
基于 esbuild 的 universal bundler 设计
 由于 Lynx(公司自研跨端框架)编译工具和传统 Web 编译工具链有较大的差别(如不支持动态 style 和动态 script 基本告别了 bundleless 和 code splitting,模块系统基于 json 而非 js,没有浏览器环境),且有在 Web 端实时编译(搭建系统)、web 端动态编译(WebIDE),服务端实时编译(服务端编译下发)、和多版本切换等需求,因此我们需要开发一个即支持在本地也支持在浏览器工作且可以根据业务灵活定制开发的 bundler,即 universal bundler,在开发 universal bundler 的过程中也碰到了一些问题,最后我们基于 esbuild 开发了全新的 universal bundler,解决了我们碰到的大部分问题。
由于 Lynx(公司自研跨端框架)编译工具和传统 Web 编译工具链有较大的差别(如不支持动态 style 和动态 script 基本告别了 bundleless 和 code splitting,模块系统基于 json 而非 js,没有浏览器环境),且有在 Web 端实时编译(搭建系统)、web 端动态编译(WebIDE),服务端实时编译(服务端编译下发)、和多版本切换等需求,因此我们需要开发一个即支持在本地也支持在浏览器工作且可以根据业务灵活定制开发的 bundler,即 universal bundler,在开发 universal bundler 的过程中也碰到了一些问题,最后我们基于 esbuild 开发了全新的 universal bundler,解决了我们碰到的大部分问题。
——字节跳动前端 Byte FE :杨健

背景
由于 Lynx(公司自研跨端框架)编译工具和传统 Web 编译工具链有较大的差别(如不支持动态 style 和动态 script 基本告别了 bundleless 和 code splitting,模块系统基于 json 而非 js,没有浏览器环境),且有在 Web 端实时编译(搭建系统)、web 端动态编译(WebIDE),服务端实时编译(服务端编译下发)、和多版本切换等需求,因此我们需要开发一个即支持在本地也支持在浏览器工作且可以根据业务灵活定制开发的 bundler,即 universal bundler,在开发 universal bundler 的过程中也碰到了一些问题,最后我们基于 esbuild 开发了全新的 universal bundler,解决了我们碰到的大部分问题。
什么是 bundler
bundler 的工作就是将一系列通过模块方式组织的代码将其打包成一个或多个文件,我们常见的 bundler 包括 webpack、rollup、esbuild 等。 这里的模块组织形式大部分指的是基于 js 的模块系统,但也不排除其他方式组织的模块系统(如 wasm、小程序的 json 的 usingComponents,css 和 html 的 import 等),其生成文件也可能不仅仅是一个文件如(code spliting 生成的多个 js 文件,或者生成不同的 js、css、html 文件等)。 大部分的 bundler 的核心工作原理都比较类似,但是其会偏重某些功能,如
-
webpack :强调对 web 开发的支持,尤其是内置了 HMR 的支持,插件系统比较强大,对各种模块系统兼容性最佳(amd,cjs,umd,esm 等,兼容性好的有点过分了,这实际上有利有弊,导致面向 webpack 编程),有丰富的生态,缺点是产物不够干净,产物不支持生成 esm 格式, 插件开发上手较难,不太适合库的开发。
-
rollup: 强调对库开发的支持,基于 ESM 模块系统,对 tree shaking 有着良好的支持,产物非常干净,支持多种输出格式,适合做库的开发,插件 api 比较友好,缺点是对 cjs 支持需要依赖插件,且支持效果不佳需要较多的 hack,不支持 HMR,做应用开发时需要依赖各种插件。
-
esbuild: 强调性能,内置了对 css、图片、react、typescript 等内置支持,编译速度特别快(是 webpack 和 rollup 速度的 100 倍+),缺点是目前插件系统较为简单,生态不如 webpack 和 rollup 成熟。
bundler 如何工作
bundler 的实现和大部分的编译器的实现非常类似,也是采用三段式设计,我们可以对比一下
-
llvm: 将各个语言通过编译器前端编译到 LLVM IR,然后基于 LLVM IR 做各种优化,然后基于优化后的 LLVM IR 根据不同处理器架构生成不同的 cpu 指令集代码。
-
bundler: 将各个模块先编译为 module graph,然后基于 module graph 做 tree shaking && code spliting &&minify 等优化,最后将优化后的 module graph 根据指定的 format 生成不同格式的 js 代码。
LLVM 和 bundler 的对比
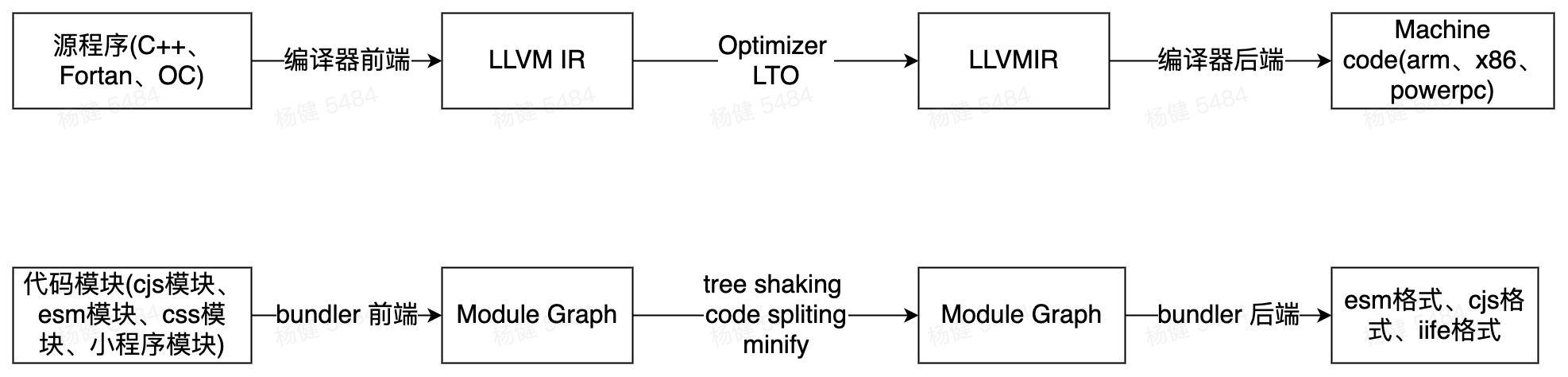
GJWJP 这也使得传统的 LLVM 的很多编译优化策略实际上也可在 bundler 中进行,esbuild 就是将这一做法推广到极致的例子。 因为 rollup 的功能和架构较为精简,我们以 rollup 为例看看一个 bundler 的是如何工作的。 rollup 的 bundle 过程分为两步 rollup 和 generate,分别对应了 bundler 前端和 bundler 后端两个过程。
-
src/main.js
-
src/lib.js
首先通过生成 module graph
输出内容如下
我们的生成产物里已经包含的各个模块解析后的 ast 结构,以及模块之间的依赖关系。 待构建完 module graph,rollup 就可以继续基于 module graph 根据用户的配置构建产物了。
生成内容如下
所以一个基本的 JavaScript 的 bundler 流程并不复杂,但是其如果要真正的应用于生产环境,支持复杂多样的业务需求,就离不开其强大的插件系统。
插件系统
大部分的 bundler 都提供了插件系统,以支持用户可以自己定制 bundler 的逻辑。如 rollup 的插件分为 input 插件和 output 插件,input 插件对应的是根据输入生成 Module Graph 的过程,而 output 插件则对应的是根据 Module Graph 生成产物的过程。 我们这里主要讨论 input 插件,其是 bundler 插件系统的核心,我们这里以 esbuild 的插件系统为例,来看看我们可以利用插件系统来做什么。 input 的核心流程就是生成依赖图,依赖图一个核心的作用就是确定每个模块的源码内容。input 插件正提供了如何自定义模块加载源码的方式。 大部分的 input 插件系统都提供了两个核心钩子
-
onResolve(rollup 里叫 resolveId, webpack 里叫 factory.hooks.resolver): 根据一个 moduleid 决定实际的的模块地址
-
onLoad(rollup 里叫 loadId,webpack 里是 loader):根据模块地址加载模块内容)
load 这里 esbuild 和 rollup 与 webpack 处理有所差异,esbuild 只提供了 load 这个 hooks,你可以在 load 的 hooks 里做 transform 的工作,rollup 额外提供了 transform 的 hooks,和 load 的职能做了显示的区分(但并不阻碍你在 load 里做 transform),而 webpack 则将 transform 的工作下放给了 loader 去完成。 这两个钩子的功能看似虽小,组合起来却能实现很丰富的功能。(插件文档这块,相比之下 webpack 的文档简直垃圾) esbuild 插件系统相比于 rollup 和 webpack 的插件系统,最出色的就是对于 virtual module 的支持。我们简单看几个例子来展示插件的作用。
loader
大家使用 webpack 最常见的一个需求就是使用各种 loader 来处理非 js 的资源,如导入图片 css 等,我们看一下如何用 esbuild 的插件来实现一个简单的 less-loader。
我们只需要在 onLoad 里通过 filter 过滤我们想要处理的文件类型,然后读取文件内容并进行自定义的 transform,然后将结果返回给 esbuild 内置的 css loader 处理即可。是不是十分简单 大部分的 loader 的功能都可以通过 onLoad 插件实现。
sourcemap && cache && error handle
上面的例子比较简化,作为一个更加成熟的插件还需要考虑 transform 后 sourcemap 的映射和自定义缓存来减小 load 的重复开销以及错误处理,我们来通过 svelte 的例子来看如何处理 sourcemap 和 cache 和错误处理。
至此我们实现了一个比较完整的 svelte-loader 的功能。
virtual module
esbuild 插件相比 rollup 插件一个比较大的改进就是对 virtual module 的支持,一般 bundler 需要处理两种形式的模块,一种是路径对应真是的磁盘里的文件路径,另一种路径并不对应真实的文件路径而是需要根据路径形式生成对应的内容即 virtual module。 virtual module 有着非常丰富的应用场景。
glob import
举一个常见的场景,我们开发一个类似https://rollupjs.org/repl/ 之类的 repl 的时候,通常需要将一些代码示例加载到 memfs 里,然后在浏览器上基于 memfs 进行构建,但是如果例子涉及的文件很多的话,一个个导入这些文件是很麻烦的,我们可以支持 glob 形式的导入。 examples/
类似的功能可以通过vite或者 babel-plugin-macro 来实现,我们看看 esbuild 怎么实现。 实现上面的功能其实非常简单,我们只需要
-
在 onResolve 里将自定义的 path 进行解析,然后将元数据通过 pluginData 和 path 传递给 onLoad,并且自定义一个 namespace(namespace 的作用是防止正常的 file load 逻辑去加载返回的路径和给后续的 load 做 filter 的过滤)
-
在 onLoad 里通过 namespace 过滤拿到感兴趣的 onResolve 返回的元数据,根据元数据自定义加载生成数据的逻辑,然后将生成的内容交给 esbuild 的内置 loader 处理
esbuild 基于 filter 和 namespace 的过滤是出于性能考虑的,这里的 filter 的正则是 golang 的正则,namespace 是字符串,因此 esbuild 可以完全基于 filter 和 namespace 进行过滤而避免不必要的陷入到 js 的调用,最大程度减小 golang call js 的 overhead,但是仍然可以 filter 设置为/.*/来完全陷入到 js,在 js 里进行过滤,实际的陷入开销实际上还是能够接受的。
virtual module 不仅可以从磁盘里获取内容,也可以直接内存里计算内容,甚至可以把模块导入当函数调用。
memory virtual module
这里的 env 模块,完全是根据环境变量计算出来的
function virtual module
把模块名当函数使用,完成编译时计算,甚至支持递归函数调用。
stream import
不需要下载 node_modules 就可以进行 npm run dev
上面几个例子可以看出,esbuild 的 virtual module 设计的非常灵活和强大,当我们使用 virtual module 时候,实际上我们的整个模块系统结构变成如下的样子 无法复制加载中的内容 针对不同的场景我们可以选择不同的 namespace 进行组合
-
本地开发: 完全走本地 file 加载,即都走 file namespace
-
本地开发免安装 node_modules: 即类似 deno 和 snowpack 的streaming import的场景,可以通过业务文件走 file namespace,node_modules 文件走 unpkg namespace,比较适合超大型 monorepo 项目开发一个项目需要安装所有的 node_modules 过慢的场景。
-
web 端实时编译场景(性能和网络问题):即第三方库是固定的,业务代码可能变化,则本地 file 和 node_modules 都走 memfs。
-
web 端动态编译:即内网 webide 场景,此时第三方库和业务代码都不固定,则本地 file 走 memfs,node_modules 走 unpkg 动态拉取
我们发现基于 virtual module 涉及的 universal bundler 非常灵活,能够灵活应对各种业务场景,而且各个场景之间的开销互不影响。
universal bundler
大部分的 bundler 都是默认运行在浏览器上,所以构造一个 universal bundler 最大的难点还是在于让 bundler 运行在浏览器上。 区别于我们本地的 bundler,浏览器上的 bundler 存在着诸多限制,我们下面看看如果将一个 bundler 移植到浏览器上需要处理哪些问题。
rollup
首先我们需要选取一个合适的 bundler 来帮我们完成 bundle 的工作,rollup 就是一个非常优秀的 bundler,rollup 有着很多非常优良的性质
-
treeshaking 支持非常好,也支持 cjs 的 tree shaking
-
丰富的插件 hooks,具有非常灵活定制的能力
-
支持运行在浏览器上
-
支持多种输出格式(esm,cjs,umd,systemjs)
正式因为上述优良的特性,所以很多最新的 bundler|bundleness 工具都是基于 rollup 或者兼容 rollup 的插件体系,典型的就是 vite 和wmr, 不得不说给 rollup 写插件比起给 webpack 写插件要舒服很多。 我们早期的 universal bundler 实际上就是基于 rollup 开发的,但是使用 rollup 过程中碰到了不少问题,总结如下
对 CommonJS 的兼容问题
但凡在实际的业务中使用 rollup 进行 bundle 的同学,绕不开的一个插件就是 rollup-plugin-commonjs,因为 rollup 原生只支持 ESM 模块的 bundle,因此如果实际业务中需要对 commonjs 进行 bundle,第一步就是需要将 CJS 转换成 ESM,不幸的是,Commonjs 和 ES Module 的 interop 问题是个非常棘手的问题(搜一搜 babel、rollup、typescript 等工具下关于 interop 的 issue https://sokra.github.io/interop-test/ ,其两者语义上存在着天然的鸿沟,将 ESM 转换成 Commonjs 一般问题不太大(小心避开 default 导出问题),但是将 CJS 转换为 ESM 则存在着更多的问题。 rollup-plugin-commonjs 虽然在 cjs2esm 上下了很多功夫,但是实际仍然有非常多的 edge case,实际上 rollup 也正在重写该核心模块 https://github.com/rollup/plugins/pull/658。
一些典型的问题如下
循环引用问题
由于 commonjs 的导出模块并非是 live binding 的,所以导致一旦出现了 commonjs 的循环引用,则将其转换成 esm 就会出问题
动态 require 的 hoist 问题
同步的动态 require 几乎无法转换为 esm,如果将其转换为 top-level 的 import,根据 import 的语义,bundler 需要将同步 require 的内容进行 hoist,但是这与同步 require 相违背,因此动态 require 也很难处理
Hybrid CJS 和 ESM
因为在一个模块里混用 ESM 和 CJS 的语义并没有一套标准的规范规定,虽然 webpack 支持在一个模块里混用 CJS 和 ESM(downlevel to webpack runtime),但是 rollup 放弃了对该行为的支持(最新版可以条件开启,我没试过效果咋样)
性能问题
正是因为 cjs2esm 的复杂性,导致该转换算法十分复杂,导致一旦业务里包含了很多 cjs 的模块,rollup 其编译性能就会急剧下降,这在编译一些库的时候可能不是大问题,但是用于大型业务的开发,其编译速度难以接受。
浏览器上 cjs 转 esm
另一方面虽然 rollup 可以较为轻松的移植到到 memfs 上,但是 rollup-plugin-commonjs 是很难移植到 web 上的,所以我们早期基于 rollup 做 web bundler 只能借助于类似 skypack 之类的在线 cjs2esm 的服务来完成上述转换,但是大部分这类服务其后端都是通过 rollup-plugin-commonjs 来实现的,因此 rollup 原有的那些问题并没有摆脱,并且还有额外的网络开销,且难以处理非 node_modules 里 cjs 模块的处理。 幸运的是 esbuild 采取的是和 rollup 不同的方案,其对 cjs 的兼容采取了类似 node 的 module wrapper,引入了一个非常小的运行时,来支持 cjs(webpack 实际上也是采用了运行时的方案来兼容 cjs,但是他的 runtime 不够简洁。。。)。
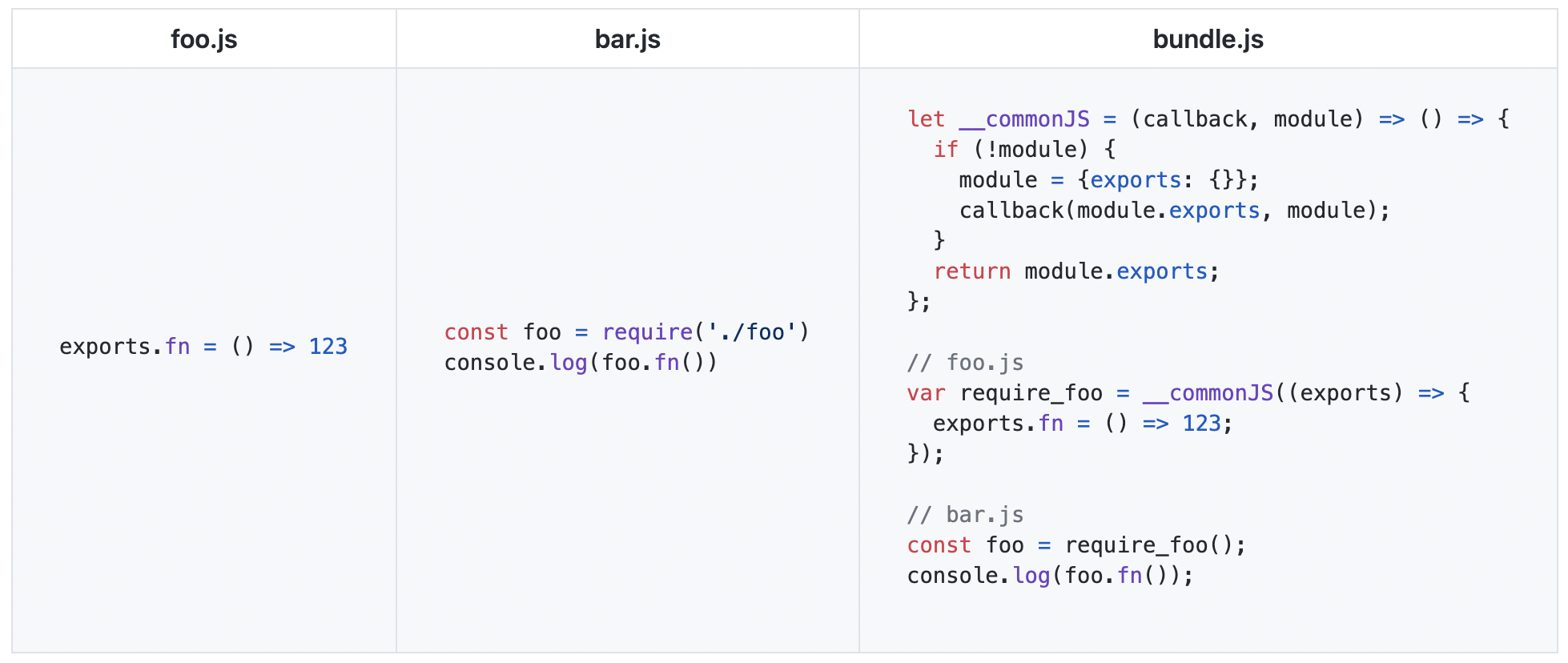
其通过彻底放弃对 cjs tree shaking 的支持来更好的兼容 cjs,并且同时可以在不引入插件的情况下,直接使得 web bundler 支持 cjs。
virutual module 的支持
rollup 的 virtual module 的支持比较 hack,依赖路径前面拼上一个'\0',对路径有入侵性,且对一些 ffi 的场景不太友好(c++ string 把'\0'视为终结符),当处理较为复杂的 virtual module 场景下,'\0'这种路径非常容易处理出问题。

filesystem
本地的 bundler 都是访问的本地文件系统,但是在 browser 是不存在本地文件系统的,因此如何访问文件呢,一般可以通过将 bundler 实现为与具体的 fs 无关来实现,所有的文件访问通过可配置的 fs 来进行访问。https://rollupjs.org/repl/ 即是采用此方式。因此我们只需要将模块的加载逻辑从 fs 里替换为浏览器上的 memfs 即可,onLoad 这个 hooks 正可以用于替换文件的读取逻辑。
node module resolution
当我们将文件访问切换到 memfs 时,一个接踵而至的问题就是如何获取一个 require 和 import 的 id 对应的实际路径格式,node 里将一个 id 映射为一个真实文件地址的算法就是 module resolution, 该算法实现较为复杂需要考虑如下情况,详细算法见 https://tech.bytedance.net/articles/6935059588156751880
-
file|index|目录三种情形
-
js、json、addon 多文件后缀
-
esm 和 cjs loader 区别
-
main field 处理
-
conditional exports 处理
-
exports subpath
-
NODE_PATH 处理
-
递归向上查找
-
symlink 的处理
除了 node module resolution 本身的复杂,我们可能还需要考虑 main module filed fallback、alias 支持、ts 等其他后缀支持等 webpack 额外支持但在社区比较流行的功能,yarn|pnpm|npm 等包管理工具兼容等问题。自己从头实现这一套算法成本较大,且 node 的 module resolution 算法一直在更新,webpack 的enhanced-resolve 模块基本上实现了上述功能,并且支持自定义 fs,可以很方便的将其移植到 memfs 上。
我觉得这里 node 的算法着实有点 over engineering 而且效率低下(一堆 fallback 逻辑有不小的 io 开销),而且这也导致了万恶之源 hoist 盛行的主要原因,也许 bare import 配合 import map,或者 deno|golang 这种显示路径更好一些。
main field
main field 也是个较为复杂的问题,主要在于没有一套统一的规范,以及社区的库并不完全遵守规范,其主要涉及包的分发问题,除了 main 字段是 nodejs 官方支持的,module、browser、browser 等字段各个 bundler 以及第三方社区库并未达成一致意见如
-
cjs 和 esm,esnext 和 es5,node 和 browser,dev 和 prod 的入口该怎么配置
-
module| main 里的代码应该是 es5 还是 esnext 的(决定了 node_module 里的代码是否需要走 transformer)
-
module 里的代码是应该指向 browser 的实现还是指向 node 的实现(决定了 node bundler
和 browser bundler 情况下 main 和 module 的优先级问题)
-
node 和 browser 差异的代码如何分发处理等等
unpkg
接下来我们就需要处理 node_modules 的模块了,此时有两种方式,一种是将 node_modules 全量挂载到 memfs 里,然后使用 enhanced-resolve 去 memfs 里加载对应的模块,另一种方式则是借助于 unpkg,将 node_modules 的 id 转换为 unpkg 的请求。这两种方式都有其适用场景 第一种适合第三方模块数目比较固定(如果不固定,memfs 必然无法承载无穷的 node_modules 模块),而且 memfs 的访问速度比网络请求访问要快的多,因此非常适合搭建系统的实现。 第二种则适用第三方模块数目不固定,对编译速度没有明显的实时要求,这种就比较适合类似 codesandbox 这种 webide 场景,业务可以自主的选择其想要的 npm 模块。
shim 与 polyfill
web bundler 碰到的另一个问题就是大部分的社区模块都是围绕 node 开发的,其会大量依赖 node 的原生 api,但是浏览器上并不会支持这些 api,因此直接将这些模块跑在浏览器上就会出问题。此时分为两种情况
-
一种是这些模块依赖的实际就是些 node 的 utily api 例如 utils、path 等,这些模块实际上并不依赖 node runtime,此时我们实际上是可以在浏览器上模拟这些 api 的,browserify 实际上就是为了解决这种场景的,其提供了大量的 node api 在浏览器上的 polyfill 如 path-browserify,stream-browserify 等等,
-
另一种是浏览器和 node 的逻辑分开处理,虽然 node 的代码不需要在浏览器上执行,但是不期望 node 的实现一方面增大浏览器 bundle 包的体积和导致报错,此时我们需要 node 相关的模块进行 external 处理即可。
一个小技巧,大部分的 bundler 配置 external 可能会比较麻烦或者没办法修改 bundler 的配置,我们只需要将 require 包裹在 eval 里,大部分的 bundler 都会跳过 require 模块的打包。如 eval('require')('os')
polyfill 与环境嗅探,矛与盾之争
polyfill 和环境嗅探是个争锋相对的功能,一方面 polyfill 尽可能抹平 node 和 browser 差异,另一方面环境嗅探想尽可能从差异里区分浏览器和 node 环境,如果同时用了这俩功能,就需要各种 hack 处理了
webassembly
我们业务中依赖了 c++的模块,在本地环境下可以将 c++编译为静态库通过 ffi 进行调用,但是在浏览器上则需要将其编译为 webassembly 才能运行,但是大部分的 wasm 的大小都不小,esbuild 的 wasm 有 8M 左右,我们自己的静态库编译出来的 wasm 也有 3M 左右,这对整体的包大小影响较大,因此可以借鉴 code split 的方案,将 wasm 进行拆分,将首次访问可能用到的代码拆为 hot code,不太可能用到的拆为 cold code, 这样就可以降低首次加载的包的体积。
我们可以在哪里使用 esbuild
esbuild 有三个垂直的功能,既可以组合使用也可以完全独立使用
-
minifier
-
transformer
-
bundler
更高效的 register 和 minify 工具
利用 esbuild 的 transform 功能,使用 esbuild-register 替换单元测试框架 ts-node 的 register,大幅提升速度:见 https://github.com/aelbore/esbuild-jest ,不过 ts-node 现在已经支持自定义 register 了,可以直接将 register 替换为 esbuild-register 即可,esbuild 的 minify 性能也是远远超过 terser(100 倍以上)
更高效的 prebundle 工具
在一些 bundleness 的场景,虽然不对业务代码进行 bundle,但是为了一方面防止第三方库的 waterfall 和 cjs 的兼容问题,通常需要对第三方库进行 prebundle,esbuild 相比 rollup 是个更好的 prebundle 工具,实际上 vite 的最新版已经将 prebundle 功能从 rollup 替换为了 esbuild。
更好的线上 cjs2esm 服务
使用 esbuild 搭建 esm cdn 服务:esm.sh 就是如此
node bundler
相比于前端社区,node 社区似乎很少使用 bundle 的方案,一方面是因为 node 服务里可能使用 fs 以及 addon 等对 bundle 不友好的操作,另一方面是大部分的 bundler 工具都是为了前端设计的,导致应用于 node 领域需要额外的配置。但是对 node 的应用或者服务进行 bundle 有着非常大的好处
-
减小了使用方的 node_modules 体积和加快安装速度,相比将 node 应用的一堆依赖一起安装到业务的 node_modules 里,只安装 bundle 的代码大大减小了业务的安装体积和加快了安装速度,pnpm 和 yarn 就是使用 esbuild 将所有依赖 bundle 实现零依赖的正面典型https://twitter.com/pnpmjs/status/1353848140902903810?s=21
-
提高了冷启动的速度,因为 bundle 后的代码一方面通过 tree shaking 减小了引起实际需要 parse 的 js 代码大小(js 的 parse 开销在大型应用的冷启动速度上占据了不小的比重,尤其是对冷启动速度敏感的应用),另一方面避免了文件 io,这两方面都同时大大减小了应用冷启动的速度,非常适合一些对冷启动敏感的场景,如 serverless
-
避免上游的 semver 语义破坏,虽然 semver 是一套社区规范,但是这实际上对代码要求非常严格,当引入了较多的第三方库时,很难保证上游依赖不会破坏 semver 语义,因此 bundle 代码可以完全避免上游依赖出现 bug 导致应用出现 bug,这对安全性要求极高的应用(如编译器)至关重要。
因此笔者十分鼓励大家对 node 应用进行 bundle,而 esbuild 对 node 的 bundle 提供了开箱即用的支持。
tsc transformer 替代品
tsc 即使支持了增量编译,其性能也极其堪忧,我们可以通过 esbuild 来代替 tsc 来编译 ts 的代码。(esbuid 不支持 ts 的 type check 也不准备支持),但是如果业务的 dev 阶段不强依赖 type checker,完全可以 dev 阶段用 esbuild 替代 tsc,如果对 typechecker 有强要求,可以关注 swc,swc 正在用 rust 重写 tsc 的 type checker 部分,https://github.com/swc-project/swc/issues/571
monorepo 与 monotools
esbuild 是少有的对库开发和应用开发支持都比较良好的工具(webpack 库支持不佳,rollup 应用开发支持不佳),这意味着你完全可以通过 esbuild 统一你项目的构建工具。 esbuild 原生支持 react 的开发,bundle 速度极其快,在没有做任何 bundleness 之类的优化的情况下,一次的完整的 bundle 只需要 80ms(包含了 react,monaco-editor,emotion,mobx 等众多库的情况下)
这带来了另一个好处就是你的 monorepo 里很方便的解决公共包的编译问题。你只需要将 esbuild 的 main field 配置为['source','module','main'],然后在你公共库里将 source 指向你的源码入口,esbuild 会首先尝试去编译你公共库的源码,esbuild 的编译速度是如此之快,根本不会因为公共库的编译影响你的整体 bundle 速度。我只能说 TSC 不太适合用来跑编译,too slow && too complex。
esbuild 存在的一些问题
调试麻烦
esbuild 的核心代码是用 golang 编写,用户使用的直接是编译出来的 binary 代码和一堆 js 的胶水代码,binary 代码几乎没法断点调试(lldb|gdb 调试),每次调试 esbuild 的代码,需要拉下代码重新编译调试,调试要求较高,难度较大
只支持 target 到 es6
esbuild 的 transformer 目前只支持 target 到 es6,对于 dev 阶段影响较小,但目前国内大部分都仍然需要考虑 es5 场景,因此并不能将 esbuild 的产物作为最终产物,通常需要配合 babel | tsc | swc 做 es6 到 es5 的转换
golang wasm 的性能相比 native 有较大的损耗,且 wasm 包体积较大,
目前 golang 编译出的 wasm 性能并不是很好(相比于 native 有 3-5 倍的性能衰减),并且 go 编译出来 wasm 包体积较大(8M+),不太适合一些对包体积敏感的场景
插件 api 较为精简
相比于 webpack 和 rollup 庞大的插件 api 支持,esbuild 仅支持了 onLoad 和 onResolve 两个插件钩子,虽然基于此能完成很多工作,但是仍然较为匮乏,如 code spliting 后的 chunk 的后处理都不支持
🔥 火山引擎 APMPlus 应用性能监控是火山引擎应用开发套件 MARS 下的性能监控产品。我们通过先进的数据采集与监控技术,为企业提供全链路的应用性能监控服务,助力企业提升异常问题排查与解决的效率。
目前我们面向中小企业特别推出_「APMPlus 应用性能监控企业助力行动」_,为中小企业提供应用性能监控免费资源包。现在申请,有机会获得 60 天免费性能监控服务,最高可享 6000 万条事件量。
👉 点击这里,立即申请

 浙公网安备 33010602011771号
浙公网安备 33010602011771号