FHQ-Treap
简介

FHQ-Treap 是一种无旋转的 Treap。 和大多数的平衡树不一样,它并不是用旋转来维护的,而是使用了 split(分裂)和 merge(合并)两种操作来维护 Treap 的性质。
实现
split
split 操作可以将一个 FHQ-Treap 按照某个值分裂为两个 FHQ-Treap:
- 按照权值分:将权值 的放到一个 FHQ-Treap 中, 的放到另一个。
- 按照排名分(之后的变种会用到):将排名 的放到一个 FHQ-Treap 中, 的放到另一个。
那么如何实现?(以权值分裂,A 为 的 FHQ-Treap,B 为 的 FHQ-Treap):
设我们现在在节点 处,如果 ,那么由于二叉搜索树的性质, 左子树中的点权肯定满足 ,所以我们将 及其左子树加入 A。由于右子树中可能有 的点和 的点,所以我们递归处理右子树。( 同理)
考虑我们如何将 及其左/右子树加入 A/B:
假设我们将 及其左子树加入了 A,然后我们在递归 的右子树发现了第一个节点及其左儿子应该被加入 A,那么我们应该把这部分挂在 A 的哪里呢?
由于二叉搜索树的性质,这个点及其左儿子的权值肯定都大于已经在 A 中 的 ( 的左子树不用考虑,因为 是 及其左子树中权值最大的一个),那么由于我们只将 及其左子树挂到了 A,而 的右子树是空的,我们找到的第一个节点又是剩余应该被挂入 A 中的节点中最小的那个(因为二叉搜索树的性质,向右子树递归时点权会越来越大),所以我们直接将这个点及其左子树挂到 A 中 的右儿子即可。(且由于深度大小关系不变,另一随机关键字仍满足堆的性质)(另一半同理)如图:
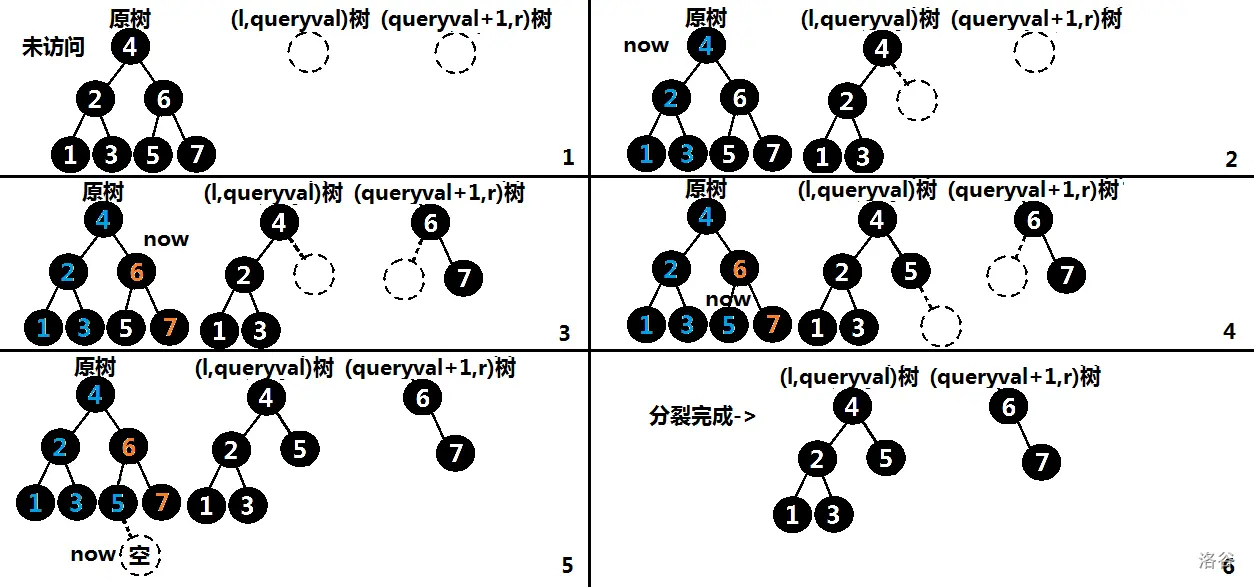
由于每一次递归都会使 的深度+1,而 Treap 的期望深度为 ,所以 split 操作是 。
在代码实现上,可以将 A 和 B 下一个插入的位置传址到下一个递归中,这样在下一个递归中如果要挂节点直接将传下来的位置设为当前节点即可(注意 pushup,主要是更新 size)。
void split (int root, int v, int &x, int &y) {
if (! root) {x = y = 0; return ;} if (val[root] <= v) x = root, split (sr[root], v, sr[root], y);
else y = root, split (sl[root], v, x, sl[root]); pushup (root);
}
merge
合并操作是将两个 FHQ-Treap A 和 B 合并(注意 A 中最大的点权必须小于等于 B 中最小的点权,否则无法合并)。在合并时需要依靠随机关键字 来确定树的形态。
假设此时 A 的合并递归到了 ,B 的合并递归到了 ,此时我们考虑:
如果 ,那么说明 应该被合并在 的下面,而由于 B 中的点权始终大于 A 的点权,所以我们应该将根节点为 的子树和 的右子树合并,所以我们递归合并 的右子树和根节点为 的子树,并将 的右儿子设为合并后新树的根。
如果 ,那么说明 应该被合并在 的下面,而由于 A 中的点权始终小于 B 的点权,所以我们应该将根节点为 的子树和 的左子树合并,然后递归,设置 的左儿子。
当递归时 或 一方变为空时,那么直接返回另一方即可,如图(黑底白字为 ,白底黑字为 ):
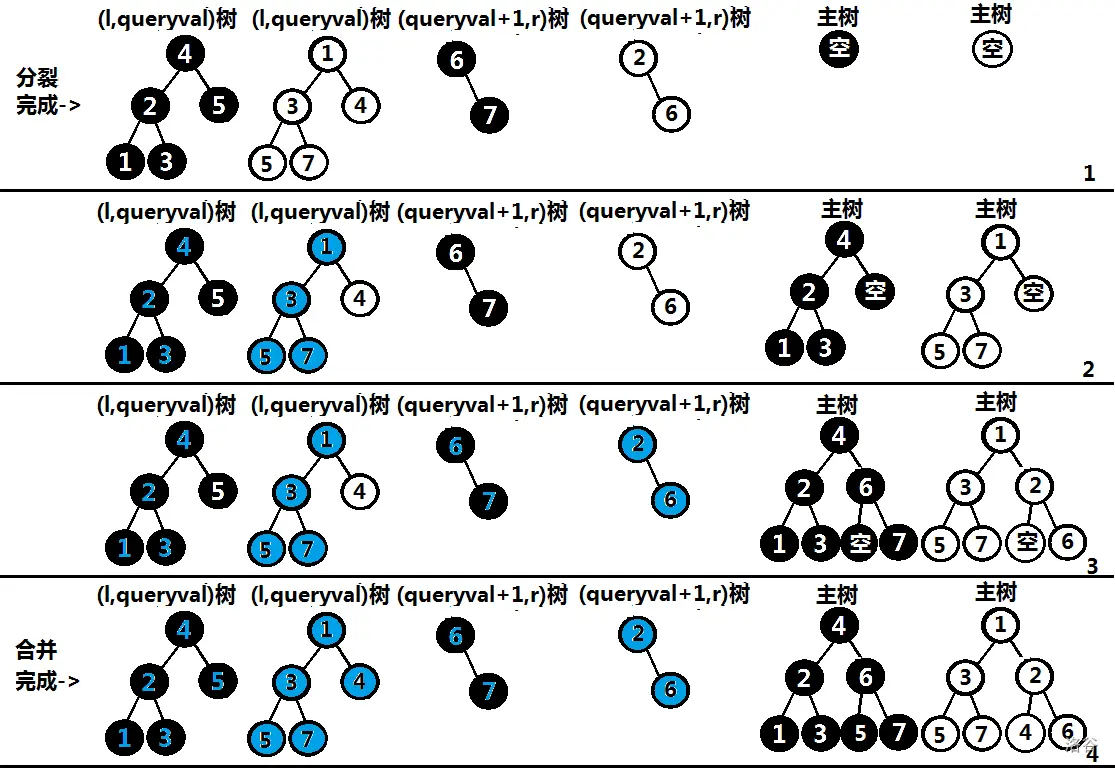
注意不要忘记 pushup。(在代码中若 A 和 B 有一方为空,则直接返回 A+B 的原因是为空即值为 0,相加后的值就是另一方不为 0 的值)
int merge (int A, int B) {
if (! A || ! B) return A + B; if (rnd[A] < rnd[B]) {sr[A] = merge (sr[A], B); pushup (A); return A;}
else {sl[B] = merge (A, sl[B]); pushup (B); return B;}
}
insert
假设我们需要插入一个权值为 的点,我们考虑将 FHQ-Treap 按照 split 为 的 X 和 的 Y,然后然后我们新建一个只有一个节点,权值为 的 FHQ-Treap Z,最后将 X,Z,Y 依次 merge 即可。
void Insert (int &root, int v) {split (root, v, X, Y); root = merge (merge (X, newnode (v)), Y);}
delete
设我们需要删除一个权值为 的点,我们先将 FHQ-Treap 按照 split 为 A 和 B,然后再将 A 按照 split 为 X 和 Y,则 Y 中点的权值均为 。我们将 Y 根节点的左儿子和右儿子 merge,这样就可以去除权值为 根节点,最后按顺序 merge 即可。
void Delete (int &root, int v) {split (root, v, X, Z); split (X, v - 1, X, Y); Y = merge (sl[Y], sr[Y]); root = merge (merge (X, Y), Z);}
rank
我们将 FHQ-Treap 按照 split 为 A 和 B,那么 rank 就显然是 A 的 size +1。
int rank (int &root, int v) {split (root, v - 1, X, Y); int res = sz[X] + 1; root = merge (X, Y); return res;}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具
· Manus的开源复刻OpenManus初探