Python调用云服务器AWVS13API接口批量扫描(指哪打哪)
最近因为实习的原因,为了减少一部分的工作量,在阿里云服务器上搭建了AWVS扫描器 方便摸鱼
但是发现AWVS貌似没有批量添加的方法,作者只好把整理的URL.txt捏了又捏

手动输入是不可能手动输入的,去查了查网上关于AWVS扫描器API的使用,找到两篇文章:
https://blog.csdn.net/wy_97/article/details/106872773
https://blog.csdn.net/sinat_25449961/article/details/82985638
然后花一个小时的时间整理了一下,因为作者只需要添加任务,以及让扫描任务启动,所以我们也从这两个功能入手,查看API接口。
添加任务接口是:
Method:POST URL: /api/v1/targets
| 发送参数 | 类型 | 说明 |
|---|---|---|
| address | string | 目标网址:需http或https开头 |
| criticality | Int | 危险程度;范围:[30,20,10,0];默认为10 |
| description | string | 备注 |
具体的使用如下:
'''
create_target函数
功能:
AWVS13
新增任务接口
Method : POST
URL : /api/v1/targets
发送参数:
发送参数 类型 说明
address string 目标网址:需要http或https开头
criticality int 危险程度;范围:[30,20,10,0];默认为10
description string 备注
'''
def create_target(address,description,int_criticality):
url = 'https://' + IP + ':13443/api/v1/targets'
headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
values = {
'address': address,
'description': description,
'criticality': int_criticality,
}
data = bytes(json.dumps(values), 'utf-8')
request = urllib.request.Request(url, data, headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
return html
在create_target()函数中,如服务器IP是全局变量,即搭建AWVS的服务器的IP,后面接的端口需要根据实际情况修改。
可以看到现在还没有任务:
简单调用:
#这两处需要修改为你自己的
IP = ''
API_KEY = ''
def main():
testurl='https://www.zsjjob.com/'
description="null"
int_criticality=10
print(create_target(testurl,description,int_criticality))
if __name__=='__main__':
main()
运行返回结果为:
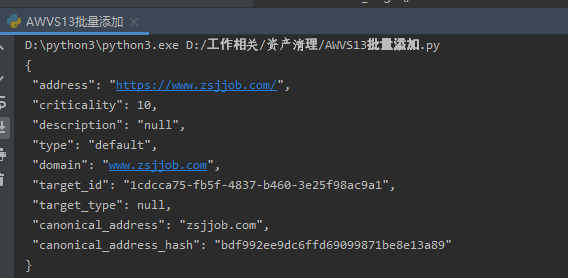
接着我们查看AWVS添加的任务里面
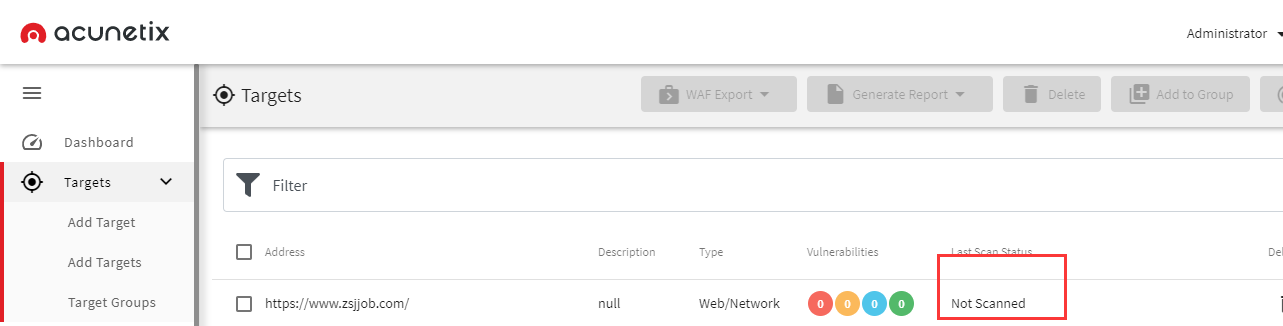
可以看到只是添加到了任务中,还未进行扫描,接着我们查看开始扫描的API:
Method:POST URL: /api/v1/scans
| 发送参数 | 类型 | 说明 |
| profile_id | string | 扫描类型 |
| ui_session_i | string | 可不传 |
| schedule | json | 扫描时间设置(默认即时) |
| report_template_id | string | 扫描报告类型(可不传) |
| target_id | string | 目标id |
可以看到必选的就是 扫描类型,扫描时间设置,目标id
而扫描类型 profile_id 可以选择的有:
| 扫描类型 | 值 | 翻译 |
| Full Scan | 11111111-1111-1111-1111-111111111111 | 完全扫描 |
| High Risk Vulnerabilities | 11111111-1111-1111-1111-111111111112 | 高风险漏洞 |
| Cross-site Scripting Vulnerabilities | 11111111-1111-1111-1111-111111111116 | XSS漏洞 |
| SQL Injection Vulnerabilities | 11111111-1111-1111-1111-111111111113 | SQL注入漏洞 |
| Weak Passwords | 11111111-1111-1111-1111-111111111115 | 弱口令检测 |
| Crawl Only | 11111111-1111-1111-1111-111111111117 | Crawl Only |
| Malware Scan | 11111111-1111-1111-1111-111111111120 | 恶意软件扫描 |
我们在代码中使用的是扫描类型对应的值,一般都是直接使用完全扫描
扫描时间设置我们按照默认值设置,目标 id 我们之前已经看到过了,即:
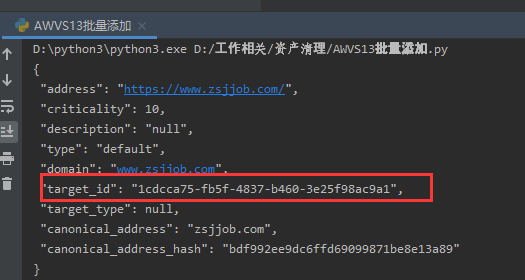
所以我们只要将获取到的target_id和其他两个参数丢进去就行了。
具体使用如下:
'''
start_target
功能:
AWVS13
启动扫描任务接口
Method : POST
URL : /api/v1/scans
发送参数:
发送参数 类型 说明
profile_id string 扫描类型
ui_session_i string 可不传
schedule json 扫描时间设置(默认即时)
report_template string 扫描报告类型(可不传)
target_id string 目标id
'''
def start_target(target_id,profile_id):
url = 'https://' + IP + ':13443/api/v1/scans'
# schedule={"disable": False, "start_date": None, "time_sensitive": False}
headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
values = {
'target_id': target_id,
'profile_id': profile_id,
'schedule': {"disable":False,"start_date":None,"time_sensitive":False}
}
data = bytes(json.dumps(values), 'utf-8')
request = urllib.request.Request(url, data, headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
# return html
return "now scan {}".format(target_id)
然后先将AWVS上面的任务清空一下,然后整合和调用之前的所有代码。
清空后的AWVS如图:
整合调用的全部代码为(作者去掉了IP和API_KEY,需要读者按照自己的搭建自行添加,另外还需要注意端口的问题)
import json
import ssl
import urllib.request
import os
ssl._create_default_https_context = ssl._create_unverified_context
#os.environ['http_proxy'] = 'http://127.0.0.1:8080'
#os.environ['https_proxy'] = 'https://127.0.0.1:8080'
IP = ''
API_KEY = ''
'''
create_target函数
功能:
AWVS13
新增任务接口
Method : POST
URL : /api/v1/targets
发送参数:
发送参数 类型 说明
address string 目标网址:需要http或https开头
criticality int 危险程度;范围:[30,20,10,0];默认为10
description string 备注
'''
def create_target(address,description,int_criticality):
url = 'https://' + IP + ':13443/api/v1/targets'
headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
values = {
'address': address,
'description': description,
'criticality': int_criticality,
}
data = bytes(json.dumps(values), 'utf-8')
request = urllib.request.Request(url, data, headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
return html
def get_target_list():
url = 'https://' + IP + ':3443/api/v1/targets'
headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
request = urllib.request.Request(url=url, headers=headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
return html
def profiles_list():
url = 'https://' + IP + ':3443/api/v1/scanning_profiles'
headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
request = urllib.request.Request(url=url, headers=headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
return html
'''
start_target
功能:
AWVS13
启动扫描任务接口
Method : POST
URL : /api/v1/scans
发送参数:
发送参数 类型 说明
profile_id string 扫描类型
ui_session_i string 可不传
schedule json 扫描时间设置(默认即时)
report_template string 扫描报告类型(可不传)
target_id string 目标id
'''
def start_target(target_id,profile_id):
url = 'https://' + IP + ':13443/api/v1/scans'
# schedule={"disable": False, "start_date": None, "time_sensitive": False}
headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
values = {
'target_id': target_id,
'profile_id': profile_id,
'schedule': {"disable":False,"start_date":None,"time_sensitive":False}
}
data = bytes(json.dumps(values), 'utf-8')
request = urllib.request.Request(url, data, headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
# return html
return "now scan {}".format(target_id)
def stop_target(target_id):
url = 'https://' + IP + ':3443/api/v1/scans/' + target_id + '/abort'
headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
request = urllib.request.Request(url=url, headers=headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
print(html)
def target_status(target_id):
url = 'https://' + IP + ':3443/api/v1/scans/' + target_id
headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
request = urllib.request.Request(url=url, headers=headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
print(html)
def get_target_result(target_id, scan_session_id):
url = 'https://' + IP + ':3443/api/v1/scans/' + target_id + '/results/' + scan_session_id + '/vulnerabilities '
headers = {"X-Auth": API_KEY, "content-type": "application/json", 'User-Agent': 'curl/7.53.1'}
request = urllib.request.Request(url=url, headers=headers)
html = urllib.request.urlopen(request).read().decode('utf-8')
print(html)
'''
主要使用批量添加与启动扫描任务的功能
即create_target()函数与start_target()函数
'''
def main():
testurl='https://www.zsjjob.com/'
description="null"
int_criticality=10
target_id=create_target(testurl,description,int_criticality).split('"')[21]
print(start_target(target_id,'11111111-1111-1111-1111-111111111111'))
if __name__=='__main__':
main()
运行之
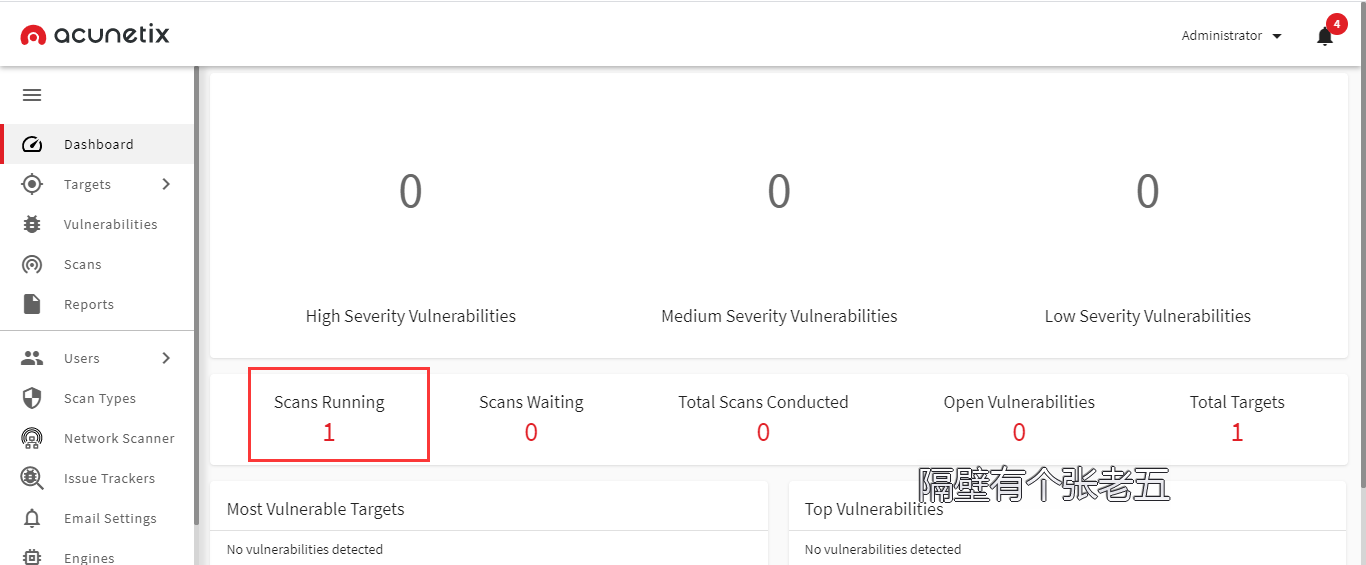
可以看到任务已经自动运行起来了,读者可以根据自己的URL.txt,修改上述代码,使其更符合业务需求。
另外需要注意的是,AWVS的批量添加URL中,都是需要http或者https开头的!!
以上(开始快乐批量扫描趴)
参考链接:
https://blog.csdn.net/sinat_25449961/article/details/82985638

 浙公网安备 33010602011771号
浙公网安备 33010602011771号