crawlergo动态爬虫去除Spidername使用
本来是想用AWVS的爬虫来联动Xray的,但是需要主机安装AWVS,再进行规则联动,只是使用其中的目标爬虫功能感觉就太重了,在github上面找到了由360 0Kee-Team团队从360天相中分离出来的动态爬虫模块crawlergo,尝试进行自定义代码联动
基础使用
下载最新的releases版本,到其目录下使用:
在PowerShell里面运行
./crawlergo -c "C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" -t 10 http://testphp.vulnweb.com/

但是很明显可以看到在爬虫的请求头里面存在:

Spider-Name:crawlergo字段
crawlergo团队也说明了这个问题:
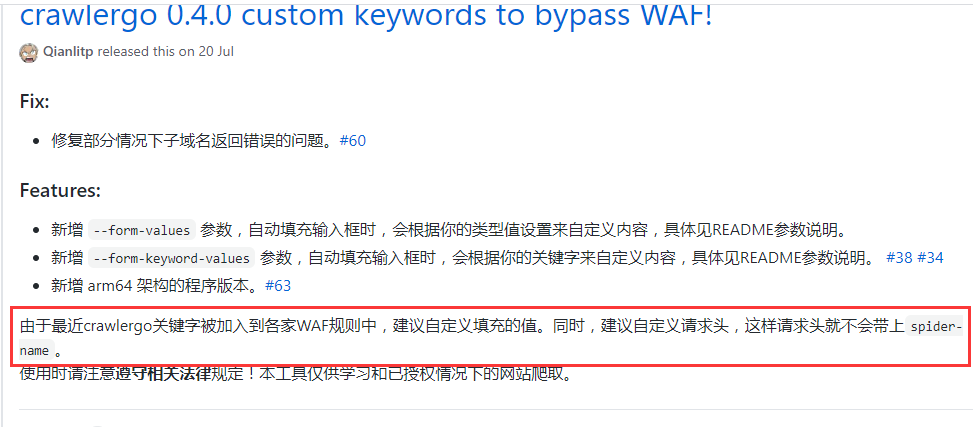
也有issue提到了这一点

所以我们先解决关键字被WAF拦截的问题,使用自定义请求头进行crawlergo页面爬取。
使用fake_useragent伪造请求头:
from fake_useragent import UserAgent
ua = UserAgent()
def GetHeaders():
headers = {'User-Agent': ua.random}
return headers
在爬取的时候指定请求头为随机生成的,即:
"--custom-headers",json.dumps(GetHeaders())
然后根据crawlergo团队给出的系统调用部分代码进行修改
原代码如下(我已将谷歌浏览器路径改为自己本地的了):
#!/usr/bin/python3
# coding: utf-8
import simplejson
import subprocess
def main():
target = "http://testphp.vulnweb.com/"
cmd = ["./crawlergo", "-c", "C:\Program Files (x86)\Google\Chrome\Application\chrome.exe", "-o", "json", target]
rsp = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
output, error = rsp.communicate()
# "--[Mission Complete]--" 是任务结束的分隔字符串
result = simplejson.loads(output.decode().split("--[Mission Complete]--")[1])
req_list = result["req_list"]
print(req_list[0])
if __name__ == '__main__':
main()
该代码默认打印当前域名请求
运行结果如图:

将关键部分代码:
cmd = ["./crawlergo", "-c", "C:\Program Files (x86)\Google\Chrome\Application\chrome.exe", "-o", "json", target]
根据项目参数:
--custom-headers Headers自定义HTTP头,使用传入json序列化之后的数据,这个是全局定义,将被用于所有请求
修改为:
cmd = ["./crawlergo", "-c", "C:\Program Files (x86)\Google\Chrome\Application\chrome.exe", "--custom-headers",json.dumps(GetHeaders()),"-t","10","-o", "json", target]
GetHeaders()函数上面已经给出,运行结果为:

可以看到Spider-Name:crawlergo字段已经没有了。
对于返回结果的处理
当设置输出模式为 json时,返回的结果反序列化之后包含四个部分:
all_req_list: 本次爬取任务过程中发现的所有请求,包含其他域名的任何资源类型。req_list:本次爬取任务的同域名结果,经过伪静态去重,不包含静态资源链接。理论上是all_req_list的子集all_domain_list:发现的所有域名列表。sub_domain_list:发现的任务目标的子域名列表。
我们想要获取的是任务的同域名结果,所以输出:
result = simplejson.loads(output.decode().split("--[Mission Complete]--")[1])
# print(result)
req_list = result["req_list"]
for url in req_list:
print(url['url'])

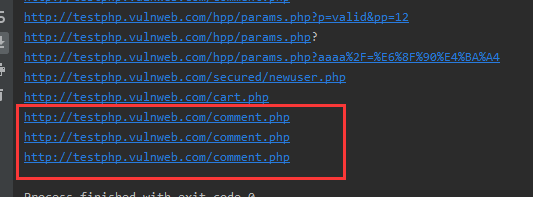
可以看到去重不算太完美
最后为了方便配置可以写一个config.py,用来放置chorme的路径,增加扫描系统的通用性,将结果存储到txt或者队列里面去。

