CSAPP =1= 计算机系统漫游
思维导图
预计阅读时间:15min
阅读书籍 《深入理解计算机系统》
参考视频 【精校中英字幕】2015 CMU 15-213 CSAPP 深入理解计算机系统 课程视频
参考文章 《深入理解计算机系统(1.1)---计算机概述》
《深入理解计算机系统(1.2)---hello world的程序是如何运行的》
《深入理解计算机系统(1.3)---金字塔形的存储设备、操作系统的抽象概念》
原文链接 《旻天:
译序
《深入理解计算机系统》最大的优点是为程序员描述计算机系统的实现细节,帮助其在大脑中构建一个层次型的计算机系统。从最底层的数据在内存中的表示(如整数、浮点数表示),到流水线指令的构成,之后到虚拟存储器,编译系统,动态加载库,再到最后的用户态应用。
贯穿本书的一条主线是使程序员在设计程序时,能充分意识到计算机系统的重要性,建立起被所写的程序可能被执行的数据和指令的流程图,明白当程序的执行过程中,计算机到底都发生了什么事。从而能够设计出一个高效的、可移植的、健壮的程序。并能够更快地对程序进行排错、性能调优等。
本书的主要内容是关于计算机体系结构(高级硬件设计)与编译器和操作系统的交互,包括:
- 数据表示
- 汇编语言和汇编计算机体系结构
- 处理器设计
- 程序的性能度量和优化
- 程序的加载器、链接器和编译器
- I/O 和设备的存储器层次结构
- 虚拟存储器
- 外部存储管理
- 中断、信号和进程控制
计算机系统就像自然界的生态环境一样,对每一个部分的设计都要求它能融洽地和系统内其他部分和平相处,我们不能站在一个微观的视角去判断某个系统部件是否最优,而是应该以计算机这个宏观的整体来观察和思考。
一、计算机系统漫游
我们将通过跟踪 hello.c 程序的生命周期来对计算机系统有个简单的了解。它的生命周期从它被程序员创建开始,包括在系统上保存、运行、在屏幕上输出信息到最后的程序终止。
1.1 信息就是位(bit) + 上下文(context)
hello.c 程序的生命是从一个源程序(或者叫源文件)开始的,该源文件由程序员编写,并保存为hello.c的一个由 ASCII 构成的文本文件。
这个 hello.c 也说明了一个基本的思想:系统中所有的信息,包括磁盘文件、存储器中的程序、存储器中的数据以及网络上传输的数据,都是由一串比特(bit,或者叫做位)序列表示的,这些比特 8 个为一组,称为字节。
同样的字节序列可能表示一个整数、浮点数、字符串或者机器指令,而区分不同数据对象的唯一方法就是它们所在的上下文(context),在不同语境中表示不同的意义。
1.2 程序被其他程序翻译成不同的格式
编程语言的设计是为了让人可以读懂,然而为了让计算机可以运行这个 C 程序,就需要将每条有效的语句转换成一系列的低级机器语言指令,并以二进制磁盘文件的形式存放起来。
在 Unix 系统中,从源文件到可执行文件的转化是由编译器驱动程序完成的。
unix> gcc -o hello hello.c
编译器驱动程序的执行过程如下:
hello.c == 预处理器 ==> hello.i == 编译器 ==> hello.s == 汇编器 ==> hello.o + printf.o == 链接器 ==> hello
源程序(文本文件) (cpp) 预处理程序 (ccl) 汇编语言(文本文件) (as) 可重定位目标文件(二进制) (ld) 可执行文件
- 预处理阶段:预处理器(cpp)根据以
#开头的命令,修改原始的 C 程序。如将#include <stdio.h>中引用的头文件stdio.h的内容插入到程序的开头,来得到一个新的 C 程序。 - 编译阶段:编译器(ccl)将预处理程序
hello.i翻译成汇编程序hello.s。汇编语言程序中的每条语句都以一种标准的文本格式确切的描述了一条低级机器语言指令。汇编语言为不同高级语言的不同编译器提供了通用的输出语言。 - 汇编阶段:汇编器(as)将
hello.s翻译成机器语言指令集合。并以可重定位目标程序的格式,将结果保存到hello.o的二进制文件中。 - 链接阶段:如果程序调用了一下标准 C 库中的函数,如
printf, 而该函数存在于一个单独的名为printf.o的可重定位目标程序文件中。因此就必须以某种方式将其并入到我们的hello.o文件中并得到最终的可执行目标文件hello。
1.3 了解编译系统如何工作是大有益处的
对于像 hello.c 这样的简单程序,我们可以依靠编译系统生成正确有效的机器代码。但还是有一些重要的原因促使程序员必须知道编译系统是如何工作的。
- 优化程序性能:比如,
- (开关)一个 switch 是不是总比一系列的 if-then-else 语句要高效?
- (循环)while循环比do循环更有效吗?
- (数组&指针)指针引用比数组索引更有效吗?
- (函数)一个函数调用的代价有多大?
- (参数)相对于通过引用传递过来的参数求和,为什么用本地变量求和的循环会快很多倍?
- 为什么两个功能相近的循环,运行时间会有巨大差异?
- 理解链接时出现的错误:比如,
- (引用)链接器报告说它无法解析一个引用。
- (变量)静态变量和全局变量的区别。
- (作用域)在不同的文件中定义相同名字的两个全局变量会怎样。
- (链接库)静态库和动态库的区别。
- 为什么命令行上排列库的顺序会对程序有影响。
- 为什么有些链接错误直到运行时才出现。
- 避免安全漏洞:近年来的缓冲区溢出错误造成了大多数网络和服务器上的安全漏洞。错误原因大多是程序员忽视了编译器用来为函数产生代码的堆栈规则。
1.4 处理器读并解释存储在存储器中的指令
之前编写的 hello 程序,源码和可执行文件都已经存放在了磁盘上。执行我们之前编写的 hello 小程序,就可以在 shell 中看到程序的输出:
unix> ./hello
hello, world
存放在磁盘的程序是如何运行,并在 shell 中打印信息的呢?这时就需要理解一个典型系统的硬件组织。
1.4.1 系统的硬件组成
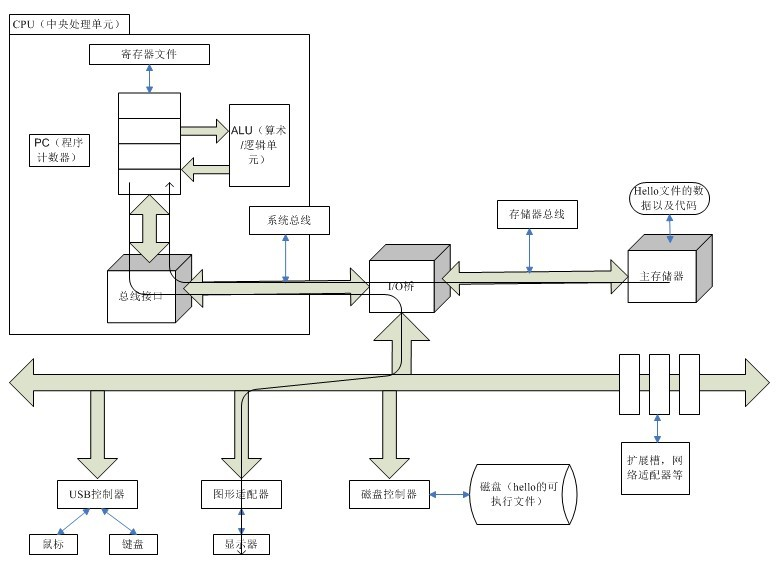
如图展示的是 Inter Pentium 系统产品组的模型,但和其他系统也都大同小异。
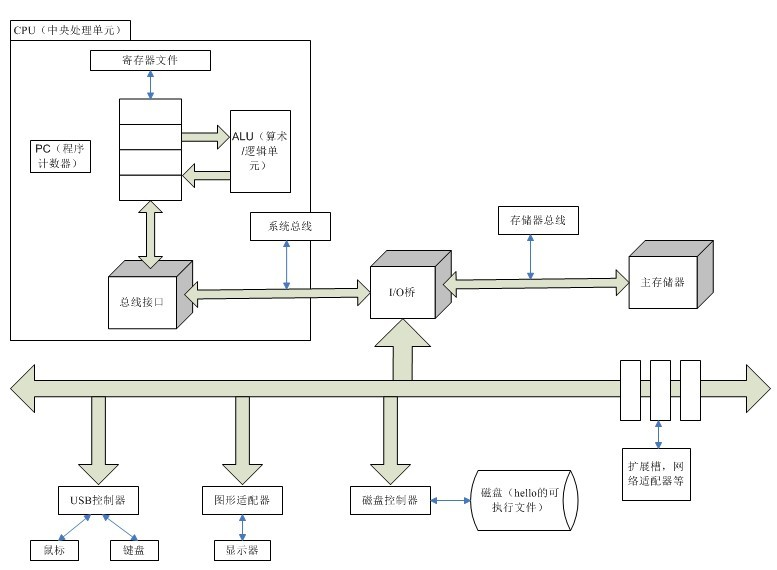
- CPU: 中央处理单元
- ALU:算术/逻辑单元
- PC:程序计数器
- USB:通用串行总线
总线
贯穿整个系统的一组电子管道,称作总线。它携带信息字节并负责在各个部件间传递。
通常总线被设计成传递定长的字节块,也就是字(word)。字中的字节数(即字长)是一个基本的操作系统参数。
像我们平时买电脑说的 64 位处理器,指的就是 CPU 总线字长为 8 字节(64 位)的 CPU。而装系统时的 64 位操作系统,指的是可以完全的利用 CPU 64 位寻址能力的操作系统,当然也可以在 64 位 CPU 的机器上装 32 位的操作系统,只不过会大大浪费 CPU 寻址能力。
I/O 设备
I/O(Input/Output,输入/输出)设备是系统与外界联系的通道。如用户用来输入的鼠标、键盘;系统用来给用户输出信息的显示器;以及长期存储用户程序和数据的磁盘驱动器。
每个 I/O 设备都是通过一个控制器或适配器与 I/O 总线连接起来的。区别是控制器是 I/O 设备本身或系统主电路板上的芯片组。而适配器则是一块插在主板插槽上的卡。
主存
主存是一个临时存储设备。在处理器执行程序时,它被用来存放程序和数据。
物理上来说,主存就是一组 DRAM(动态随机存取存储器)芯片组成。
逻辑上来说,存储器是由一个线性的字节数组组成的,每个字节都有自己唯一的地址(从 0 开始的数组索引)。
一般来说,组成程序的每条机器指令都由不定量的字节构成,每种语言也有所不同。比如,运行在 Inter 上的 Linux 机器中,short 类型数据为 2 个字节,而 int、float 为 4 个字节。
处理器
中央处理单元(CPU)简称处理器,是解释(或执行)存储在主存中指令的引擎。
处理器细分,又有:
程序计数器(PC)
处理器的核心是程序计数器(PC)的字长大小的存储设备(或寄存器)。在任何时间点上,PC 都指向主存中的某条机器语言指令的地址。
从系统启动开始直至断电,处理器都在重复执行相同的简单任务,即:
- 从 PC 当前指向的地址处读取指令
- 解释指令中的位
- 执行指令指示的简单操作
- 更新 PC 到下一条指令(两条指令并不一定相邻)
- 重复执行 1.
寄存器文件
寄存器文件是一个很小的高速存储设备,由一些字长大小的寄存器组成。这些寄存器每个都有唯一的名字。
算术逻辑单元(ALU)
ALU 计算新的数据和地址值。
处理器在指令的要求下可能会有以下操作:
- 加载:从主存拷贝一个字节或一个字到寄存器,并覆盖寄存器原来的值
- 存储:从寄存器拷贝一个字节或一个字到主存某个位置,并覆盖原来的值
- 更新:拷贝两个寄存器的值到 ALU,ALU将两数相加并将结果存放到一个寄存器中,并覆盖原来的值
- I/O 读:从 I/O 设备中拷贝一个字节或者一个字到寄存器
- I/O 写:从寄存器中拷贝一个字节或一个字到一个 I/O 设备
- 转移:从指令本身抽取一个字,并将这个字拷贝到 PC 中,并覆盖原来的值
1.4.2 执行 hello 程序流程
现在我们已经初步了解了程序的编译过程和计算机硬件的组成,但一台计算机又是如何执行 hello 这个可执行文件的呢?
大体流程可以参考左潇龙大佬重绘的这版高清图片:
1.shell 监听用户输出,字符从输入设备经由总线到寄存器,在从寄存器保存到主存,并在接受到回车后执行相关指令
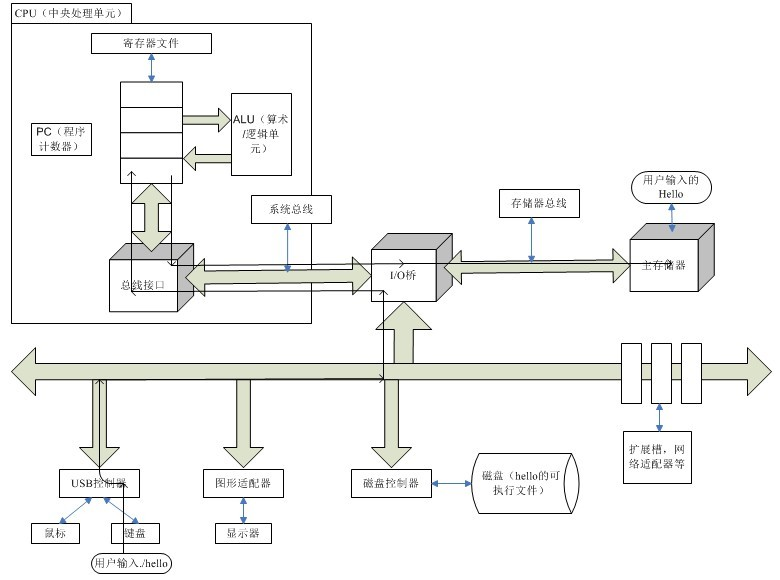
2.shell 执行一系列指令,将 hello 可执行文件的代码和数据经过总线和 I/O 桥从磁盘 copy 到主存,完成程序的加载(可以利用 DMA 绕过 CPU 直接将硬盘数据加载进主存)
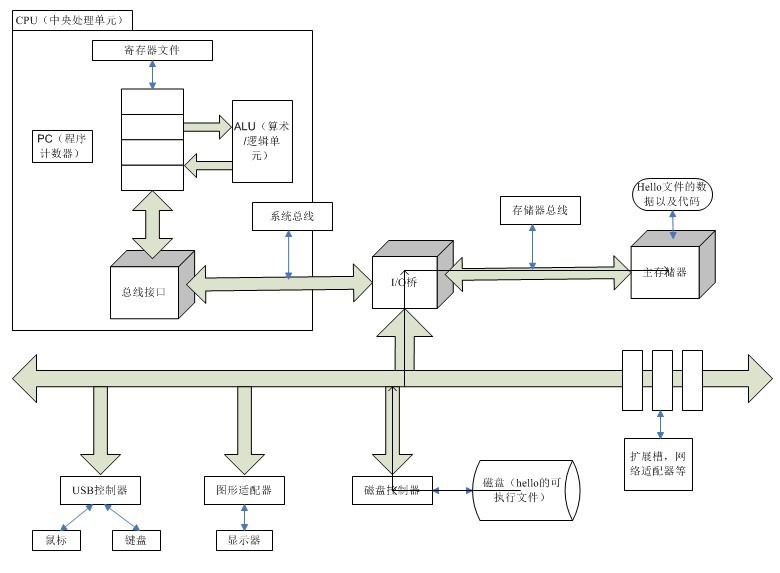
3.CPU 通过总线将主存中的指令逐条加载进 CPU 并翻译程序指令,对于需要打印的字符,通过总线传递给显示器显示
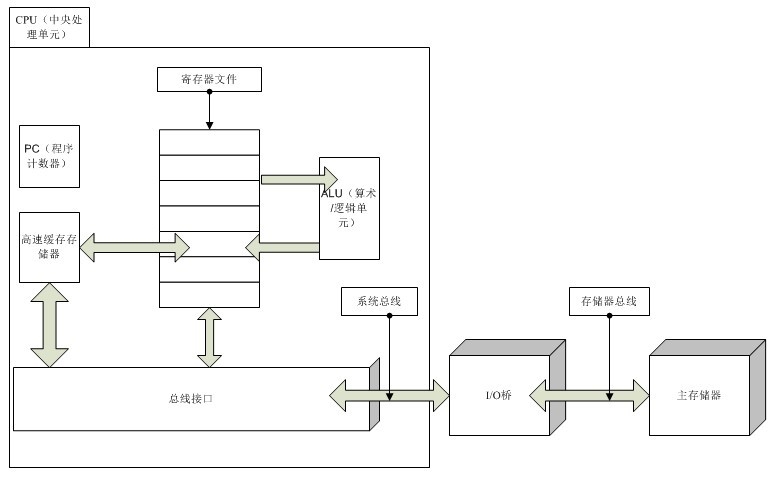
1.5 高速缓存
从上面例子我们可以看到,系统有大量的数据移动操作。比如开始的 hello 执行程序存放在磁盘上,之后程序加载被拷贝到主存,然后程序执行又把程序逐条拷贝到处理器,而对于其中的打印字符,又把字符拷贝到了显示器终端。因此对于这几步拷贝的次数和速度还是有很大的优化空间的。
硬件开发商为了减少这种数据传输的时间成本,而高速缓存应运而生。
高速缓存被放置在处理器当中,与处理器中的寄存器文件直接进行数据交换,这样大大减少了数据传输的时间成本,使得程序的运行速度可以得到数倍的提升。
1.6 形成层次结构的存储设备
计算机领域有句名言:“计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决”。
而在处理器和较慢的存储器中间插入一个更快的存储器这种想法也成为了一个普遍的概念。但硬件厂商经不起一个真理《越快的设备造价越高昂》,所以就需要在更快和更大之间产生一个平衡。
所以存储结构就变成了如下的金字塔结构。
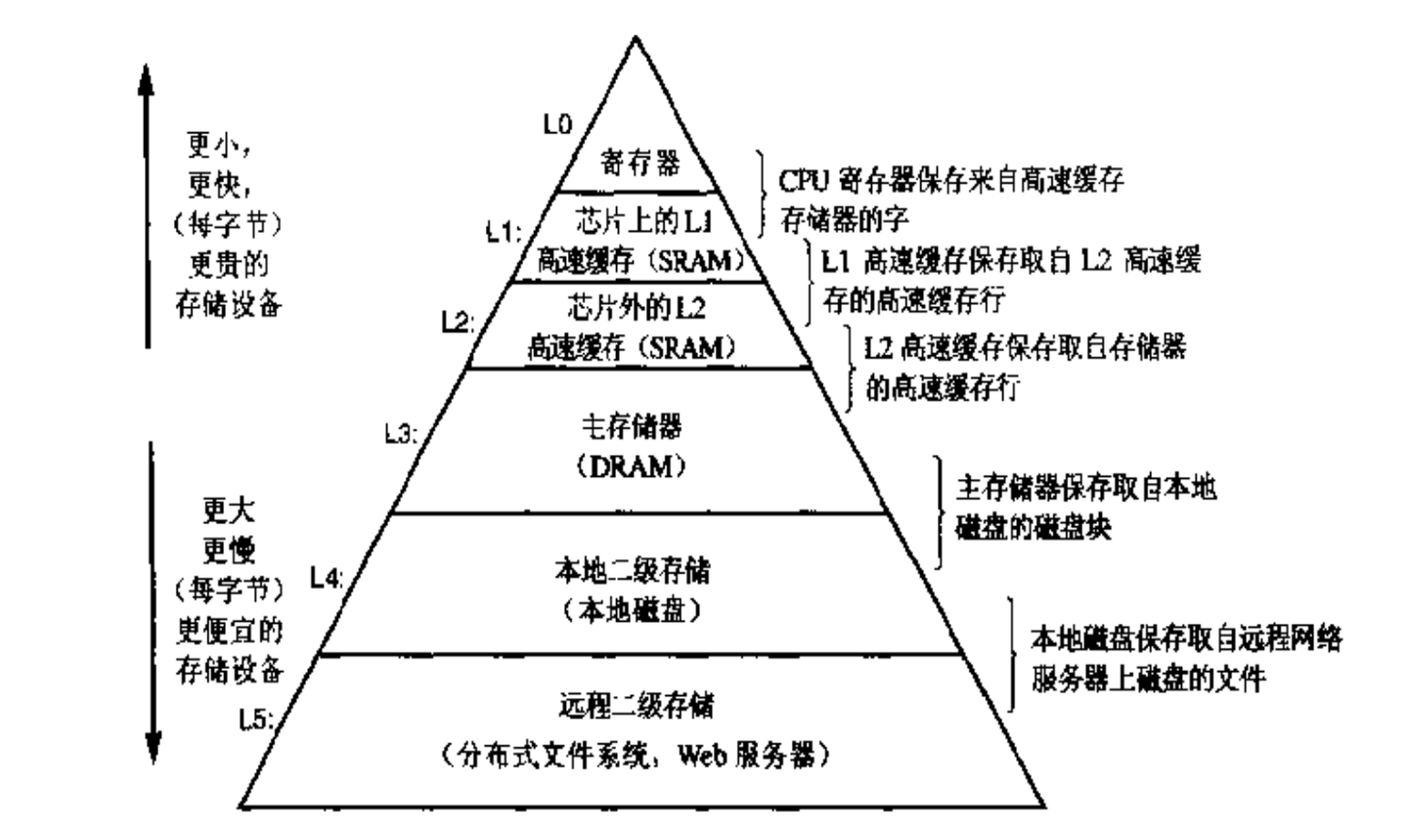
越靠近CPU的设备越小越快,但造价越高昂。
越远离CPU的设备越大越慢,但造价越便宜。
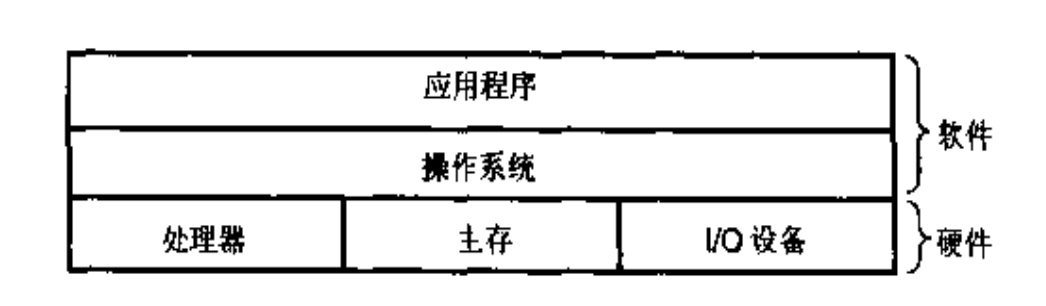
1.7 操作系统管理硬件
为了简化程序开发者使用硬件资源,计算机又产生了一个新的中间件 ———— 操作系统。
操作系统就是帮助应用软件控制系统硬件的系统软件,在应用软件和系统硬件之间扮演者一个协调和管理的角色。
1.7.1 分层视图
1.7.2 基本功能
- 防止硬件被失控(非法)的应用程序滥用,保护计算机
- 为不同硬件提供一套简单一致的接口
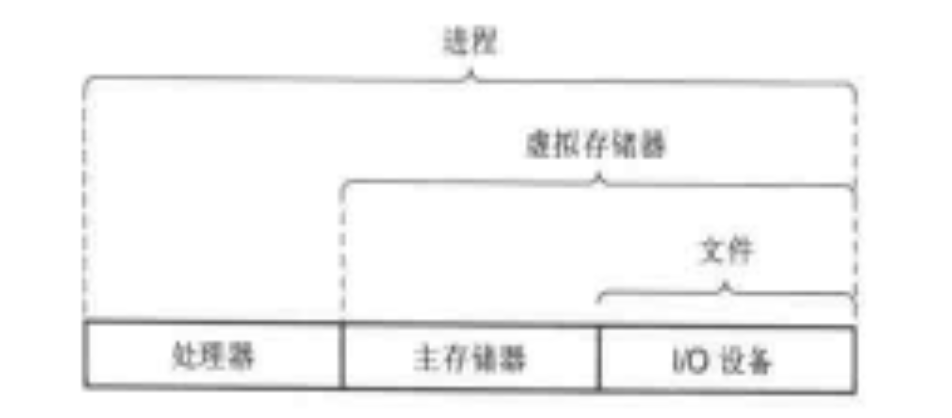
文件
文件是操作系统对硬件中 I/O 设备的抽象,它只是一组字节序列。任何 I/O 设备,如磁盘、键盘、显示器、甚至网络都可以看成是一个文件。
虚拟存储器
虚拟存储器是一个抽象概念,为每个进程提供一个好似独占了主存的假象。由主存和文件组成。
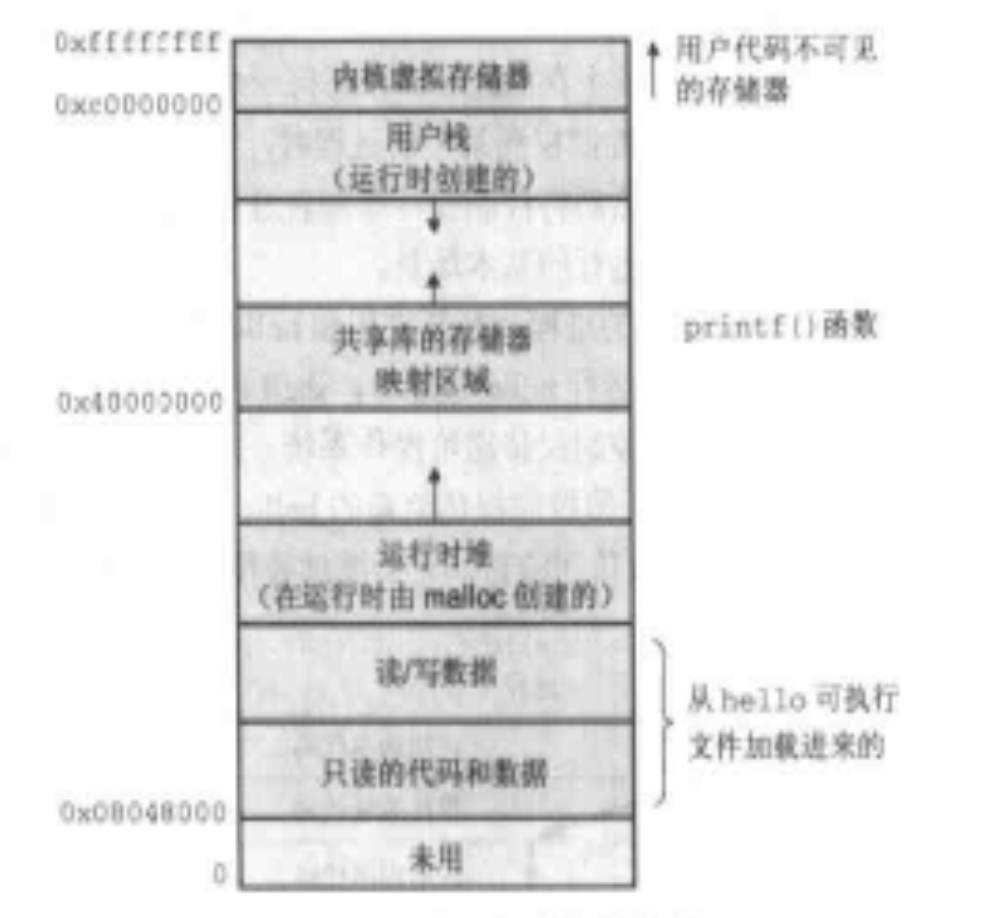
可以看到虚拟存储器有五个区域构成,从下往上(地址从小往大)依次是:
程序代码和数据(只读和读写两部分)
就是程序代码和数据,全局变量
运行时堆
是运行时可以动态扩展的一部分内存区域,它可以由malloc和free这样的标准库函数操作
共享库存储
用于存放共享库的代码和数据
用户栈
与函数的执行有密切的关系
内核虚拟存储
内核是操作系统的一部分
进程
进程是操作系统对一个正在运行的程序的抽象,为程序提供一个好似独占了整个计算机的假象。由处理器和虚拟存储器组成。
但实际上一个计算机会有多个进程同时执行,我们称之为并发运行。每个进程交替获得 CPU 时间并执行响应指令。
操作系统实现这种交错执行的机制称之为上下文切换(context switching)。而保存进程所需的所有状态信息就称为上下文(context)。
线程
在现代系统中,一个进程实际上可以由多个称为线程的执行单元组成。每个线程都运行在进程的上下文中,并共享同样的代码和全局数据。
线程可以比进程更容易的共享数据,因此也更加高效。
1.8 利用网络系统和其他系统通信
目前我们一直将系统视为一个孤立的个体,但实际上现代计算机经常通过网络和其他系统连接到一起。
而前面我们也说过,网络本就可以视为是一个 I/O 设备,它也可以被看做是一系列的字节序列。网络适配器的作用就是给计算机输入一堆被传送过来的字节序列,这里面可能包括图片、文字,甚至可能是代码等等。
总结
计算机是由硬件和软件共同组成的。
软件是由程序指令和数据组成的,由最初的 ASCII 文本逐步翻译成可执行文件,可执行文件在计算机都是以二进制的形式保存的,二进制指令依据不同的上下文有不同的解释方式。
操作系统将存在磁盘中的程序加载到主存中,CPU 再读取并解释主存中的二进制指令,产生程序期望的硬件效果。
因为计算机花费大量时间在存储器和 I/O 设备到 CPU 之间的数据拷贝上,所以形成了金字塔模式的存储模型。
操作系统内核是应用程序和硬件之间的媒介,通过操作系统提供的抽象接口,方便应用程序可以控制不同厂商的同种硬件。
完
《本章完》,期待各位道友指出文章的不足之处。
转载请注明出处~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号