

针对多模匹配问题的解决方案:字典树 + KMP 算法 ==> AC 自动机
1. 字典树的暴力匹配:


1 #include <iostream> 2 #include <string> 3 #include <cstring> 4 #include <vector> 5 #include <unordered_set> 6 using namespace std; 7 8 #define MAX_N 1000 9 #define BASE 26 10 11 struct Trie{ 12 bool flag; 13 int next[BASE]; 14 Trie(): flag(false) { 15 for(int i = 0; i < BASE; ++i) next[i] = 0; 16 } 17 }trie[MAX_N]; 18 19 int root, count, cmp_cnt; 20 21 void insert(string pattern) { 22 int temp = root; 23 for(int i = 0; pattern[i]; ++i) { 24 int index = pattern[i] - 'a'; 25 if(0 == trie[temp].next[index]) trie[temp].next[index] = count++; 26 temp = trie[temp].next[index]; 27 } 28 trie[temp].flag = true; 29 return; 30 } 31 32 unordered_set<string> find(string source) { 33 unordered_set<string> ret; 34 for(int i = 0; source[i]; ++i) { 35 int temp = root; 36 string cur = ""; 37 //cmp_cnt 按照 状态转移个数算; 38 int cnt = cmp_cnt++; 39 for(int j = i; source[j]; ++j) { 40 int index = source[j] - 'a'; 41 if(!trie[temp].next[index]) break; 42 cmp_cnt++; 43 cur += source[j]; 44 temp = trie[temp].next[index]; 45 if(trie[temp].flag) ret.insert(cur); 46 } 47 #ifdef DEBUG 48 cout << "i:" << i << ", cnt is " << (cmp_cnt - cnt) << endl;; 49 #endif 50 } 51 return ret; 52 } 53 54 #define CMP_OUT(ans, cnt) printf("%10s get %3ld strings, cmp cnt is %6d\n", __FILE__, ans, cnt) 55 void output(unordered_set<string> &ans) { 56 #ifdef DEBUG 57 auto iter = ans.begin(); 58 for(int i = 0, I = ans.size(); i < I; ++i) { 59 if(i) printf(", "); 60 printf("%s", iter->c_str()); 61 ++iter; 62 } 63 printf("\n"); 64 #endif 65 return; 66 } 67 68 int main() 69 { 70 root = 1, count = 2, cmp_cnt = 0; 71 int cnt = 0; 72 string pattern = "", source = ""; 73 cin >> cnt; 74 for(int i = 0; i < cnt; ++i) { 75 cin >> pattern; 76 insert(pattern); 77 } 78 79 cin >> source; 80 81 unordered_set<string> ans = find(source); 82 CMP_OUT(ans.size(), cmp_cnt); 83 output(ans); 84 return 0; 85 }
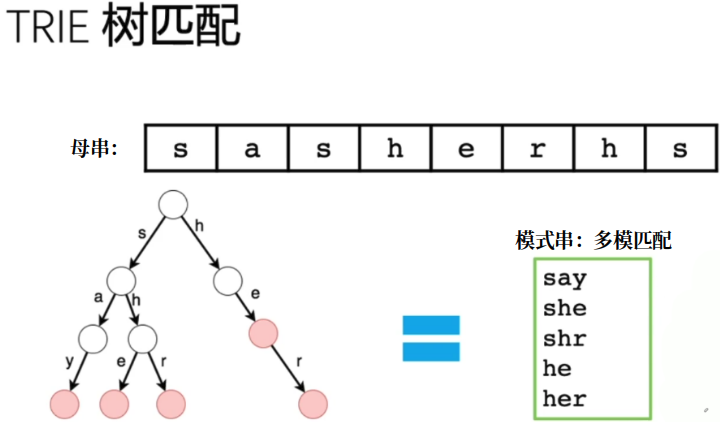
但是在字典树暴力匹配过程中,每次匹配失败以后,就会从下一个位置从新开始匹配。存在重复匹配的过程。那么如果能够利用KMP 的思想,避免重复判断的过程提高效率。
将每个节点增加一个失配链接点,失配以后可以直接跳到对应的下一个节点进行判断,避免重复判断。
代码中实现AC 自动机中模式串字典树过程,可以通过BFS实现。因为每个节点的失配链接点,一定是在其上层节点中(字典树定义 + KMP)。
1 #include <iostream> 2 #include <unordered_set> 3 #include <string> 4 #include <queue> 5 6 using namespace std; 7 #define BASE 26 8 int cmp_cnt; 9 10 struct Node { 11 Node() : flag(false), fail(nullptr), s("") { 12 for(int i = 0; i < BASE; ++i) next[i] = nullptr; 13 } 14 bool flag; 15 Node *next[BASE]; 16 Node *fail; 17 string s; 18 }; 19 20 class Automaton{ 21 public: 22 Automaton() { 23 proot = new Node(); 24 } 25 void insert(string s) { 26 Node *p = proot; 27 for(int i = 0; s[i]; ++i) { 28 int index = s[i] - 'a'; 29 if(!p->next[index]) p->next[index] = new Node(); 30 p = p->next[index]; 31 } 32 if(!p->flag) { 33 p->flag = true; 34 p->s = s; 35 } 36 return; 37 } 38 39 void buildAC() { 40 queue<Node*> que; 41 for(int i = 0; i < BASE; ++i) { 42 if(!proot->next[i]) continue; 43 proot->next[i]->fail = proot; 44 que.push(proot->next[i]); 45 } 46 while(!que.empty()) { 47 Node *p = que.front(), *f = nullptr; 48 que.pop(); 49 for(int i = 0; i < BASE; ++i) { 50 if(!p->next[i]) continue; 51 que.push(p->next[i]); 52 f = p->fail; 53 while(f && !f->next[i]) f = f->fail; 54 if(f) p->next[i]->fail = f->next[i]; 55 else p->next[i]->fail = proot; 56 } 57 } 58 return; 59 } 60 61 unordered_set<string> find(string source) { 62 cmp_cnt = 0; 63 unordered_set<string> ret; 64 Node *p = proot, *f = nullptr; 65 for(int i = 0; source[i]; ++i) { 66 int index = source[i] - 'a'; 67 //找到存在的值 68 //my if(!p->next[index]) { 69 //my while(p && !p->next[index]) p = p->fail; 70 //my if(!p) { 71 //my p = proot; 72 //my continue; 73 //my } 74 //my } 75 //my p = p->next[index]; 76 //my f = p; 77 //my do{ 78 //my if(f->flag) ret.insert(f->s); 79 //my f = f->fail; 80 //my } while(f->fail); 81 82 //update 83 //状态转移 84 while(p && !p->next[index]) p = p->fail, cmp_cnt++; 85 if(!p) p = proot; 86 else p = p->next[index]; 87 cmp_cnt++; 88 //提取结果 89 f = p; 90 while(f) { 91 if(f->flag) ret.insert(f->s); 92 f = f->fail; 93 } 94 } 95 return ret; 96 } 97 98 private: 99 Node *proot; 100 }; 101 102 #define CMP_OUT(ans, cnt) printf("%10s get %3ld strings, cmp cnt is %6d\n", __FILE__, ans, cnt) 103 void output(unordered_set<string> &ans) { 104 #ifdef DEBUG 105 auto iter = ans.begin(); 106 for(int i = 0, I = ans.size(); i < I; ++i) { 107 if(i) printf(", "); 108 printf("%s", iter->c_str()); 109 ++iter; 110 } 111 printf("\n"); 112 #endif 113 return; 114 } 115 116 117 int main() 118 { 119 int cnt = 0; 120 cin >> cnt; 121 Automaton tree; 122 string pattern = ""; 123 for(int i = 0; i < cnt; ++i) { 124 cin >> pattern; 125 tree.insert(pattern); 126 } 127 cin >> pattern; 128 129 tree.buildAC(); 130 131 unordered_set<string> ans = tree.find(pattern); 132 133 CMP_OUT(ans.size(), cmp_cnt); 134 output(ans); 135 136 return 0; 137 }
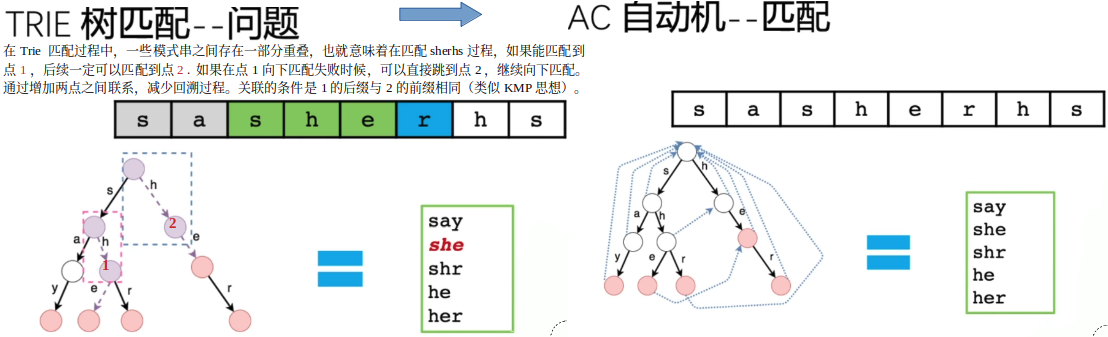
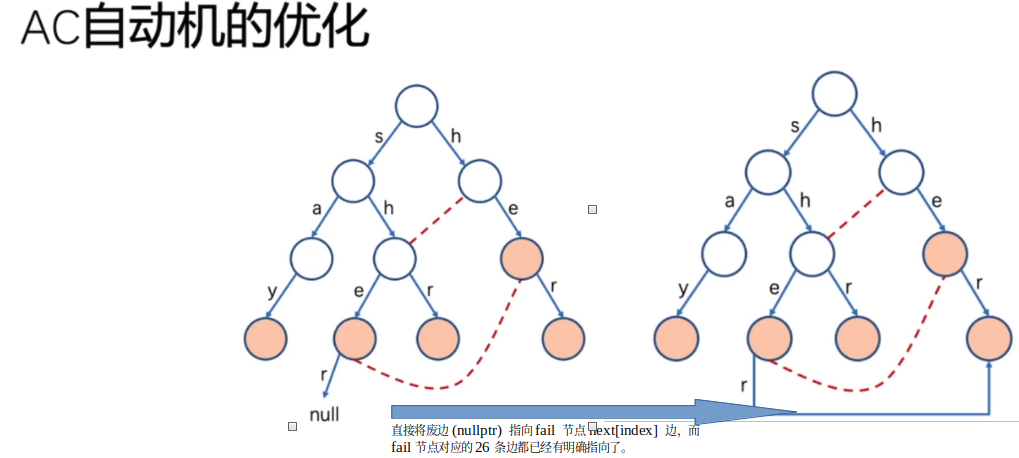
对于上面的AC 自动机基本版本中,每次都是因为不存在下一条边,然后指向失配链接点。
在每次失配操作过程:先判断next[index] 是否有值 =>不存在 => 转移到某个父节点失配链接点存在next[index]节点/或 root,如果将这个next[index] 一步到位直接指向最终结果,那么操作变成了:直接转到 next[index] 对应节点(存在:向下;不存在:转移到第一个父节点对应的失配链接点对应的next[index] 节点);这就相当于废物利用,将原来的空边都一步到位指向了具体的节点;
这也保证了每个节点的对应的每一个输入都有了一个确定的值。
1 #include <iostream> 2 #include <string> 3 #include <unordered_set> 4 #include <queue> 5 6 using namespace std; 7 #define BASE 26 8 int cmp_cnt; 9 struct Node { 10 Node():flag(false), fail(nullptr), p_s(nullptr){ 11 for(int i = 0; i < BASE; ++i) next[i] = nullptr; 12 } 13 bool flag; 14 Node *fail; 15 string *p_s; 16 Node *next[BASE]; 17 }; 18 19 class Automaton{ 20 public: 21 Automaton(): p_root(new Node()){} 22 void insert(string pattern) { 23 Node *p = p_root; 24 for(auto &x : pattern){ 25 int ind = x - 'a'; 26 if(!p->next[ind]) p->next[ind] = new Node(); 27 p = p->next[ind]; 28 } 29 p->flag = true; 30 p->p_s = new string(pattern); 31 } 32 33 void buildAC(){ 34 queue<Node *> que; 35 for(int i = 0; i < BASE; ++i) { 36 if(!p_root->next[i]) { 37 p_root->next[i] = p_root; 38 continue; 39 } 40 que.push(p_root->next[i]); 41 p_root->next[i]->fail = p_root; 42 } 43 44 while(!que.empty()) { 45 Node *p = que.front(); 46 que.pop(); 47 for(int i = 0; i < BASE; ++i) { 48 if(!p->next[i]) { 49 //这也是理解AC 自动机优化的关键点,将next[i] 指向变成最终对应的点; 50 p->next[i] = p->fail->next[i]; 51 continue; 52 } 53 que.push(p->next[i]); 54 p->next[i]->fail = p->fail->next[i]; 55 //与上一行实现的结果一样 56 // Node *f = p->fail; 57 // while(f && f->next[i] == p_root) f = f->fail; 58 // if(!f) f = p_root; 59 // else f = f->next[i]; 60 // p->next[i]->fail = f; 61 } 62 } 63 return; 64 } 65 66 unordered_set<string> find(string s) { 67 cmp_cnt = 0; 68 Node *cur = p_root; 69 unordered_set<string> ret; 70 for(int i = 0; s[i]; ++i) { 71 //状态转移 72 int index = s[i] - 'a'; 73 cur = cur->next[index]; 74 cmp_cnt++; 75 //提取结果 76 Node *f = cur; 77 while(f) { 78 if(f->flag) ret.insert(*f->p_s); 79 f = f->fail; 80 } 81 } 82 return ret; 83 } 84 85 private: 86 Node *p_root; 87 }; 88 89 #define CMP_OUT(ans, cnt) printf("%10s get %3ld strings, cmp cnt is %6d\n", __FILE__, ans, cnt) 90 void output(unordered_set<string> &ans) { 91 #ifdef DEBUG 92 auto iter = ans.begin(); 93 for(int i = 0, I = ans.size(); i < I; ++i) { 94 if(i) printf(", "); 95 printf("%s", iter->c_str()); 96 ++iter; 97 } 98 printf("\n"); 99 #endif 100 return; 101 } 102 103 int main() 104 { 105 int cnt = 0; 106 Automaton tree; 107 cin >> cnt; 108 string pattern = ""; 109 for(int i = 0; i < cnt; ++i) { 110 cin >> pattern; 111 tree.insert(pattern); 112 } 113 cin >> pattern; 114 115 tree.buildAC(); 116 unordered_set<string> ans = tree.find(pattern); 117 118 CMP_OUT(ans.size(), cmp_cnt); 119 output(ans); 120 121 return 0; 122 }
62 child inherits copies open message queue descriptors description as corresponding file descriptor kkb panda world test history expansion is usually immediately after a complete it takes place in two parts the first to determine which from list use during substitution second select portions of that for inclusion current one selected and are acted upon words various modifiers available manipulate line broken word thehistorylibrarysupportsahistoryexpansionfeaturethatisidenticaltothehistoryexpansioninbashthissectiondescribeswhatsyntaxfeaturesareavailablehistoryexpansionsintroducewordsfromthehistorylistintotheinputstreammakingiteasytorepeatcommandsinserttheargumentstoapreviouscommandintothecurrentinputlineorfixerrorsinpreviouscommandsquicklyhistoryexpansionisusuallyperformedimmediatelyafteracompletelineisreadittakesplaceintwopartsthefirstistodeterminewhichlinefromthehistorylisttouseduringsubstitutionthesecondistoselectportionsofthatlineforinclusionintothecurrentonethelineselectedfromthehistoryistheeventandtheportionsofthatlinethatareacteduponarewordsvariousmodifiersareavailabletomanipulatetheselectedwordsthelineisbrokenintowordsinthesamefashionasbashdoeswhenreadinginputsothatseveralwordsthatwouldotherwisebeseparatedareconsideredonewordwhensurroundedbyquotesseethedescriptionofhistorytokenizebelowhistoryexpansionsareintroducedbytheappearanceofthehistoryexpansioncharacterwhichisbydefaultonlybackslashandsinglequotescanquotethehistoryexpansioncharacterforkcreatesanewprocessbyduplicatingthecallingprocessthenewprocessisreferredtoasthechildprocessthecallingprocessisreferredtoastheparentprocessthechildprocessandtheparentprocessruninseparatememoryspacesatthetimeofforkbothmemoryspaceshavethesamecontentmemorywritesfilemappingsmmapdandunmappingsmunmapdperformedbyoneoftheprocessesdonotaffecttheotherthechildprocessisanexactduplicateoftheparentprocessexceptforthefollowingpointsthechildhasitsownuniqueprocessidandthispiddoesnotmatchtheidofanyexistingprocessgroupsetpgiddorsessionthechildsparentprocessidisthesameastheparentsprocessidthechilddoesnotinherititsparentsmemorylocksmlockdmlockalldprocessresourceutilizationsgetrusagedandcputimecounterstimesdareresettozerointhechildthechildssetofpendingsignalsisinitiallyemptysigpendingdthechilddoesnotinheritsemaphoreadjustmentsfromitsparentsemopdthechilddoesnotinheritprocessassociatedrecordlocksfromitsparentfcntldontheotherhanditdoesinheritfcntldopenfiledescriptionlocksandflockdlocksfromitsparentthechilddoesnotinherittimersfromitsparentsetitimerdalarmdtimercreatedthechilddoesnotinheritoutstandingasynchronousigooperationsfromitsparentaioreaddaiowritednordoesitinheritanyasynchronousiocontextsfromitsparentseeiosetupdtheprocessattributesintheprecedinglistareallspecifiedinposixdtheparentandchildalsodifferwithrespecttothefollowinglinuxspecificprocessattribute
======================= **代码演示** =======================
如上。
======================= **经典问题** =======================
======================= **应用场景** =======================
NFA 与 DFA 的定义:
DFA: Deterministic Finite State Automata 确定的有穷自动机;
NFA: Non-Deterministic Finite State Automata : 不确定的有穷自动机,对于输入的符号,有两种或两种以上可能的状态,所以是不确定的。
传统的字典树更类似与DFA。
AC 自动机某种意义上来讲也是一种状态机,原始代码实现的AC 自动机是NFA,因为对于每次的输入,需要判断然后决定走哪一步;而 优化以后的AC 自动机算是非严格意义上的DFA,因为对于每次输入,直接就确定了下一步。
另外KMP/Shift-And 算法都算NFA, Shift-And 每次匹配结果都是包含当前所有匹配过点的结果集合。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号