关注"head_commit"中的added,removed和modified。这些信息包含了本次提交产生的变更,可以基于遍历这些变更状态,同步云数据库。但由于可能包含了非文章文件的变更,也可能非目标分支,故需要筛选:
if ('refs/heads/' + branch === ref) {
if (filePath.indexOf(dirPrefix) || filePath.slice(-3) !== '.md') { // 路径前缀和文章后缀
continue;
}
}
要建立数据库文件与git仓库文件的关联,由于每次commit的文件没有唯一id信息,可以通过文件名来建立联系,将文件名作为slug字段(主键)
let slug = filePath.match(new RegExp(dirPrefix + "([\\s\\S]+)\\.md"))[1];
由于Push 事件不包含文件内容,需要通过api发起请求
await axios({
url: `${baseUrl}/${branch}/${filePath}`,
method: 'get',
headers: {
'Authorization': `token ${process.env.CODINGTOKEN}` // 个人令牌
}
});
2.2 数据处理
提取文章信息:
由于要求在markdown开头通过yaml格式写明基本信息,故在获取到文件内容(String)后需要提取。
const matter = require('hexo-front-matter');
let { title, date, tags, description, categories, _content, cover } = matter.parse(data);
其中cover字段(封面图)也可不声明,而通过文章首图来获取
let cover = _content.match(/!\[.*\]\((.+?)\)/);
markdown解析html:
小程序端环境与传统网页有区别,让markdown渲染在本地进行,其中还需要先转为html。为了减少渲染时间,这一步在云端提前进行:
const md = require('markdown-it')({
html: true,// 允许渲染html
}).use(require('markdown-it-footnote')) // 通过脚注引用生成参考文献
生成目录时,为了便于自定义和保持一致,章节自行标号。为了便于操作,目录不会解析到主体html中。而markdown-it-anchor插件会使用header的值作为id,但id不能以数字开头,不能含中文及encodeURIComponent(中文),但可以含-,需进行转换。
// 为<h>标签插入id
id = 'makergyt-' + crypto.createHash('md5').update(title).digest('hex');
// 获取所有h2-h4生成目录列表
const { tocObj } = require('hexo-util');
const data = tocObj(str, { min_depth:2, max_depth: 4 });
2.3 数据同步
在小程序的文档中,触发云函数可以通过 http api(invokeCloudFunction)的方式。但是invokeCloudFunction需要关键的access_token,需要两小时内刷新获取,webhook无法提前获知。考虑设置中控服务器统一获取和刷新 access_token,webhook首先向中控服务器发起请求,再向云函数请求,但这样显然是不可能的,因其只能push一个地址一次,没有上下文。其间再加一个中间函数,那么这个中间函数又放在哪里,如何请求...(同样需要access_token)
这时,在云开发控制台,发现可以直接通过"云接入HTTP触发方式"触发云函数,这样就可以直接该地址作为WebHook的Url。但需要关注业务和资源安全[1],上文在处理webhook push事件时已经做了安全检验,可以再将Coding的request domain加入到WEB安全域名列表中。
获取到文章信息和内容后就可以同步到云数据库的相应集合中,这里循环中使用async/await遍历,为了在每个调用解析之前保持循环,只使用for...of进行异步[2]。
for (const file of added) {
await db.collection('sync_posts').add({
data
})
}
for (const file of modified) {
await db.collection('sync_posts').where({
slug
}).update({
data
})
}
for (const file of removed) {
await syncPosts.where({
slug
}).remove();
}

2.4 文本渲染
几乎不太可能将原内容原封不动显示出来, 经过markdown-it渲染后的html字符串没有插入任何样式,直接测试(组件根据标签默认提供样式)效果如下:
| 方案 | 效果 |
|---|---|
| rich-text | 代码块缺失,长内容被截断 |
| wxparser | 间距过大,表格、代码块被截断 |
| towxml | 代码块被截断 |
| wemark | 代码块与引用部分不换行拉宽 |
| Parser | 表格溢出 |
Tips: 注意到腾讯Omi团队开发的小程序代码高亮和markdown渲染组件Comi,实际上采用模板引入的方式使用。考虑随后实测效果和对比渲染速度。
相比之下,都会出现溢出组件边界,产生横向滚动条问题。在使用上,存在不支持解析style标签缺陷[3]而Parser可以通过控制源html样式的方法解决这种问题
var document = that.selectComponent("#article").document;
document.getElementsByTagName('table').forEach(tableNode => {
var div=document.createElement("div");
div.setStyle("overflow", "scroll");
div.appendChild(tableNode);
div._path = tableNode._path;
tableNode = div;
});
同样可以预先设定html中标签样式来影响渲染效果,这样就可以改变字体大小、行高、行间距等,以适应移动端阅读。
//post.wxml
<parser id="article" tag-style="{{tagStyle}}"/>
// post.js
tagStyle: {
p: 'font-size: 14px;color: #353535;line-height: 2;font-family: "Times New Roman";',
h2: 'font-size: 18.67px;color: #000;text-align:center;margin: 1em auto;font-weight: 500;font-family: SimHei;',
h3: 'font-size:16.33px;color: #000;line-height: 2em;font-family: SimHei;',
h4: 'font-size:14px;color: #000;font-family: SimHei;',
}
对于代码高亮,使用prism,引入到该组件中。
const Prism = require('./prism.js');
...
highlight(content, attrs) {
content = content.replace(/</g, '<').replace(/>/g, '>').replace(/quot;/g, '"').replace(/&/g, '&'); // 替换实体编码
attrs["data-content"] = content; // 记录原始文本,可用于长按复制等操作
switch (attrs[lan]) {
case "javascript":
case "js":
return Prism.highlight(content, Prism.languages.javascript, "javascript");
}
}
而对于数学公式Latex,渲染引擎主要有两种:
| 引擎 | 特点 |
|---|---|
| mathjax | 语法丰富,渲染较慢 |
| katex | 支持语法较少,迅速,只能输出mathml或html,需要搭配其CSS and font files使用 |
当然,这两种都是网页客户端渲染,在小程序端天生不可用,考虑采用服务端渲染。问题有:
- 服务端渲染如果使用外部接口,需encodeUrl(公式),但内部
\被转义消失,需要\\,replace(/\/g,'\')无效 - 服务端渲染如果使用mathjax-node,其依赖项mathjax版本^2.7.2,需将所有
\替换为\\,会经常性出现SVG - Unknown character: U+C in MathJax_Main,MathJax_Size1,MathJax_AMS, 矩阵解析错误TeX parse error: Misplaced & - 如何比较精准的识别markdown中特定标记的Latex,不造成误处理。
考虑在markdown解析html阶段就将其转化为<img>,也是很多内容平台采取的方式,较为可靠可控。这里使用markdown-it-latex2img插件,在书写上遵循一定的规范[^4]以避免误处理。
const md = require('markdown-it')({
html: true,// Enable HTML tags in source
}).use(require('markdown-it-latex2img'),{
style: "filter: opacity(90%);transform:scale(0.85);text-align:center;" // 优化显示样式
})
3 静态托管
为git库设置构建计划,以使每次提交后同步到对象存储。这里使用hexo作为构建框架。
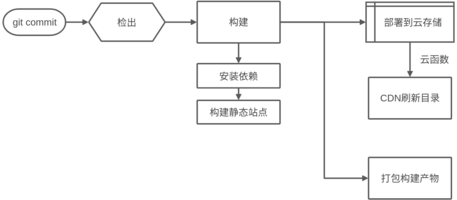
构建后自动刷新CDN,
// refresh_cdn
const Key = decodeURIComponent(event.Records[0].cos.cosObject.key.replace(/^\/[^/]+\/[^/]+\//,""));
const cdnUrl = `${process.env.CDN_HOST}/${Key}`;
CDN.request('RefreshCdnUrl', {
'urls.0': cdnUrl
}, (res) => {
...
})
总结
以上主要介绍了该博客项目的背景、技术选型、开发框架和系统设计部分的内容,介于篇幅问题,小程序登录方式的配置、分享和订阅消息功能的实现将在下期推文中详细介绍,敬请大家关注。
参考文献:
Tencent Cloud.云开发CloudBase文档[EB/OL].https://cloud.tencent.com/document/product/876/41136. 2020 ↩︎
Tory Walker.The-Pitfalls-of-Async-Await-in-Array-Loops[EB/OL].https://medium.com/dailyjs/the-pitfalls-of-async-await-in-array-loops-cf9cf713bfeb. 2020 ↩︎
金煜峰.小程序富文本能力的深入研究与应用[EB/OL].https://developers.weixin.qq.com/community/develop/article/doc/0006e05c1e8dd80b78a8d49f356413. 2019 ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号