[GXYCTF2019] MISC杂项题
buuoj复现
1,佛系青年
下载了之后是一个加密的txt文件和一张图片

分析图片无果,很讨厌这种脑洞题,MISC应该给一点正常的线索加部分脑洞而不是出干扰信息来故意让选手走错方向,当时比赛做这道题的时候也是醉了
接着将压缩包放进010Editor查看是否伪加密和其他线索
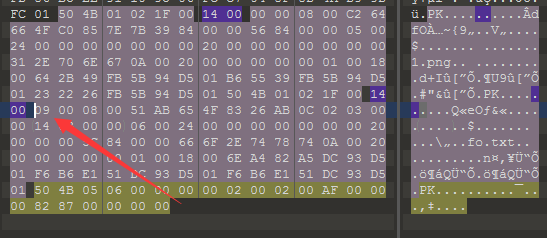
发现伪加密,将0900改成0000,保存之后打开txt文件

很明显最后一句是与佛论禅
佛曰:遮等諳勝能礙皤藐哆娑梵迦侄羅哆迦梵者梵楞蘇涅侄室實真缽朋能。奢怛俱道怯都諳怖梵尼怯一罰心缽謹缽薩苦奢夢怯帝梵遠朋陀諳陀穆諳所呐知涅侄以薩怯想夷奢醯數羅怯諸
在线解密得到:

2,gakki
下载压缩包之后是一张gakki的图片

foremost一下
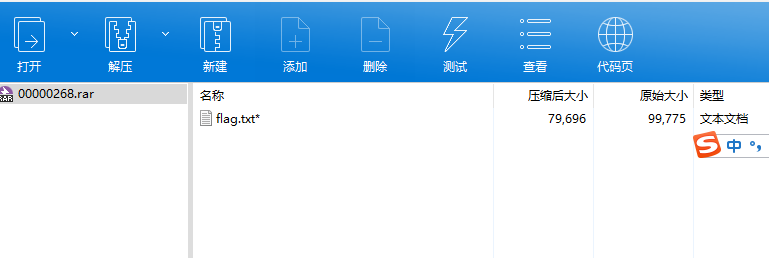
分离之后得到了压缩包,同时需要密码
尝试数字爆破
得到密码8864
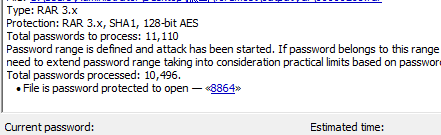
解密之

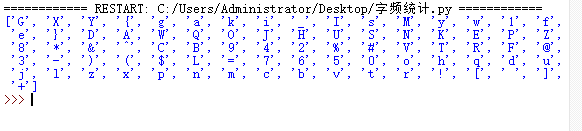
flag.txt文件里面是一大堆乱七八糟的字符,这种无规律的字符集我们就尝试字频统计
附上官方字频统计exp:(羡慕
# gakki_exp.py
# Author : imagin
alphabet = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890!@#$%^&*()_+- ={}[]"
f = open("flag.txt", "r")
data = f.read()
result = {d:0 for d in alphabet}
def sort_by_value(d):
items = d.items()
backitems = [[v[1],v[0]] for v in items]
backitems.sort(reverse=True)
return [ backitems[i][1] for i in range(0,len(backitems))]
for d in data:
for alpha in alphabet:
if d == alpha:
result[alpha] = result[alpha] + 1
print(sort_by_value(result))
跑一遍就得到flag了
这道题重在看到题目的意识。
3,SXMgdGhpcyBiYXNlPw==
先将题目base64解密

得到 Is this base?
下载附件
压缩包里面是flag.txt
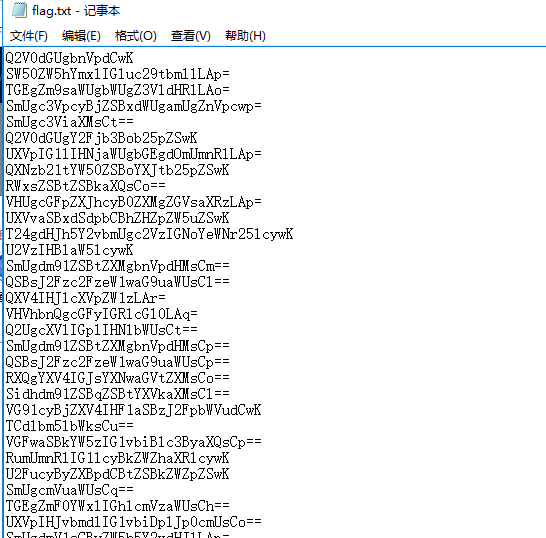
看起来是很多的base64加密,尝试解密第一行的字符串,使用base64解码得到:
Cette nuit,
确实是base64加密,于是我们多行base64解密,得到:
Cette nuit, Intenable insomnie, La folie me guette, Je suis ce que je fuis Je subis, Cette cacophonie, Qui me scie la t锚te, Assommante harmonie, Elle me dit, Tu paieras tes delits, Quoi qu'il advienne, On tra卯ne ses cha卯nes, Ses peines, Je voue mes nuits, A l'assasymphonie, Aux requiems, Tuant par depit, Ce que je seme, Je voue mes nuits, A l'assasymphonie, Et aux blasphemes, J'avoue je maudis, Tous ceux qui s'aiment, L'ennemi, Tapi dans mon esprit, F锚te mes defaites, Sans repit me defie, Je renie, La fatale heresie, Qui ronge mon 锚tre, Je veux rena卯tre, Rena卯tre, Je voue mes nuits, A l'assasymphonie, Aux requiems, Tuant par depit, Ce que je seme, Je voue mes nuits, A l'assasymphonie, Et aux blasphemes, J'avoue je maudis, Tous ceux qui s'aiment, Pleurent les violons de ma vie, La violence de mes envies, Siphonnee symphonie, Deconcertant concerto, Je joue sans toucher le Do, Mon talent sonne faux, Je noie mon ennui, Dans la melomanie, Je tue mes phobies, Dans la desharmonie, Je voue mes nuits, A l'assasymphonie, Aux requiems, Tuant par depit, Ce que je seme, Je voue mes nuits, A l'assasymphonie, Et aux blasphemes, J'avoue je maudis, Tous ceux qui s'aiment, Je voue mes nuits, A l'assasymphonie (l'assasymphonie), J'avoue je maudis, Tous ceux qui s'aiment
有的解码之后因为编码不同出现了乱码。
去百度搜索了一下,原来这个是杀人狂想曲的歌词
但是有的地方好像又跟原曲子不太一样,一般这种文字很多的第一反应就会想到字频加密,不过前一道题目已经考过这个点了。
跑了一下字频加密也没有什么结果,因为是base64加密,所以考虑到是base64隐写,找到一篇介绍base64隐写的文章,贴上链接:
https://www.tr0y.wang/2017/06/14/Base64steg/index.html
base64隐写我记得在一道题里面遇到过。
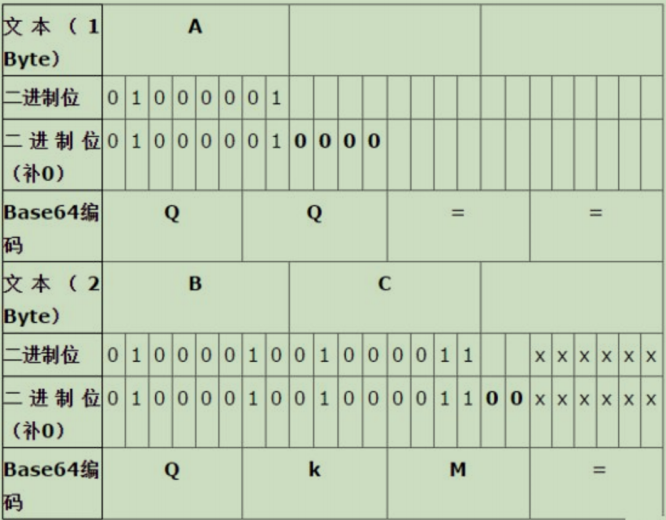
贴上官方解释,学习一波:
base64是将3个8比特转换成4个6比特,最小的转换单位是24比特(6和8最小公倍数)
因此如果原文内容不足三字节,有一部分比特解码时候不需要,但会组成编码后的某个字符。
如果官方题解没有看懂,简单说一下我自己的理解,base64隐写就是每一次base64编码之后不是都刚好占到了三个字节,当没有占到3个字节的时候,我们将base64编码最后的几个比特修改成我们想要隐藏的信息,同时并不影响base64的解码。
无处不在的隐写
知道原理之后用脚本跑一遍就行了
# -*- coding: cp936 -*-
b64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
with open('flag.txt', 'rb') as f:
bin_str = ''
for line in f.readlines():
stegb64 = ''.join(line.split())
rowb64 = ''.join(stegb64.decode('base64').encode('base64').split())
offset = abs(b64chars.index(stegb64.replace('=','')[-1])-b64chars.index(rowb64.replace('=','')[-1]))
equalnum = stegb64.count('=') #no equalnum no offset
if equalnum:
bin_str += bin(offset)[2:].zfill(equalnum * 2)
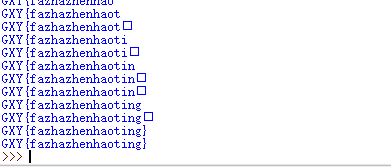
print ''.join([chr(int(bin_str[i:i + 8], 2)) for i in xrange(0, len(bin_str), 8)]) #8 位一组
得到:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号