BUAA_OO_2020_第一单元总结
OO第一单元作业主题为表达式求导,主要学习目标为熟悉面向对象思想,学会使用类来管理数据,感受分工协作的行为设计,建立程序鲁棒性概念。如今,第一单元的学习已落下帷幕,再次对于本人的学习心得和成果进行总结。
第一次作业
基于度量的代码结构分析
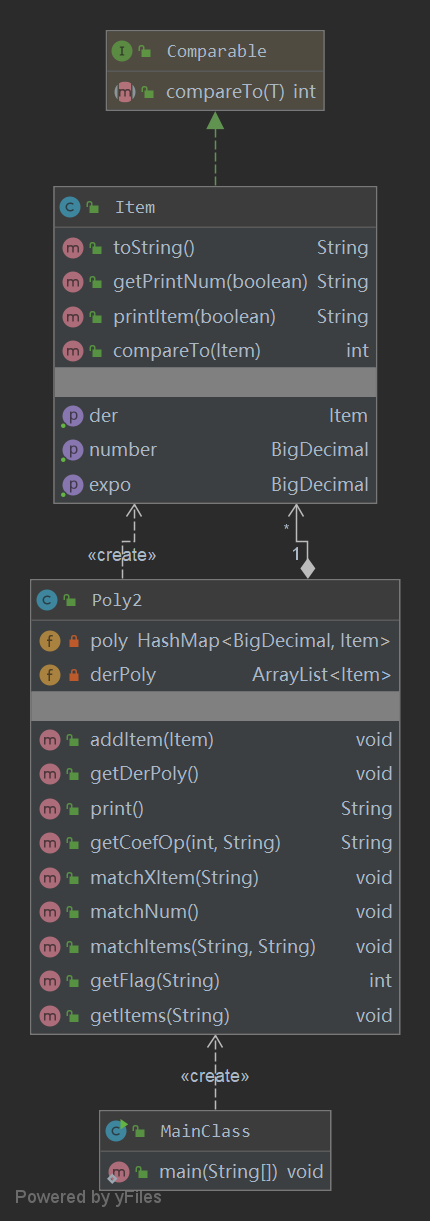
第一次作业为简单表达式求导,不涉及因子、嵌套等复杂结构,因此代码结构相对简单。UML类图如下:
-
架构
第一次作业我分了三个类,即主函数类、表达式类和项类。主函数类中只有Main函数,进行读取输入、创建表达式等功能。表达式类中含有存储项的HashMap用于存储表达式的所有项,还有ArrayList用于存储求导过后的所有项。
-
函数调用
在表达式类中含有求导函数,主类调用该函数后,会触发表达式中各个项调用自身的求导函数。同理,在主类调用表达式类中的print函数时,也会触发各个项调用自身的
printItem函数。
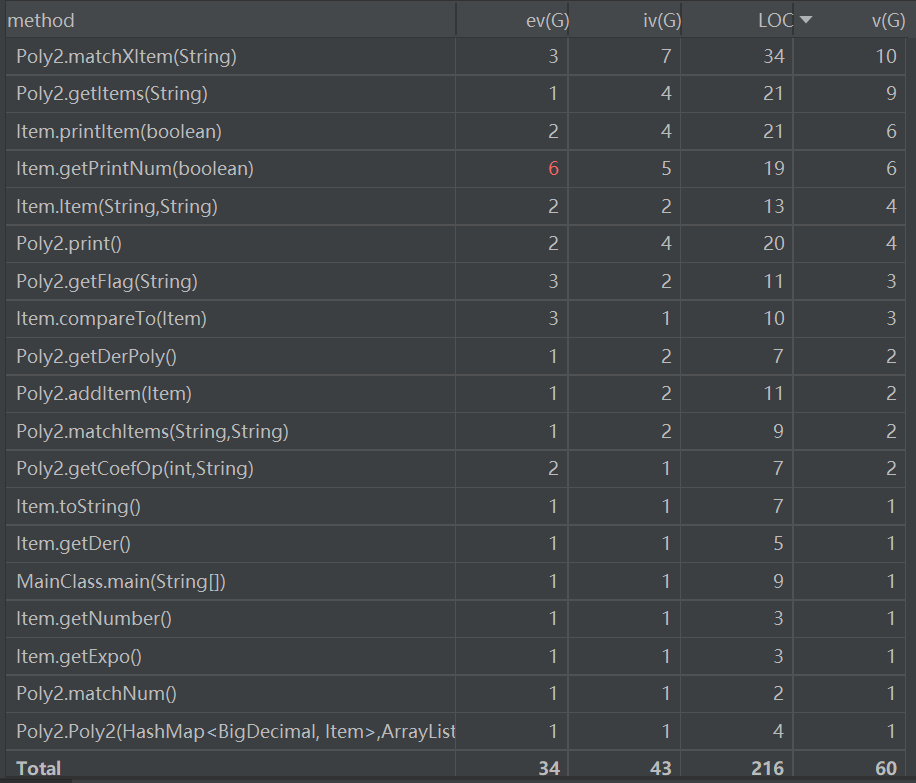
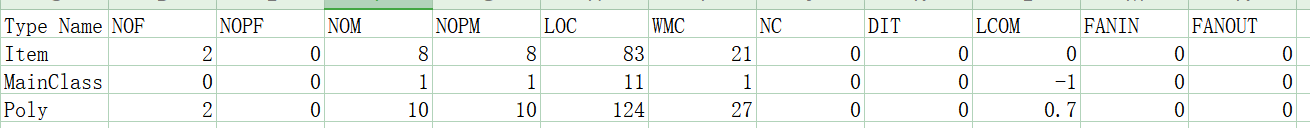
从代码复杂度分析数据可以看到,各个方法的圈复杂度、模块设计复杂度都在合理范围之内,唯有项类中getPrintNum函数的基本复杂度较高。经分析,这是因为该方法的if-else语句缺少else部分,导致选择结构不完整。三个类的LCOM(内聚缺乏度)值和各方法的iv(G)都较低,说明代码基本符合高内聚低耦合的设计标准。
关于测评
本次作业没有在中测、强测和互测中出现bug。
在互测时,共找到一个bug。有位同学在 + - 同时出现时会出现输出符号错误的问题。经排查,是项前的符号与常数省略后的符号处理不到位导致。可见,在对于输入表达式进行正规化和正则表达式匹配上,需要细心分析输入的形式化描述,防止理解出现偏差。
由于这次作业内容较少,没有过多bug出现。
第二次作业
基于度量的代码结构分析
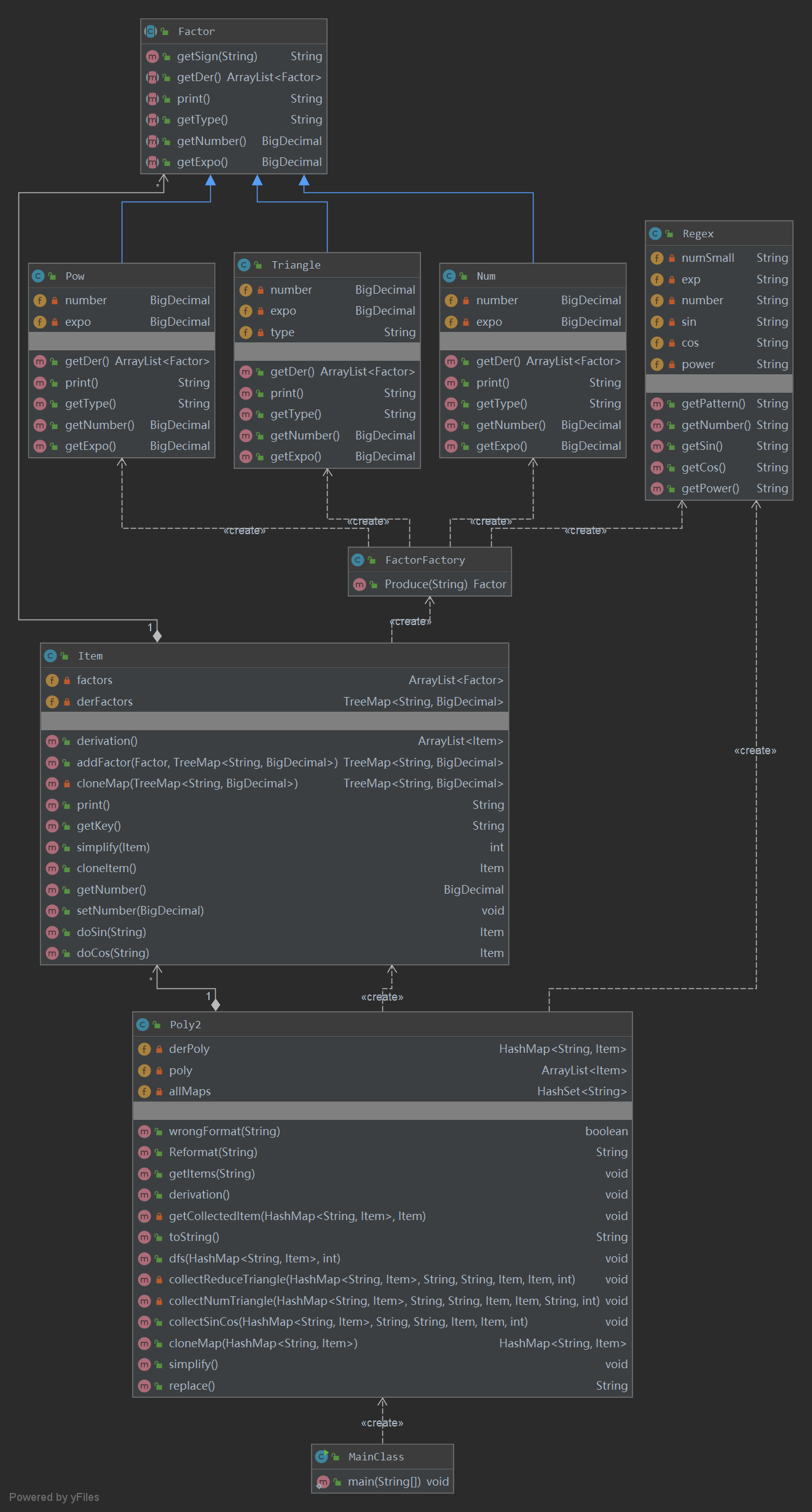
第二次作业在第一次的基础上增加了三角函数,并且增加了因子概念,即可以存在多个因子相乘的项。同时,首次引入WrongFormat判定要求。首先,代码核心部分UML类图如下:

全部代码UML类图如下:
-
架构
在本次作业中,我新增抽象类Factor,即因子类。常数因子、幂函数因子、三角函数因子都继承于Factor类。与第一次作业类似,Poly类中有存放Item的容器,而Item中也有存放Factor的容器。读入表达式后,通过正则匹配出项,随后引入工厂模式,讲解析出的因子传入工厂中,返回对应的因子。
-
函数调用
在进行求导、打印结果操作使,由主函数触发Poly类的对应方法,Poly遍历各个Item后触发Item的对应方法,Item触发Factor的对应方法,实现层层向下,各做各事的设计。
-
解析
另外,为了方便正则表达式的使用,专门设置一个正则表达式类,存放各类因子、项的正则表达式。在解析正则表达式时,采用层层向下的方法。先写出因子的表达式,再组合为项,思路会更加清晰。由于本次作业不涉及空白符导致的WF,因此我采用先去空白符,再将正则表达式匹配的项全部取出来,拼接成一个字符串,与原有字符串进行对比。如果不同,则WF的方法,规避了分类讨论。
-
性能
我使用的化简方法为:对当前的表达式进行dfs,每次遍历每两项,如果满足以下化简条件的任意一个,则进行相应的合并,并将合并后的再次dfs。如果合并后表达式长度短于当前,则更新。
asin**2F + bcos**2F
aF + bsin**2F
aF + bcos**2F
asin**4F - bcos**4F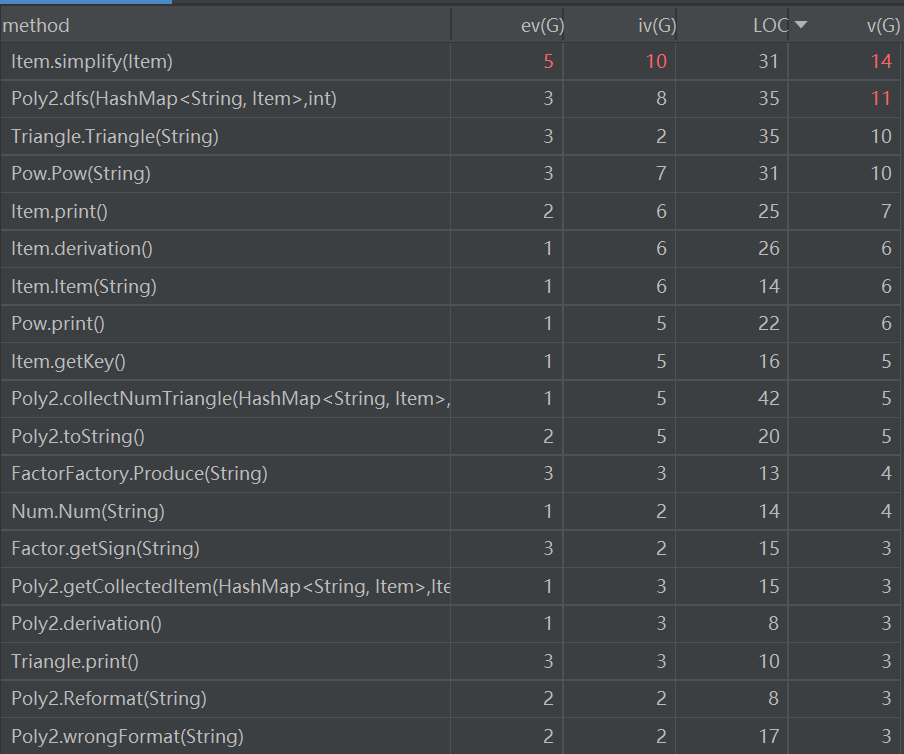


从代码复杂度分析数据可以看出,Item类simplify函数复杂度整体偏高,圈复杂度、基本复杂度和模块设计复杂度均超标。经分析,主要由于其对因子进行合并同类因子的化简操作,需要排查因子各个参数,导致复杂度由明显提升。Poly类用于化简三角函数的dfs函数圈复杂度较高,是由于三角函数化简情况过多,分支过多造成。
从类的层面看,Poly类由于和Item类的关联过高,导致LCOM值过高,内聚性不良。
从关联矩阵来看,Item类和Factor类的管理度明显高,是由于Item类需要管理Factor的生成、求导、打印等全部步骤。本次作业由于没有嵌套,没有出现循环依赖情况。
总体来看,本次代码复杂度相对良好,主要问题都出在三角函数的化简步骤上。如需改良代码,需要简化化简步骤,寻求更简略的化简方法。
另外,在进行本次作业设计时,应考虑到第三次作业的可扩展性问题,因此采用了此层次化的架构。
关于测评
本次作业没有在中测和互测中出现bug,在强测中TLE了一个点。出错原因为错判dfs函数RE和TLE到来的先后顺序,将三角函数化简的dfs层数限制过大,导致还未到强制跳出阶段就已经到达程序限定执行时间。改进方法为增加测定函数执行时间函数,当当前执行时间达到1900ms时,强制跳出dfs。
在互测中,找到两个bug。一位同学在化简过程中,对cos(x)进行求导后没有乘sin(x)导致错误。另一位同学在+x和-x多次重复出现时出现漏算现象。总结来看,两位同学的出现的错误都是在多重组合下出现的问题,即多种情况重叠才会出现。这体现出,当程序复杂度较高时,很有可能由于细节疏漏,导致多种情况重叠时出现bug。
第三次作业
基于度量的代码结构分析
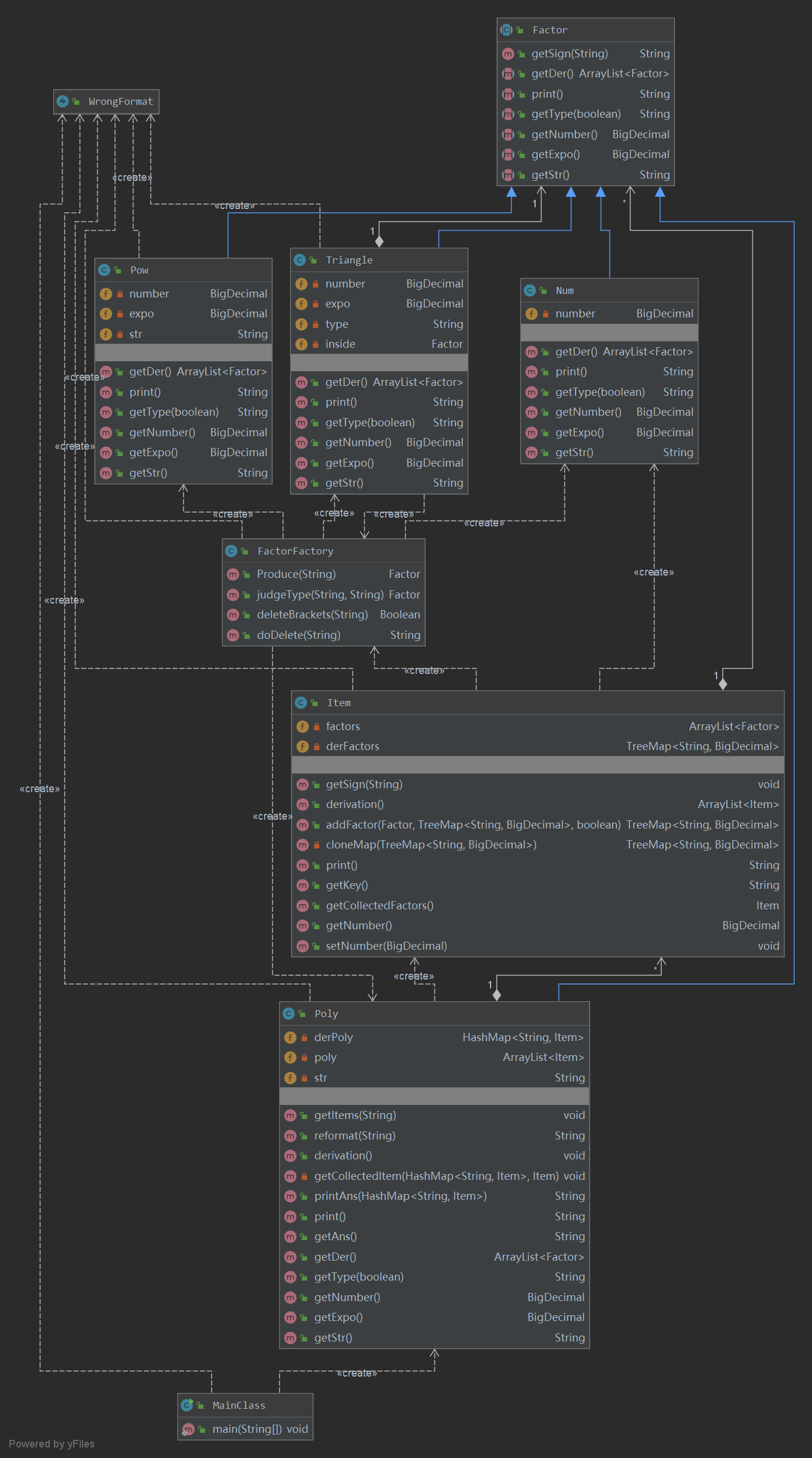
本次作业在前两次的基础上增加了表达式因子、三角函数嵌套即空白符导致的WF。使得作业的难度有所上升。主要部分UML类图如下:

全部结构的UML类图如下:
-
整体架构
由于在第二次作业时考虑到第三次作业的扩展问题,因此代码的大体架构并没有改动。由于增加了表达式因子,因此将Poly类也继承于Factor抽象类,并且可以通过FactorFactory进行工厂方法的解析。另外,由于增加嵌套,在三角函数类中增加一个属性:Factor类的因子。
-
表达式解析
由于本次作业存在嵌套,难以用正则表达式直接解析。我采用的是边解析边下沉的方法。拿到表达式后,首先对其正规化(将**替换为^, \t替换为空格等),方便以后的解析。在表达式类中,解析出各个项,处理表达式层面的WF情况(如空串、括号数量不对称等),并将字符串传入项中。在Item类中,解析出各个因子,处理项层面的WF情况(如符号数量错误),并将因子字符串传入FactorFactory中解析出对应的因子类型。在工厂中,就可以根据正则表达式匹配不同类型的因子,并且返回一些因子层面的WF(如三角函数保留字错误、指数超范围等)。
-
函数调用
求导和打印的函数调用结构与前两次作业类似,由主函数触发Poly的对应函数,进而下沉触发Item的,以此类推,最终返回完整结果。
-
性能
本次作业性能分仍然占据相当的比重,化简也是需要尽力而为的。然而,由于本次表达式结构复杂,化简难度也有所提升。我本次作业将重点放在表达式的化简(即合并同类项)上,而没有着眼于像第二次作业一样的三角函数化简。对于嵌套的表达式因子,直接调用化简函数合并同类项;对于求导过程中得到的项,可以在求导过程中合并。
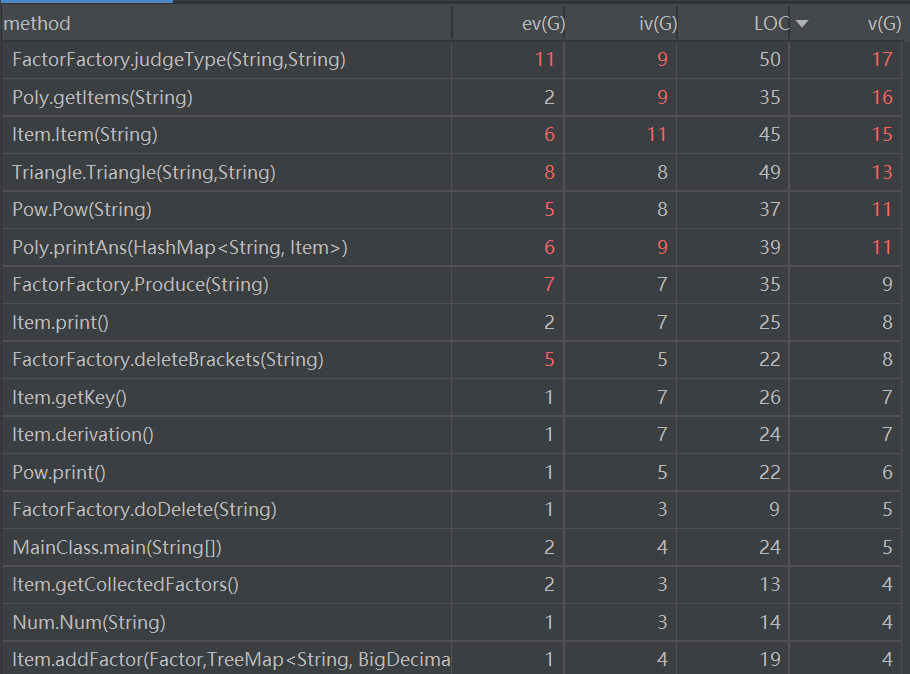
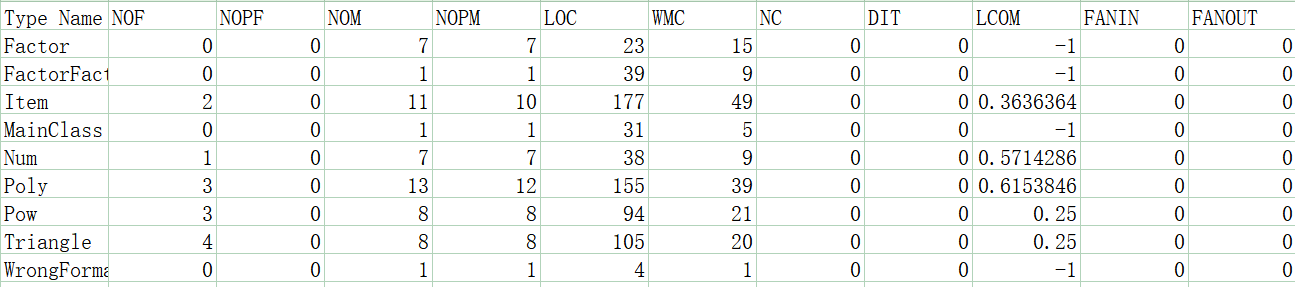
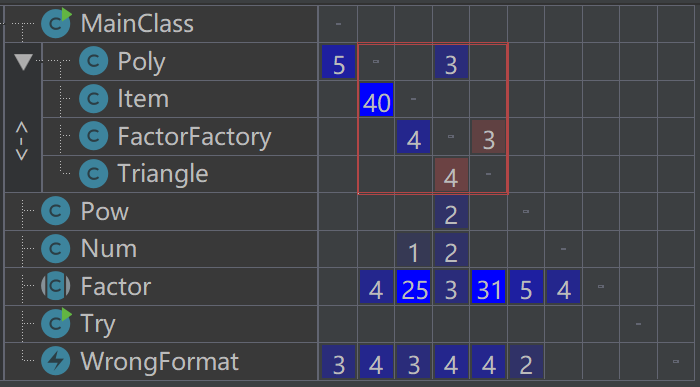
可以看到,随着作业结构的复杂度增加,代码的复杂度也有明显上升。本次作业复杂度超标的方法高达8个,其中,大部分类是延续第二次作业,复杂度提升的主要原因为增加了WF的判定,导致分支数明显上升。项由于牵扯各个因子的方法调用,耦合度也较高。方法行数基本控制在50之内。
在类的层次,表达式类的内聚合度依然较小。
从关联矩阵来看,表达式与项的关联度、项与因子的关联度依然很高,主要原因同第二次作业一样。这次作业,由于出现嵌套情,因此出现了循环依赖情况,即三角函数类由工厂产生,而三角函数又要调用工厂解析内部嵌套的因子种类。
关于测评
本次作业在中测、互测、强测中没有发现bug。
在互测中,共发现三个bug。
-
一位同学在处理
sin((0))*x的情况时出现RE,是由于对于空容器直接调用get所致。这类错误经常出现,因此要多加注意,在对容器进行取元素时,务必保证不越界。 -
一位同学在处理多层嵌套,如
(((((((x)))))))时,由于递归,会TLE。这反映的是代码架构的问题,在起初进行设计时,就应该适当考虑代码对于最坏情况的承受能力。 -
一位同学在合并同类项时忘记考虑表达式因子不能合并为含有指数的形式,输出
(x)**2类似情况。这是由于研读指导书不够仔细造成的。对于要求较多的题目,首先应该仔细研读指导书,提炼WF情况,不仅要又判别WF的能力,也要规避自己的输出出现WF。
在我进行自我测试时,代码出现的问题主要有以下几点。
-
同上述互测bug的第三个,我也出现在实现代码过程中忽视了输出不能WF的情况
-
对于正负号的含义区分不明。本次作业中正负号共有三种性质:项前运算符、项首+1/-1省略、常数因子。若是仅靠符号数量和出现位置判断,会十分繁琐,而且容易判错。应该采用规格化表达式、分割项、因子,并分层次判断的方法,而不是在最顶层就全部处理。
发现bug策略
覆盖性测试
在最初研读指导书的时候,我就对指导书定义的所有可能出现的情况进行罗列,尽量覆盖全部情况,得到最初版本的测试样例。覆盖包括且不仅包括:各因子单独出现、组合出现、0特殊情况、WF等。
另外,在代码构建阶段,遇到较为复杂的分支结构时,我对于能走向各个分支的样例进行枚举,尽量做到覆盖重要分支结构的每一种分支走向。
自动测评机
对于第2、3次作业,很多错误的出现都是多种情况叠加后产生的,很难通过手动构造发现,因此需要构建对拍机。我才用python脚本+批处理的方式,构建自动测评机。python负责自动生成样例、正确答案计算、输出答案计算,.bat用于对比输出区别。
针对第三次作业,判定输出不是WF也是测试的重点之一,因此采用将输出结果再作为输入,并判断输出的结果中是否有WF信息的方法。
工厂模式
从第二次作业开始,我就采用了工厂模式对于各类因子进行创建操作。首先,建立Factor抽象类,其中包含求导、打印方法。然后将常数因子、三角函数因子、幂函数因子、表达式因子继承于Factor,并实现其中方法。
使用工厂模式可以使创建过程透明于用户,并且对于项层次中遍历处理Factor提供了很大的方便。
另外,工厂模式也具有良好的扩展性。当第二次作业的基本架构完成后,第三次作业只需要将表达式类也继承于Factor,并实现其中方法即可。
心得体会
-
寒假pre认真做很重要
在寒假的两次pre中,我初步建立了面向对象的设计思想,并了解了类、接口、继承等基本概念,并且根据指导书的建议,初次去学习了工厂模式。研读优秀同学代码也让我学到了很多更加优越的设计方式。这使得我在应对第一次作业时不会手足无措,更加从容。
-
善用讨论区很重要
在三次作业的完成过程中,讨论区的同学们为我解决问题的进度提供了巨大的帮助。包括以下几点:
-
抽象类和接口的比较,帮助我在第二次作业的架构上做出选择
-
自动测评机的构建,给予我构建对拍机的思路
-
三角函数化简的策略
-
x**2=x*x的神仙优化 -
...
在此感谢同学们的热心分享!
-
-
可扩展性得早做准备
重构虽好,但还是挺累人的,如果能提前考虑可扩展性,对后续工作的开展会有很大帮助。
-
面向对象设计的优越性
在完成作业过程中,我逐渐发现面向对象的设计成果确实比面向过程更加清晰,思路也更加结构化。

