
TCP长连接实践与挑战
 本文介绍了tcp长连接在实际工程中的实践过程,并总结了tcp连接保活遇到的挑战以及对应的解决方案。
本文介绍了tcp长连接在实际工程中的实践过程,并总结了tcp连接保活遇到的挑战以及对应的解决方案。

👉 点这里立即申请

本文介绍了tcp长连接在实际工程中的实践过程,并总结了tcp连接保活遇到的挑战以及对应的解决方案。
作者:字节跳动终端技术 ——— 陈圣坤
概述
众所周知,作为传输层通信协议,TCP是面向连接设计的,所有请求之前需要先通过三次握手建立一个连接,请求结束后通过四次挥手关闭连接。通常我们使用TCP连接或者基于TCP连接之上的应用层协议例如HTTP 1.0等,都会为每次请求建立一次连接,请求结束即关闭连接。这样的好处是实现简单,不用维护连接状态。但对于大量请求的场景下,频繁创建、关闭连接可能会带来大量的开销。因此这种场景通常的做法是保持长连接,一次请求后连接不关闭,下次再对该端点发起的请求直接复用该连接,例如HTTP 1.1及HTTP 2.0都是这么做的。然而在工程实践中会发现,实现TCP长连接并不像想象的那么简单,本文总结了实现TCP长连接时遇到的挑战和解决方案。
事实上TCP协议本身并没有规定请求完成时要关闭连接,也就是说TCP本身就是长连接的,直到有一方主动关闭连接为止。实现TCP连接遇到的挑战主要有两个:连接池和连接保活。
连接池
长连接意味着连接是复用的,每次请求完连接不关闭,下次请求继续使用该连接。如果请求是串行的,那完全没有问题。但在并发场景下,所有请求都需要使用该连接,为了保证连接的状态正确,加锁不可避免,如果连接只有一个,就意味着所有请求都需要排队等待。因此长连接通常意味着连接池的存在:连接池中将保留一定数量的连接不关闭,有请求时从池中取出可用的连接,请求结束将连接返回池中。
用go实现一个简单的连接池(参考《Go语言实战》):
import (
"errors"
"io"
"sync"
)
type Pool struct {
m sync.Mutex
resources chan io.Closer
closed bool
}
func (p *Pool) Acquire() (io.Closer, error) {
r, ok := <-p.resources
if !ok {
return nil, errors.New("pool has been closed")
}
return r, nil
}
func (p *Pool) Release(r io.Closer) {
p.m.Lock()
defer p.m.Unlock()
if p.closed {
r.Close()
return
}
select {
case p.resources <- r:
default:
// pool is full , just close
r.Close()
}
}
func (p *Pool) Close() error {
p.m.Lock()
defer p.m.Unlock()
if p.closed {
return nil
}
p.closed = true
close(p.resources)
for r := range p.resources {
if err := r.Close(); err != nil {
return err
}
}
return nil
}
func New(fn func() (io.Closer, error), size uint) (*Pool, error) {
if size <= 0 {
return nil, errors.New("size too small")
}
res := make(chan io.Closer, size)
for i := 0; i < int(size); i++ {
c, err := fn()
if err != nil {
return nil, err
}
res <- c
}
return &Pool{
resources: res,
}, nil
}
池的对象只需实现io.Closer接口即可,利用go缓冲通道的特性可以轻松地实现连接池:获取连接时从通道中接收一个对象,释放连接时将该对象发送到连接池中。由于go的通道本身就是goroutine安全的,因此不需要额外加锁。Pool使用的锁是为了保证Release操作和Close操作的并发安全,防止连接池在关闭的同时再释放连接,造成预期外的错误。
连接池经常遇到的一个问题就是池大小的控制:过大的连接池会带来资源的浪费,同时对服务端也会带来连接压力;过小的连接池在高并发场景下会限制并发性能。通常的解决办法是延迟创建和设置空闲时间,延迟创建是指连接只在请求到来时才创建,空闲时间是指连接在一定时间内未被使用则将被主动关闭。这样日常情况下连接池控制在较小的尺度,当并发请求量较大时会为新的请求创建新的连接,这些连接在请求完毕后返还连接池,其中的大部分会在闲置一定时间后被主动关闭,这样就做到了并发性能和IO资源之间较好的平衡。
连接保活
长连接的第二个问题就是连接保活的问题。虽然TCP协议并没有限制一个连接可以保持多久,理论上只要不关闭连接,连接就一直存在。但事实上由于NAT等网络设备的存在,一个连接即使没有主动关闭,它也不会一直存活。
NAT
NAT(Network Address Translation)是一种被广泛应用的网络设备,直观地解释就是进行网络地址转换,通过一定策略对tcp包的源ip、源端口、目的ip和目的端口进行替换。可以说,NAT有效缓解了ipv4地址紧缺的问题,虽然理论上ipv4早已耗尽,但正由于NAT设备的存在,ipv4的寿命超出了所预计的时间。公司内部的网络也是通过NAT构建起来的。
虽然NAT有如此的优点,但它也带来了一些新的问题,对TCP长连接的影响就是其中之一。我们将一个通过NAT连接的网络简化成下面的模型: 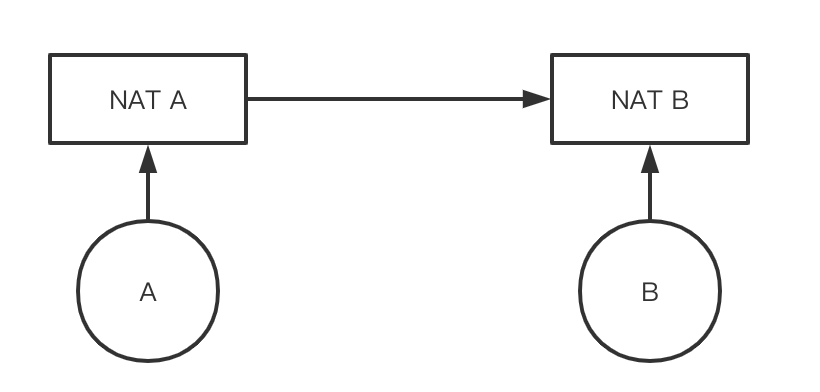
A如果想保持对B的长连接,它实际并不与B直接建立连接,而是与NAT A建立长连接,而NAT A又与NAT B、NAT B与B建立长连接。如果NAT设备任由下面的机器保持连接不关闭,那它很容易就耗尽所能支持的连接数,因此NAT设备会定时关闭一定时间内没有数据包的连接,并且它不会通知网络的双方。这就是为什么我们有时候会遇到这种错误:
error: read tcp4 1.1.1.1:8888->2.2.2.2:9999: i/o timeout
按照TCP的设计,连接有一方要关闭连接时会有“四次挥手”的过程,通过一个关闭的连接发送数据时会抛出Broken pipe的错误。但NAT关闭连接时并不通知连接双方,发送方不知道连接已关闭,会继续通过该连接发送数据,并且不会抛出Broken pipe的错误,而接收方也不知道连接已关闭,还会持续监听该连接。这样发送方请求能成功发送,但接收方无法接收到该请求,因此发送方自然也等不到接收方的响应,就会阻塞至接口超时。经过实践发现公司的NAT超时是一个小时,也就是保持连接不关闭并闲置一个小时后,再通过该连接发送请求时,就会出现上述timeout的错误。
我们上面提到连接池大小的控制问题,其实看起来有点类似NAT的超时控制,那既然我们允许连接池关闭超时的闲置连接,为什么不能接受NAT设备关闭呢?答案就是上面提到的,NAT设备关闭连接时并未通知连接双方,因此客户端使用连接请求时并不知道该连接实际上是否可用,而如果是由连接池主动关闭连接,那它自然知道连接是否是可用的。
Keepalive
通过上面的描述我们就知道怎么解决了,既然NAT会关闭一定时间内没有数据包的连接,那我们只需要让这个连接定时自动发送一个小数据包,就能保证连接不会被NAT自动关闭。
实际上TCP协议中就包含了一个keepalive机制:如果keepalive开关被打开,在一段时间(保活时间:tcp_keepalive_time) 内此连接不活跃,开启保活功能的一端会向对端发送一个保活探测报文。只要我们保证这个tcp_keepalive_time小于NAT的超时时间,这个探测报文的存在就能保证NAT设备不会关闭我们的连接。
unix系统为TCP开发封装的socket接口通常都有keepalive的相关设置,以go语言为例:
conn, _ := net.DialTCP("tcp4", nil, tcpAddr)
_ = conn.SetKeepAlive(true)
_ = conn.SetKeepAlivePeriod(5 * time.Minute)
另一个常见的保活机制是HTTP协议的keep-alive,不同于TCP协议,HTTP 1.0设计上默认是不支持长连接的,服务器响应完立即断开连接,通过请求头中的设置“connection: keep-alive”保持TCP连接不断开(HTTP 1.1以后默认开启)。
流水线控制
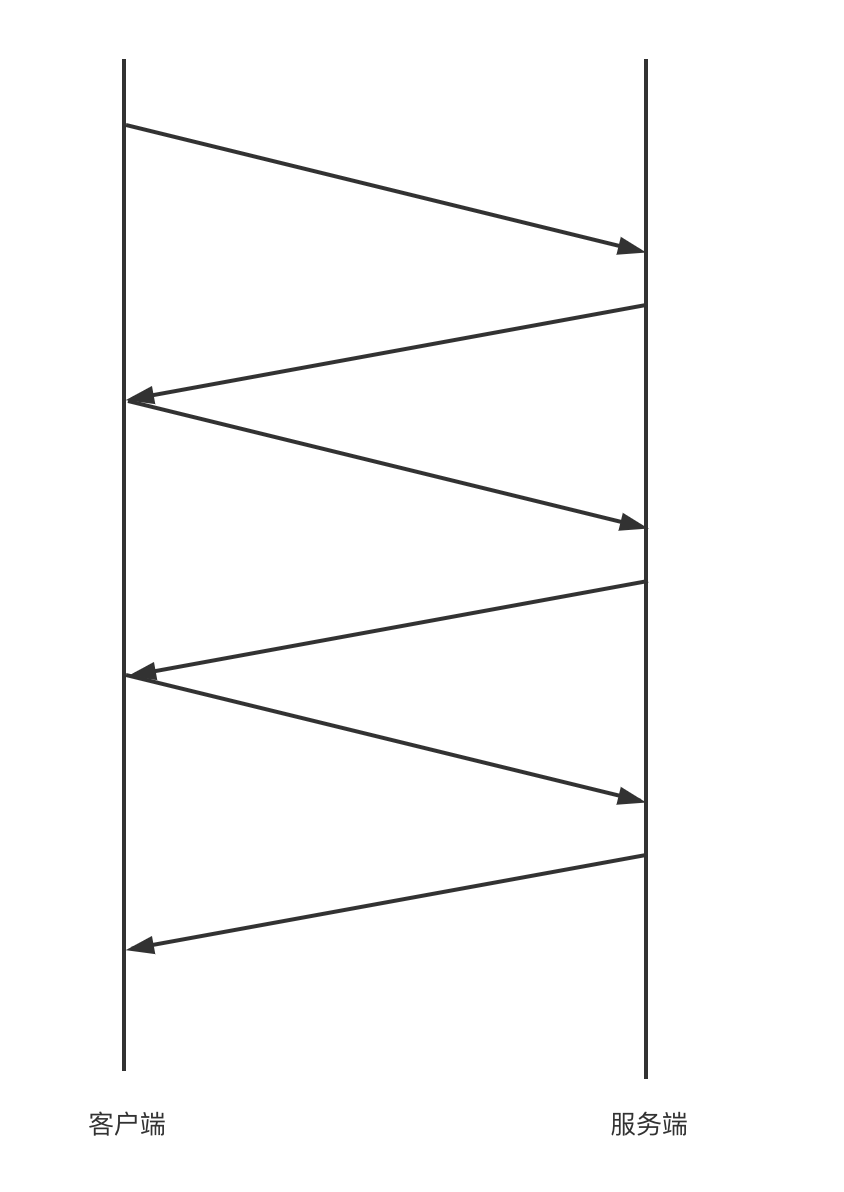
尽管使用连接池一定程度上能平衡好并发性能和io资源,但在高并发下性能还是不够理想,这是因为可能有上百个请求都在等同一个连接,每个请求都需要等待上一个请求返回后才能发出:
: 
这样无疑是低效的,我们不妨参考HTTP协议的流水线设计,也就是请求不必等待上一个请求返回才能发出,一个TCP长连接会按顺序连续发出一系列请求,等到请求发送成功后再统一按顺序接收所有的返回结果:
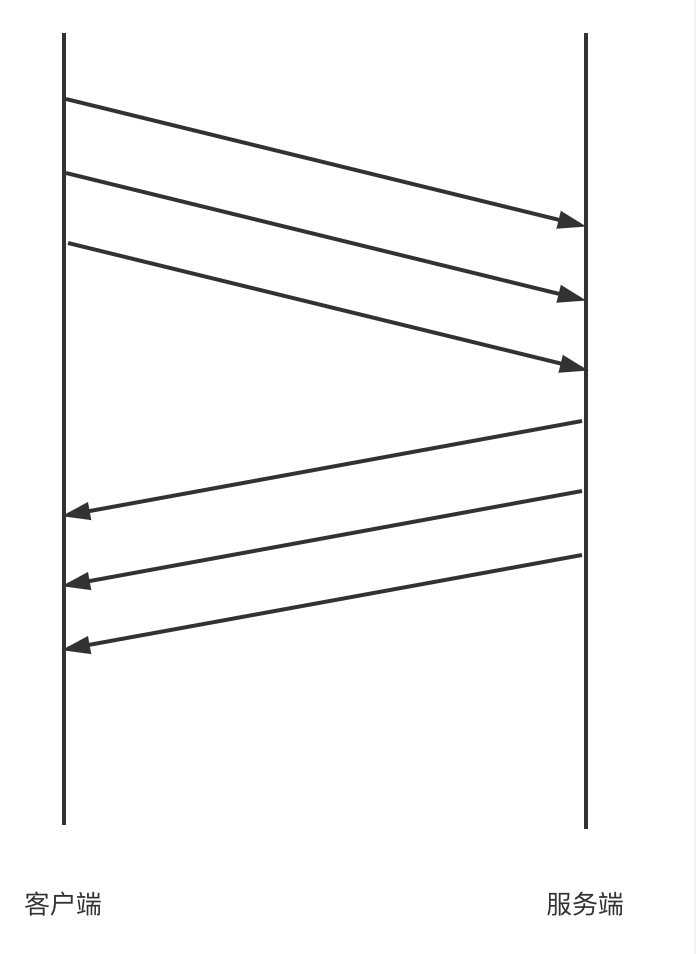
这样无疑能大大减少网络的等待时间,提高并发性能。随之而来的一个显而易见的问题是如何保证响应和请求的正确对应关系?通常有两种策略:
- 如果服务端是单线程/进程地处理每个连接,那服务端天然就是以请求的顺序依次响应的,客户端接收到的响应顺序和请求顺序是一致的,不需要特殊处理;
- 如果服务端是并发地处理每个连接上的所有请求(例如将请求入队列,然后并发地消费队列,经典的如redis),那就无法保证响应的顺序与请求顺序一致,这时就需要修改客户端与服务端的通信协议,在请求与响应的数据结构中带上独一无二的序号,通过匹配这个序号来确定响应和请求之间的映射关系;
HTTP 2.0实现了一个多路复用的机制,其实可以看成是这种流水线的优化,它的响应与请求的映射关系就是通过流ID来保证的。
总结
以上就是对TCP长连接实践中遇到的挑战和解决思路的总结,结合笔者在公司内部的实践经验分别探讨了连接池、连接保活和流水线控制等问题,梳理了实现TCP长连接经常遇到的问题,并提出了解决思路,在降低频繁创建连接的开销的同时尽可能地保证高并发下的性能。
参考
🔥 火山引擎 APMPlus 应用性能监控是火山引擎应用开发套件 MARS 下的性能监控产品。我们通过先进的数据采集与监控技术,为企业提供全链路的应用性能监控服务,助力企业提升异常问题排查与解决的效率。目前我们面向中小企业特别推出「APMPlus 应用性能监控企业助力行动」,为中小企业提供应用性能监控免费资源包。现在申请,有机会获得60天免费性能监控服务,最高可享6000万*条事件量。
👉 点击这里,立即申请

 浙公网安备 33010602011771号
浙公网安备 33010602011771号