博客园博客搬运至gitpage一键脚本(python)
起因
博客搬家至gitpage,原来的博客不可能直接不要了,写一个脚本一键迁移
PS:现在我属于左右横跳了 orz
功能分析
获取所有博客 -> 提取所需要的内容 -> 生成各自的markdown文件,放置到_post文件夹下
获取所有博客
可以选择爬虫提取,但为了方便我们直接使用博客园管理界面的博客备份功能,点击之后选择日期就可以生成一个所有博客的xml文件
导出的内容如图:
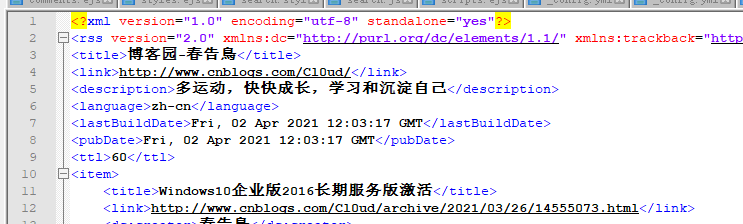
提取需要内容
想要提取想要的内容,我们要先知道哪些信息是我们所需要的
查看hexo自动生成的markdown文件
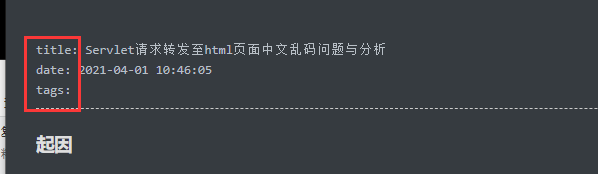
这里可以看出我们需要标题,日期,标签和主要内容
不过我看了一下xml文件,里面却没有文章我们自己设定的标签,所以标签只能缺失了
另一个小问题是日期格式的转换,博客园中使用的是GMT格式的日期格式,我们将其转换成datetime类型格式化输出
from datetime import datetime
def dataformat(date):
GMT_FORMAT2 = '%a, %d %b %Y %H:%M:%S GMT'
print(datetime.strptime(date, GMT_FORMAT2))
def main():
dataformat("Fri, 26 Mar 2021 04:43:00 GMT")
if __name__ == '__main__':
main()
输出结果如下
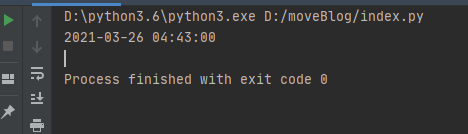
符合我们的要求
接着就是提取相关内容,由于文件为xml,简单学习一下xml文件的使用和提取规则
xml相关
什么是xml
xml即可扩展标记语言,它可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。
xml特征
由标签对组成
<aa></aa>
标签可以有属性:
<aa id='123'></aa>
标签对可以嵌入数据:
<aa>abc</aa>
标签可以嵌入子标签(具有层级关系):
<aa>
<bb></bb>
</aa>
使用xpath解析数据
查了一下资料发现可以直接使用xpath进行解析,因为爬虫的时候用过,所以这里也使用xpath
直接给出提取脚本:
def parse_xml_use_xpath(xml):
users_xml = etree.parse(xml)
root_el = users_xml.getroot()
items = root_el.findall(".//item")
for item in items:
title = item.find("./title").text
pubDate = dataformat(item.find("./pubDate").text)
description = item.find("./description").text.replace('<![CDATA[', '').replace(']]>', '')
print(title)
print(pubDate)
print(description)
使用结果部分如图:
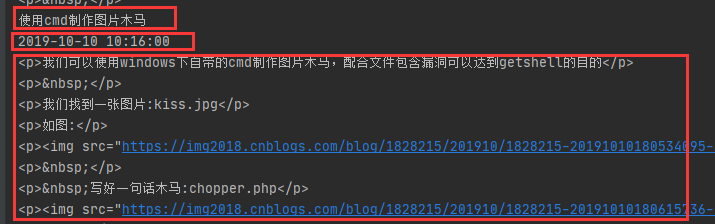
成功并格式化了我们想要的内容
保存
保存代码比较简单,添加前缀后保存为markdown文件,把文章存储在当前目录下的save文件夹下,代码如下
def saveData(title,pubDate,description):
filename=title
try:
f = codecs.open('./save/' + filename + '.md', 'w', encoding='utf-8')
hexo_str = "---\ntitle: {}\ndate: {}\ntags:\n---\n".format(title,pubDate)
f.write(hexo_str)
f.write(description)
f.close()
except Exception:
print(filename)
return
接着发现出现了问题,因为xml文件里面的文章是html的格式,之前竟然没注意到这一点,导致效果如下
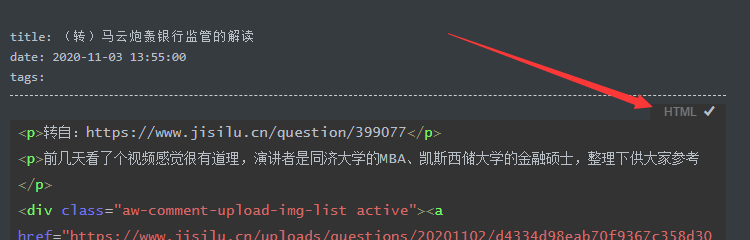
虽然前缀是加上了,但是因为文章内容是html格式的,所以文章实际上还是看不了的,需要html转markdown
接着寻找解决方案,在知乎上看到了一个陈年问题
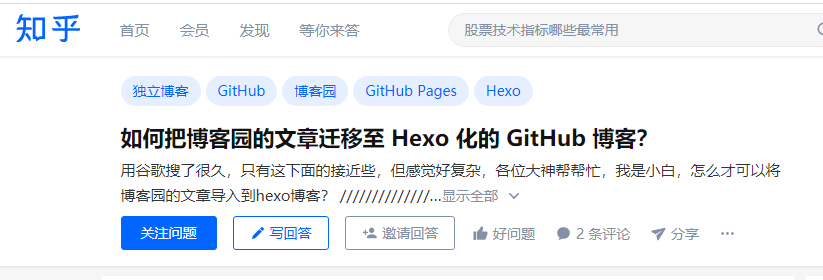
其中一个评论中给出了一个github的实现
https://github.com/vhyz/hexo-migrator
尝试了一下其中的html2markdown的实现,太拉跨了
然后查资料继续找,尝试使用tomd ,html2text,LCTT-Helper,都或多或少有缺陷,淦
大家都抄过去抄过来,气的直接拿起键盘打算重新撸一个,撸好了再更新
二更
在html2markdown的基础上进行修改,将博客园备份的xml文件全部转为了markdown并上传到了本博客上
本来想写个python库的,但感觉该脚本不足还是很多,只能说在一部分优于原脚本,方便从博客园搬运到gitpage,所以就只放到博客里了。
xml -> 字符流 python脚本
import codecs
from datetime import datetime
from lxml import etree
import html2markdown
BlackList=[
'"','\'','>','+'
]
def dataformat(date):
GMT_FORMAT2 = '%a, %d %b %Y %H:%M:%S GMT'
return datetime.strptime(date, GMT_FORMAT2)
def parse_xml_use_xpath(xml):
users_xml = etree.parse(xml)
root_el = users_xml.getroot()
items = root_el.findall(".//item")
for item in items:
title = item.find("./title").text
pubDate = dataformat(item.find("./pubDate").text)
description = item.find("./description").text.replace('<![CDATA[', '').replace(']]>', '')
# print(title)
# print(pubDate)
# print(description)
title=title.replace('[','(').replace(']',')')
for i in title:
if i in BlackList:
title=title.replace(i,'_')
print(title)
saveData(title, pubDate, description)
def saveData(title,pubDate,description):
filename=title
f = codecs.open('./save/' + filename + '.md', 'w', encoding='utf-8')
hexo_str = "---\ntitle: {}\ndate: {}\ntags:\n---\n".format(title,pubDate)
f.write(hexo_str)
if(description.strip().startswith("##")):
f.write(description)
else:
f.write(html2markdown.convert(description))
f.close()
def main():
# dataformat("Fri, 26 Mar 2021 04:43:00 GMT")
parse_xml_use_xpath("1.xml")
if __name__ == '__main__':
main()
使用前需要:
- 将
xml放置在同个目录下 - 在当前目录创建
save文件夹,生成的markdown会保存在里面
在原基础上修改后的html2markdown我命名为html2markdown4,可以根据自己的需要继续修改:
# -*- coding:utf8 -*-
"""html2markdown converts an html string to markdown while preserving unsupported markup."""
#
# Copyright 2017-2018 David Lönnhager (dlon)
#
# Permission is hereby granted, free of charge, to any person obtaining a copy of
# this software and associated documentation files (the "Software"), to deal in
# the Software without restriction, including without limitation the rights to
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
# of the Software, and to permit persons to whom the Software is furnished
# to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in all
# copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
# INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
# PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
# COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
# IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
# WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
#
from html.parser import HTMLParser
import bs4
from bs4 import BeautifulSoup
import re
import sys
if sys.version_info[0] > 2:
unicode = str
_supportedTags = {
# NOTE: will be ignored if they have unsupported attributes (cf. _supportedAttributes)
#注意:如果它们具有不受支持的属性,则将被忽略(参见_supportedAttributes)
'blockquote',
'p',
'a',
'h1','h2','h3','h4','h5','h6',
'strong','b',
'em','i',
'ul','ol','li',
'br',
'img',
'pre','code',
'hr'
}
_supportedAttributes = (
'a href',
'a title',
'img alt',
'img src',
'img title',
)
_inlineTags = {
# these can be mixed with markdown (when unprocessed)
# block tags will be surrounded by newlines and be unprocessed inside
# (unless supported tag + supported attribute[s])
#这些可以与markdown混合(未处理时),块标签将被换行符包围,并且在内部未处理,(除非支持的标签+支持的属性)
'a',
'abbr',
'acronym',
'audio',
'b',
'bdi',
'bdo',
'big',
#'br',
'button',
#'canvas',
'cite',
'code',
'data',
'datalist',
'del',
'dfn',
'em',
#'embed',
'i',
#'iframe',
#'img',
#'input',
'ins',
'kbd',
'label',
'map',
'mark',
'meter',
#'noscript',
'object',
#'output',
'picture',
#'progress',
'q',
'ruby',
's',
'samp',
#'script',
'select',
'slot',
'small',
'span',
'strike',
'strong',
'sub',
'sup',
'svg',
'template',
'textarea',
'time',
'u',
'tt',
'var',
#'video',
'wbr',
}
def _supportedAttrs(tag):
sAttrs = [attr.split(' ')[1] for attr in _supportedAttributes if attr.split(' ')[0]==tag.name]
for attr in tag.attrs:
if attr not in sAttrs:
return False
return True
def _recursivelyValid(tag):
# not all tags require this property
# requires: <blockquote><p style="...">asdf</p></blockquote>
# does not: <div><p style="...">asdf</p></div>
children = tag.find_all(recursive = False)
for child in children:
if not _recursivelyValid(child):
return False
if tag.name == '[document]':
return True
elif tag.name in _inlineTags:
return True
# elif tag.name not in _supportedTags:
# return False
# if not _supportedAttrs(tag):
# return False
return True
_escapeCharSequence = tuple(r'\`*_[]#')
_escapeCharRegexStr = '([{}])'.format(''.join(re.escape(c) for c in _escapeCharSequence))
_escapeCharSub = re.compile(_escapeCharRegexStr).sub
def _escapeCharacters(tag):
"""non-recursively escape underlines and asterisks
in the tag"""
# 在标签中非递归地转义下划线和星号
for i,c in enumerate(tag.contents):
if type(c) != bs4.element.NavigableString:
continue
c.replace_with(_escapeCharSub(r'\\\1', c))
def _breakRemNewlines(tag):
"""non-recursively break spaces and remove newlines in the tag"""
#非递归地分隔空格并删除标记中的换行符
for i,c in enumerate(tag.contents):
if type(c) != bs4.element.NavigableString:
continue
c.replace_with(re.sub(r' {2,}', ' ', c).replace('\n',''))
def _markdownify(tag, _listType=None, _blockQuote=False, _listIndex=1):
"""recursively converts a tag into markdown"""
# 递归地将标签转换为markdown
# print(tag.name)
children = tag.find_all(recursive=False)
if tag.name == '[document]':
for child in children:
_markdownify(child)
return
# if tag.name in _inlineTags:
# for child in children:
# _markdownify(child)
# tag.unwrap()
# if tag.name not in _inlineTags:
# # print(tag.name)
# tag.insert_before('\n\n')
# tag.insert_after('\n\n')
# else:
# _escapeCharacters(tag)
# for child in children:
# _markdownify(child)
# return
# if tag.name not in ('pre', 'code'):
# _escapeCharacters(tag)
# _breakRemNewlines(tag)
if tag.name=='div':
tag.insert_before('\n')
tag.insert_after('\n')
for child in children:
_markdownify(child)
tag.unwrap()
return
elif tag.name=='span' or tag.name=='strong':
tag.unwrap()
if tag.name == 'p':
if tag.string != None:
if tag.string.strip() == u'':
tag.string = u'\xa0'
tag.unwrap()
return
if _blockQuote:
tag.insert_before('\n')
tag.insert_after('\n')
tag.unwrap()
for child in children:
_markdownify(child)
elif tag.name == 'br':
tag.string = ' \n'
tag.unwrap()
elif tag.name == 'img':
alt = ''
title = ''
if tag.has_attr('alt'):
alt = tag['alt']
if tag.has_attr('title') and tag['title']:
title = ' "%s"' % tag['title']
if tag.has_attr('src'):
tag.string = '' % (alt, tag['src'], title)
tag.unwrap()
elif tag.name == 'hr':
tag.string = '\n---\n'
tag.unwrap()
elif tag.name == 'pre':
tag.insert_before('\n')
tag.insert_after('\n')
if tag.code:
if not _supportedAttrs(tag.code):
return
for child in tag.code.find_all(recursive=False):
if child.name != 'br':
return
# code block
for br in tag.code.find_all('br'):
br.string = '\n'
br.unwrap()
tag.code.unwrap()
lines = unicode(tag).strip().split('\n')
lines[0] = lines[0][5:]
lines[-1] = lines[-1][:-6]
if not lines[-1]:
lines.pop()
for i,line in enumerate(lines):
line = line.replace(u'\xa0', ' ')
lines[i] = ' %s' % line
tag.replace_with(BeautifulSoup('\n'.join(lines), 'html.parser'))
pattern = re.compile('brush:(.*?);')
try:
result=pattern.findall(tag.get("class")[0])[0]
except Exception:
result=""
pass
if tag.parent is None:
if children:
for child in children:
_markdownify(child,_listType=tag.name, _blockQuote=True)
else:
tag.insert_before('```{}\n'.format(result))
tag.insert_after('\n```\n')
try:
tag.unwrap()
except Exception:
pass
return
# return
elif tag.name == 'code' and tag.parent!=None:
# inline code
# if children:
# return
tag.insert_before('```\n ')
tag.insert_after('\n```\n')
tag.unwrap()
elif _recursivelyValid(tag):
if tag.name == 'blockquote':
# ! FIXME: hack
tag.insert_before('<<<BLOCKQUOTE: ')
tag.insert_after('>>>')
tag.unwrap()
for child in children:
_markdownify(child, _blockQuote=True)
return
elif tag.name == 'a':
# process children first
for child in children:
if child.name=='img' and tag.has_attr('href'):
_markdownify(child)
tag.unwrap()
return
_markdownify(child)
if not tag.has_attr('href'):
return
if tag.string != tag.get('href') or tag.has_attr('title'):
title = ''
if tag.has_attr('title'):
title = ' "%s"' % tag['title']
tag.string = '[%s](%s%s)' % (BeautifulSoup(unicode(tag), 'html.parser').string,
tag.get('href', ''),
title)
else:
# ! FIXME: hack
tag.string = '%s' % tag.string
tag.unwrap()
return
elif tag.name == 'h1':
tag.insert_before('\n\n# ')
tag.insert_after('\n\n')
tag.unwrap()
elif tag.name == 'h2':
tag.insert_before('\n\n## ')
tag.insert_after('\n\n')
tag.unwrap()
elif tag.name == 'h3':
tag.insert_before('\n\n### ')
tag.insert_after('\n\n')
tag.unwrap()
elif tag.name == 'h4':
tag.insert_before('\n\n#### ')
tag.insert_after('\n\n')
tag.unwrap()
elif tag.name == 'h5':
tag.insert_before('\n\n##### ')
tag.insert_after('\n\n')
tag.unwrap()
elif tag.name == 'h6':
tag.insert_before('\n\n###### ')
tag.insert_after('\n\n')
tag.unwrap()
elif tag.name in ('ul', 'ol'):
# tag.insert_before('\n\n')
# tag.insert_after('\n\n')
tag.unwrap()
for i, child in enumerate(children):
_markdownify(child, _listType=tag.name, _listIndex=i+1)
return
elif tag.name == 'li':
if not _listType:
# <li> outside of list; ignore
return
if _listType == 'ul':
tag.insert_before('+ ')
else:
tag.insert_before('%d. ' % _listIndex)
for child in children:
_markdownify(child)
# for c in tag.contents:
# if type(c) != bs4.element.NavigableString:
# continue
# c.replace_with('\n '.join(c.split('\n')))
# tag.insert_after('\n')
tag.unwrap()
return
elif tag.name in ('b'):
tag.insert_before('__')
tag.insert_after('__')
tag.unwrap()
elif tag.name in ('em','i'):
tag.insert_before('_')
tag.insert_after('_')
tag.unwrap()
for child in children:
_markdownify(child)
def convert(html):
"""converts an html string to markdown while preserving unsupported markup."""
#在保留不支持的标记的同时,将html字符串转换为markdown。
bs = BeautifulSoup(html, 'html.parser')
_markdownify(bs)
ret = unicode(bs).replace(u'\xa0', ' ')
ret = re.sub(r'\n{3,}', r'\n\n', ret)
# ! FIXME: hack
ret = re.sub(r'<<<FLOATING LINK: (.+)>>>', r'<\1>', ret)
# ! FIXME: hack
sp = re.split(r'(<<<BLOCKQUOTE: .*?>>>)', ret, flags=re.DOTALL)
for i,e in enumerate(sp):
if e[:len('<<<BLOCKQUOTE:')] == '<<<BLOCKQUOTE:':
sp[i] = '> ' + e[len('<<<BLOCKQUOTE:') : -len('>>>')]
sp[i] = sp[i].replace('\n', '\n> ')
ret = ''.join(sp)
html_parser = HTMLParser()
text3 = html_parser.unescape(ret)
return text3.strip('\n')
放在同个目录下使用即可
生成的文章放置到gitpage的_post文件夹下上传即可
因为我用的gitalk进行文章评论处理,每一篇新的文章都需要管理员初始化一下,虽然这个也可以使用脚本来处理,但限于个人时间精力有限,还需要去做其他更重要的事情,所以对于直接导入的文章评论就没有再进行处理了,如果有好的办法欢迎私信我!
参考链接:
- https://www.cnblogs.com/fresky/p/3337567.html
- https://www.cnblogs.com/fnng/p/3581433.html
- https://blog.csdn.net/weixin_45492007/article/details/103481551
END
建了一个微信的安全交流群,欢迎添加我微信备注进群,一起来聊天吹水哇,以及一个会发布安全相关内容的公众号,欢迎关注 😃



 浙公网安备 33010602011771号
浙公网安备 33010602011771号