数据库实验三--OpenGauss(查询和更新数据)
实验内容
- 查询操作
根据教材P79-94页所有查询实例,完成各类查询操作。 - 更新操作
根据教材P94-96上所有更新实例,完成各类更新操作(插入、修改和删除数据等),请注意标准SQL和openGauss中相应SQL语句相同与不同之处。
实验过程
首先启动并连接数据库:
su - omm
gs_om -t start
gsql -d postgres -p 26000 -r
进入到我们实验二创建的数据库db_cc中
\c db_cc
查询
不带where的简单查询
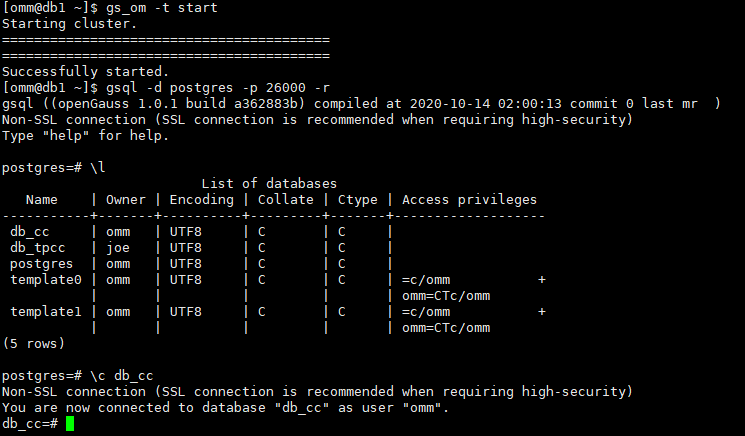
查询所有课程的信息
select * from courses;
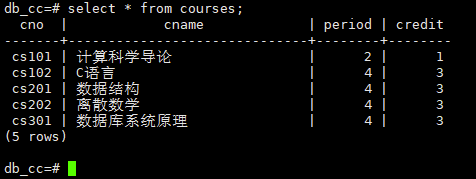
显示每位学生的年龄
select sname,2017-extract(year from birthday) as age from students ;
注意这里openGauss中不支持year()等函数,这里要用extract代替
显示所有学生的不同年龄
select distinct 2017-extract(year from birthday) as age from students;

带where的查询
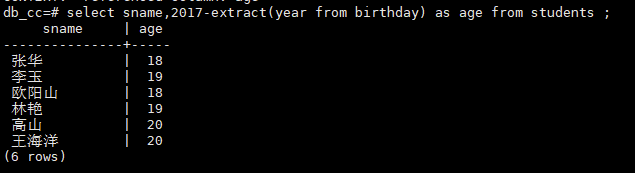
查询职称(Title)为教师的全体教师的姓名和性别
select tname, sex from teachers where title = '副教授';
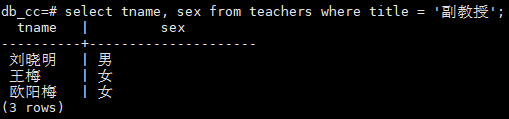
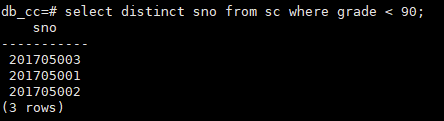
查询考试成绩低于90分的学生的学号
select distinct sno from sc where grade < 90;
查询出生年月在1997~1998的学生的姓名和专业
select sno,sname from students where extract(year from birthday) between 1997 and 1998;

LIKE表达式
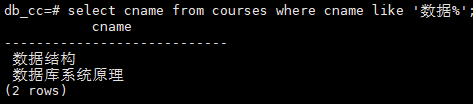
查询所有以“数据”开头的课程名
select cname from courses where cname like '数据%';

排序和分组
排序
ORDER BY可以进行查询结果的排序
ORDEF BY <排序列> [ASC|DESC] {,<排序列> {ASC|DESC}}
查询每位学生cs202课程的成绩,并将查询结果按照成绩降序排序
SELECT * FROM sc WHERE cno='cs202' ORDER BY Grade DESC;

聚集函数
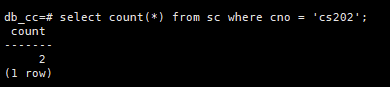
查询选修了cs202课程的学生人数
SELECT COUNT(*) FEOM SC WHERE cno = 'cs202';
查询cs102课程的最低分,平均分和最高分
select MIN(GRADE),AVG(Grade),MAX(Grade) from sc where cno = 'cs102';

分组
GROUP BY子句可用来进行分组
GROUP BY <分组列> {,<分组列>} {<分组选择条件>}
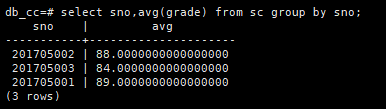
查询每个学生的平均成绩,输出学生的学号和平均成绩
select sno,avg(grade) from sc group by sno;
查询每个学生的平均成绩,并输出平均成绩大于85分的学生学号和平时成绩
需要注意的是:我们要去掉平均成绩小于或等于85的分组,需要是能够用到HAVING短语
select sno,avg(grade) from sc group by sno having avg(grade) >85;

连接查询
查询学号为201705001的学生的各科成绩,对每们课程显示名称和成绩。
select cname,grade
from sc,courses
where sc.cno = courses.cno and sno = '201705001';
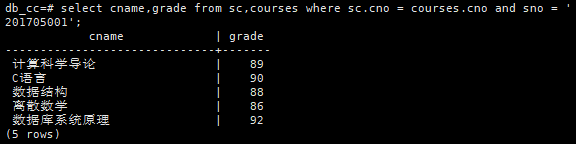
注意:cno既是sc的属性,也是courses的属性。为了避免二义性,我们必须要在前加上前缀。
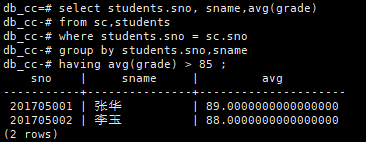
查询每个学生的平均成绩,并输出平均成绩大于85分的学生学号,姓名和平均成绩
select students.sno, sname,avg(grade)
from sc,students
where students.sno = sc.sno
group by students.sno,sname
having avg(grade) > 85 ;
自身连接
查询和张华专业相同的学生
select s2.sname
from students s1,students s2
where s1.speciality = s2.speciality and
s1.sname = '张华' and
s2.sname<>'张华' ;
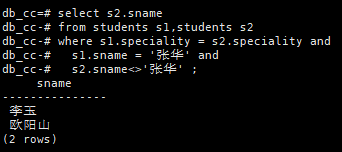
注意这里students出现了两次,我们用s1和s2来区分他们。
嵌套查询
IN-子查询
查询和张华专业相同的男学生,显示学号和姓名
select speciality
from students
where sname = '张华;
我们将上面作为子查询,我们得到改查询的sql语句为:
select sno, sname
from students
where sex = '男' and speciality in
(select speciality
from students
where sname = '张华');
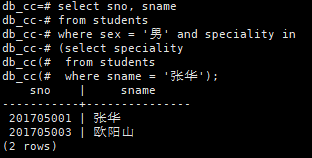
系统会先进性子查询,得到张华的专业。一般的,这是一个集合。(比如叫张华的不止一个)
然后,外层查询选择专业一致的男学生。
集合比较-子查询
sql允许将一个元素与子查询的结构集进行比较,这种量化比较表达式的常用形式是
<> 0 ALL | SOME | ANY <子查询>
查询比数学专业所有学生都小的其他专业的学号、姓名、专业和出生日期;
select birthday
from students
where speciality = '数学';
将它作为子查询
select sno,sname,speciality,year(birthday)
from students
where speciality<>'数学'and
year(birthday)>all(select year(birthday)
from students
where speciality = '数学');
存在量词--子查询
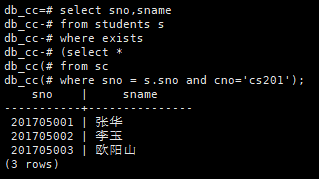
查询所有选修了cs201课程的学生的学号和姓名
select sno,sname
from students s
where exists
(select *
from sc
where sno = s.sno and cno='cs201');
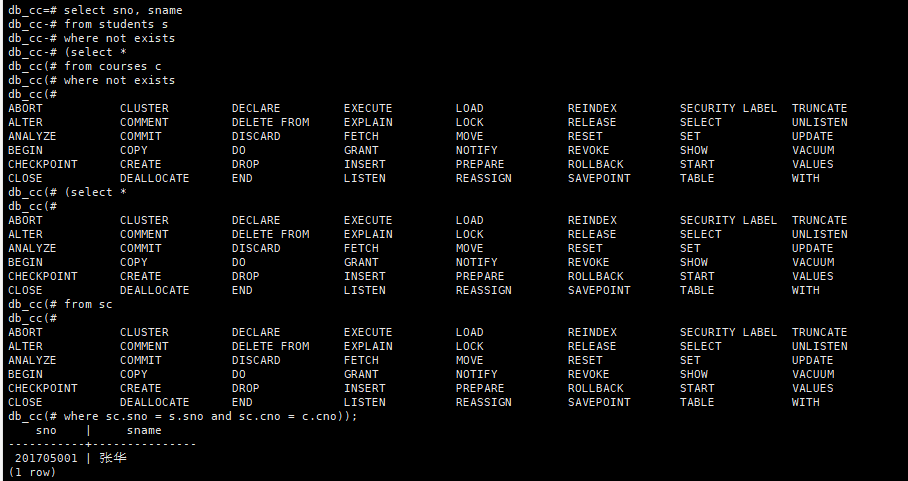
查询选修了全部课程的学生的学号和姓名
select sno, sname
from students s
where not exists
(select *
from courses c
where not exists
(select *
from sc
where sc.sno = s.sno and sc.cno = c.cno));
查询子查询结果中的重复元组
unique <子查询>
集合运算
sql支持集合运算
包括UNION, INTERSECT, EXCEPT
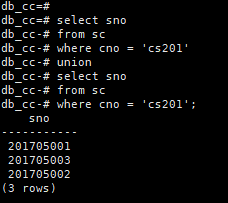
查询选修了cs201号课程或者选修了cs202号课程的学生的学号
select sno
from sc
where cno = 'cs201'
union
select sno
from sc
where cno = 'cs201';
数据更新
数据更新包括插入、删除和修改。
对应的sql语句分别为INSERT、DELETE、UPDATE
插入
插入单个元组
插入单个元组的INSERT格式为
INSERT INTO T [(A1,···,Ak)]
VALUES(C1,···,ck)
T通常是基本表,也可以是视图
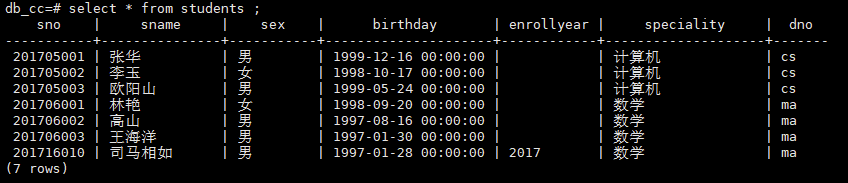
将学号为201716010、姓名为司马相如、性别为男、生日为1997-01-28,专业为数学,入学年份为2017,专业代码为ma的学生元组插入到表格中。
INSERT INTO students
VALUES ('201716010','司马相如','男','1997-01-28','2017','数学','ma');

向表sc中插入一个选课记录,登记为一个学号为201716010的学生选修了cs301的课程
INSERT INTO sc(sno,cno)
VALUES ('201716010','cs301');

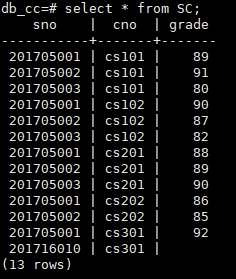
(这里在插入时没有插入成绩)
插入查询结果
INSERT INTO T[(A1,···.Ak)]
<查询表达式>
删除
可以使用DELETE来进行删除
DELETE FROM T
[WHERE <删除条件>]
删除学号为201716010的学生记录
delete from students
where sno = '201716010';
需要注意的是,201716010的记录在sc表中也有,并且sno在sc表中是外码,所以上面的指令直接执行会违反完整性约束。删除该同学的记录需要在sc表和students表中一块删除。本部分会在之后的实验中详细操作。
修改
使用update语句可以修改指定元组指定属性上的值
UPDATE T
SET A1 = e1,···,Ak = ek
[WHERE <修改条件>]
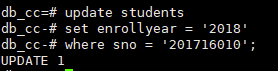
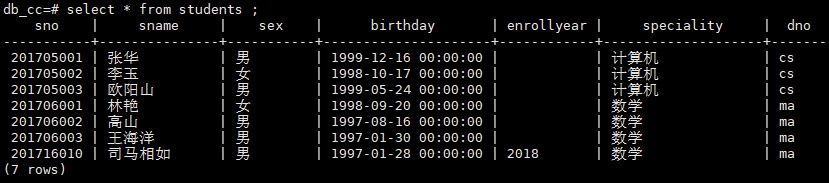
将学号为201716010的学生的专业入学时间修改为2018
update students
set enrollyear = '2018'
where sno = '201716010';
本文来自作者:CK_0ff,转载请注明原文链接:https://www.cnblogs.com/Ck-0ff/p/16112426.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号