

======================= **基础知识** =======================
哈希表:为了解决快速索引树问题的结构
数组中根据下标可以O(1) 实现数据获取; 但是在实际应用中,可能要根据复杂的数据结构来查找数据;
所以要实现将任意数据 到 数组下标的映射就可以实现任意类型数据之间的关联,实现O(1) 查找;
哈希函数: 任意数据 到 数组下标的映射; 体现设计能力(数学能力),有很多论文!
哈希操作: 高维空间 到 低维空间 的映射;当多个 高维空间数据 映射到 同一个低维空间时候,就产生了哈希冲突;
哈希冲突: 无法避免,高维 到 低维 压缩过程中 必然会产生重叠;重点是解决冲突;
冲突处理:有下面4个处理方法, 各个方法要看具体设计方法,不是一层不变的;
开放定址法: 在已经算出的下标,再计算得到下一个下标;例如线性探测法:在冲突下标 + 1;
二次再散射: 第一次冲突 + 12, 第二次冲突+ 22,三次:32 ...
注意点: //对于这种方法,在反复插入,删除操作中,如何保证查找过程一定能找到最后一位,也很重要;例如插入多次后,某个位置发生多次冲突,然后删除中间的值,对于后面的值查找如何保证一定能找到冲突后面的所有情况,也要考虑;
706. 设计哈希映射 :开放定址法 VS 拉链法;这里开放定址法对于冲突处理并不完善,只好通过增加数据size 解决;


1 //开放定址法: 2 class MyHashMap { 3 public: 4 #define MULP 3 5 #define MAX_NUM 100000 //为了通过,减少因为冲突处理,导致的不断更新下标,然后删除中间冲突值,造成后面值查找出错; 6 //或者考虑更新冲突处理方法 7 typedef pair<int, int> PII; 8 vector<PII*> arr; 9 int cnt; 10 MyHashMap(int c = MAX_NUM): cnt(0), arr(c, nullptr){} 11 12 int hashFunc(int key, int value) { 13 int t = 1; 14 int index = key % arr.size(); 15 16 while(arr[index] && arr[index]->first != key) { 17 index = (index + (t * t)) % arr.size(); 18 t += 1; 19 20 if(t > 50) { 21 expand(); 22 t = 1; 23 index = key % arr.size(); 24 } 25 } 26 27 return index; 28 } 29 30 void expand() { 31 MyHashMap mh(cnt * MULP); 32 for(auto &x : arr) { 33 if(!x) continue; 34 mh.put(x->first, x->second); 35 delete x; 36 x = nullptr; 37 } 38 *this = mh; 39 return; 40 } 41 42 void put(int key, int value) { 43 int index = hashFunc(key, value); 44 45 if(!arr[index]) { 46 arr[index] = new PII(make_pair(key, value)); 47 cnt += 1; 48 } else arr[index]->second = value; 49 50 if(cnt * MULP > arr.size()) expand(); 51 return; 52 } 53 54 int get(int key) { 55 int index = hashFunc(key, 0); 56 if(arr[index]) return arr[index]->second; 57 58 return -1; 59 } 60 61 void remove(int key) { 62 int index = hashFunc(key, 0); 63 64 if(arr[index]) { 65 delete arr[index]; 66 arr[index] = nullptr; 67 cnt -= 1; 68 } 69 return; 70 } 71 }; 72 73 /** 74 * Your MyHashMap object will be instantiated and called as such: 75 * MyHashMap* obj = new MyHashMap(); 76 * obj->put(key,value); 77 * int param_2 = obj->get(key); 78 * obj->remove(key); 79 */ 80 81 //original 82 83 //拉链法: 84 struct Node{ 85 int key, val; 86 Node *next; 87 88 Node(int k = -1, int v = -1): key(k), val(v), next(nullptr) {} 89 90 void insert_after(Node* np) { 91 np->next = next; 92 next = np; 93 return; 94 } 95 96 void remove_next(Node* pp) { 97 Node *rp = pp->next; 98 if(!rp) return ; 99 pp->next = rp->next; 100 delete rp; 101 return; 102 } 103 104 }; 105 class MyHashMap { 106 private: 107 int hash_table(int key) { return key & 0x7FFFFFFF;} 108 int cnt ; 109 vector<Node> arr; 110 public: 111 /** Initialize your data structure here. */ 112 MyHashMap(int n = 10): cnt(0), arr(n,Node()) {} 113 114 /** value will always be non-negative. */ 115 void put(int key, int value) { 116 int ind = hash_table(key) % arr.size(); 117 Node *now = &arr[ind]; 118 while(now->next && now->next->key != key) now = now->next; 119 if(now->next) { 120 now->next->val = value; 121 return; 122 } 123 Node *np = new Node{key, value}; 124 now->insert_after(np); 125 return; 126 } 127 128 /** Returns the value to which the specified key is mapped, or -1 if this map contains no mapping for the key */ 129 int get(int key) { 130 int ind = hash_table(key) % arr.size(); 131 Node *now = &arr[ind]; 132 while(now->next && now->next->key != key) now = now->next; 133 if(now->next == nullptr) return -1; 134 else return now->next->val; 135 } 136 137 /** Removes the mapping of the specified value key if this map contains a mapping for the key */ 138 void remove(int key) { 139 int ind = hash_table(key) % arr.size(); 140 Node *now = &arr[ind]; 141 while(now->next && now->next->key != key) now = now->next; 142 if(now->next) now->remove_next(now); 143 return; 144 } 145 }; 146 147 /** 148 * Your MyHashMap object will be instantiated and called as such: 149 * MyHashMap* obj = new MyHashMap(); 150 * obj->put(key,value); 151 * int param_2 = obj->get(key); 152 * obj->remove(key); 153 */
建立公共溢出区: 将所有的冲突的值都放在一个公共的溢出缓冲区(这个缓冲区可以用其他数据结构维护,例如RB tree) ; 必须借助其他数据结构实现;
链式地址法(拉链法): 将冲突值通过链表方式实现共存,每个区间对应的是一个链表头节点;这种方法最为推荐;
再hash 法: 设计多个哈希函数,多到保证不冲突;实际应用中很难设计足够多的哈希函数;但是可以配合其他方案共同使用;
装填因子: 存储元素个数 / 哈希总容量 = 0.75 , 一般操作装填因子,就要考虑扩容;要不然有些冲突处理方式在数据接近饱和时候,效率会变得极低;
布隆过滤器: 存储空间与元素数量无关; 能够大概率判断没有存在,但是存在一定损耗(误判率);
传统哈希表:存储空间与元素数量有关; 这也是在设计哈希表时候要合理判断数据范围,及扩容的必要性;
布隆过滤器基本思想是: 通过多个哈希函数,然后将得到的下标映射值 分别标记在存储区; 在判断是否存在时,如果对应的所有hash 映射下标都是标记过的,大概率就是存在的;否则肯定不存在;
这里对于哈希函数设计要求也很多;
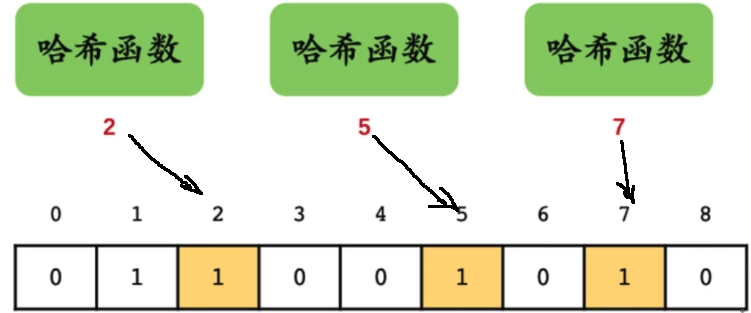
哈希链表:哈希能够实现快速查找;链表能够实现数据自由增删改,只是查找效率O(n); 所以混合在一起实现既能快速查找;
146. LRU 缓存 :这里锻炼程序封装能力;在链表章节中, 也提到哈希链表;
1 class LRUCache { 2 public: 3 struct Node{ 4 int key, val; 5 Node *prev, *next; //LRU 顺序 6 Node(int k = -1, int v = -1, Node *p = nullptr, Node *n = nullptr): key(k), val(v), prev(p), next(n) {} 7 void remove_this(){ 8 if(prev) { 9 prev->next = next; 10 next->prev = prev; 11 prev = nullptr; 12 next = nullptr; 13 } 14 return; 15 } 16 void insert_before(Node *pn) { 17 pn->next = this; 18 pn->prev = prev; 19 prev->next = pn; 20 prev = pn; 21 return; 22 } 23 Node *pop_next(){ 24 Node *temp = next; 25 next = temp->next; 26 temp->next->prev = this; 27 return temp; 28 } 29 }; 30 31 unordered_map<int, Node*> arr; //借助STL中的 unordered_map 32 int cnt, capacity; 33 Node *head, *tail; 34 35 LRUCache(int capacity): cnt(0), capacity(capacity), head(new Node()), tail(new Node()){ 36 head->prev = tail; 37 head->next = tail; 38 tail->prev = head; 39 tail->next = head; 40 } 41 42 void update_seq(Node *pn){ 43 pn->remove_this(); 44 tail->insert_before(pn); 45 if(cnt > capacity) { 46 arr.erase(head->next->key); 47 delete head->pop_next(); 48 cnt -= 1; 49 } 50 return; 51 } 52 53 int get(int key) { 54 int ret = -1; 55 if(arr.find(key) != arr.end()){ 56 ret = arr[key]->val; 57 update_seq(arr[key]); 58 } 59 return ret; 60 } 61 62 void put(int key, int value) { 63 if(arr.find(key) != arr.end()) { 64 arr[key]->val = value; 65 } else { 66 arr[key] = new Node(key, value); 67 cnt += 1; 68 } 69 update_seq(arr[key]); 70 return; 71 } 72 }; 73 74 /** 75 * Your LRUCache object will be instantiated and called as such: 76 * LRUCache* obj = new LRUCache(capacity); 77 * int param_1 = obj->get(key); 78 * obj->put(key,value); 79 */ 80 81 //哈希表,以及LRU 不断更新关系,全部自己实现;冲突处理采用拉链法,大数据时候超时,主要还是hashFunc/冲突处理都太粗糙了; 82 //不过主要锻炼自己能力 83 // 84 85 //MY class LRUCache { 86 //MY struct Node { 87 //MY Node(int k = -2, int v = -2): key(k), val(v), 88 //MY prev(nullptr), next(nullptr), Hprev(nullptr), Hnext(nullptr) {} 89 //MY 90 //MY Node(int k, int v, Node* HP): key(k), val(v), 91 //MY prev(nullptr), next(nullptr), Hprev(HP), Hnext(nullptr) { 92 //MY HP->Hnext = this; 93 //MY } 94 //MY void remove_this() { 95 //MY prev->next = next; 96 //MY next->prev = prev; 97 //MY prev = nullptr; 98 //MY next = nullptr; 99 //MY return; 100 //MY } 101 //MY 102 //MY void insert_prev(Node *pn) { 103 //MY prev->next = pn; 104 //MY pn->prev = prev; 105 //MY pn->next = this; 106 //MY prev = pn; 107 //MY return; 108 //MY } 109 //MY 110 //MY void pop_next() { 111 //MY Node *rp = next; 112 //MY rp->remove_this(); 113 //MY 114 //MY rp->Hprev->Hnext = rp->Hnext; 115 //MY if(rp->Hnext) rp->Hnext->Hprev = rp->Hprev; 116 //MY delete rp; 117 //MY rp = nullptr; 118 //MY return; 119 //MY } 120 //MY 121 //MY int key, val; 122 //MY Node *prev, *next, *Hprev, *Hnext; //H:同一组index 对应的关系; 123 //MY }; 124 //MY public: 125 //MY int capacity, size; 126 //MY vector<Node*> addr; 127 //MY Node *head, *end; 128 //MY 129 //MY int hashFunc(int key) { 130 //MY return key; 131 //MY } 132 //MY LRUCache(int capacity): capacity(capacity), size(0), 133 //MY addr(capacity, new Node()), head(new Node()), end(new Node()){ 134 //MY head->next = end; 135 //MY head->prev = end; 136 //MY end->prev = head; 137 //MY end->next = head; 138 //MY } 139 //MY 140 //MY void update_seq(Node *temp) { 141 //MY end->insert_prev(temp); 142 //MY if(size > capacity){ 143 //MY head->pop_next(); 144 //MY size -= 1; 145 //MY } 146 //MY return; 147 //MY } 148 //MY 149 //MY int get(int key) { 150 //MY int ret = -1; 151 //MY int index = hashFunc(key) % capacity; 152 //MY Node *temp = addr[index]; 153 //MY while(temp->Hnext && temp->Hnext->key != key) temp = temp->Hnext; 154 //MY if(temp->Hnext) { 155 //MY ret = temp->Hnext->val; 156 //MY temp->Hnext->remove_this(); 157 //MY update_seq(temp->Hnext); 158 //MY } 159 //MY return ret; 160 //MY } 161 //MY 162 //MY void put(int key, int value) { 163 //MY int index = hashFunc(key) % capacity; 164 //MY Node *temp = addr[index]; 165 //MY while(temp->Hnext && temp->Hnext->key != key) temp = temp->Hnext; 166 //MY if(temp->Hnext) { 167 //MY temp = temp->Hnext; 168 //MY temp->val = value; 169 //MY temp->remove_this(); 170 //MY } else { 171 //MY temp = new Node(key, value, temp); 172 //MY size += 1; 173 //MY } 174 //MY update_seq(temp); 175 //MY } 176 //MY }; 177 178 /** 179 * Your LRUCache object will be instantiated and called as such: 180 * LRUCache* obj = new LRUCache(capacity); 181 * int param_1 = obj->get(key); 182 * obj->put(key,value); 183 */
======================= **代码演示** =======================
1. BKDR hash:将字符映射成整型方法; 冲突处理使用 开放定址法;
1 #include <iostream> 2 #include <string> 3 #include <vector> 4 using namespace std; 5 6 class HashTable { 7 public: 8 HashTable(int n = 100): cnt(0) , data(n), flag(n){} 9 void insert(string s) { 10 int ind = hash_func(s) % data.size(); //计算hash 值 11 recalc_ind(ind, s); //冲突处理 12 if(!flag[ind]) { 13 data[ind] = s; 14 flag[ind] = true; 15 cnt++; 16 } 17 //哈希扩容: 超过装填因子,就要扩容; 18 if(cnt * 100 > data.size() * 75) { 19 expand(); 20 } 21 return ; 22 } 23 bool find(string s) { 24 int ind = hash_func(s) % data.size(); 25 recalc_ind(ind, s); 26 return flag[ind]; 27 } 28 private: 29 int cnt; 30 vector<string> data; 31 vector<bool> flag; //是否存储了数据: 0 : 没有; 1 : 存了; 32 int hash_func(string &s) { 33 int seed = 131, hash = 0; 34 for(int i = 0 ; s[i]; i++){ 35 hash = hash * seed + s[i]; //BKDR hash 36 } 37 return hash & 0x7FFFFFFF; 38 } 39 //开放定址法: 40 void recalc_ind(int &ind, string &s) { 41 int t = 1; 42 while(flag[ind] && s != data[ind]) { 43 ind += t * t; 44 t++; 45 ind %= data.size(); 46 } 47 return; 48 } 49 void expand(){ 50 int n = data.size() * 2; 51 HashTable h(n); 52 for(int i = 0; i < data.size(); i++) { 53 if(!flag[i]) continue; 54 h.insert(data[i]); 55 } 56 *this = h; 57 return; 58 } 59 60 61 }; 62 63 int main() 64 { 65 int op; 66 string s; 67 HashTable h; 68 while(cin >> op >> s) { 69 switch(op) { 70 case 1: h.insert(s); break; 71 case 2: cout << "find " << s << "in h : " << h.find(s) << endl; break; 72 73 } 74 } 75 76 return 0; 77 }
2. 公共溢出区法:冲突解决中,不需要重新计算index, 只要把值放在公共溢出区即可;find 方法也更新了;
1 #include <iostream> 2 #include <string> 3 #include <vector> 4 #include <set> 5 using namespace std; 6 7 class HashTable { 8 public: 9 HashTable(int n = 100): cnt(0) , data(n), flag(n){} 10 void insert(string s) { 11 int ind = hash_func(s) % data.size(); //计算hash 值 12 recalc_ind(ind, s); //冲突处理 13 if(!flag[ind]) { 14 data[ind] = s; 15 flag[ind] = true; 16 }else { 17 buff.insert(s); 18 } 19 20 cnt++; 21 if(cnt * 100 > data.size() * 75) { 22 expand(); 23 } 24 return ; 25 } 26 bool find(string s) { 27 int ind = hash_func(s) % data.size(); 28 if(!flag[ind]) return false; 29 if(flag[ind] && data[ind] == s) return true; 30 return buff.find(s) != buff.end(); 31 } 32 private: 33 int cnt; 34 vector<string> data; 35 vector<bool> flag; //是否存储了数据: 0 : 没有; 1 : 存了; 36 set<string> buff; 37 38 int hash_func(string &s) { 39 int seed = 131, hash = 0; 40 for(int i = 0 ; s[i]; i++){ 41 hash = hash * seed + s[i]; //BKDR hash 42 } 43 return hash & 0x7FFFFFFF; 44 } 45 //公共溢出区 46 void recalc_ind(int &ind, string &s) { 47 return; 48 } 49 void expand(){ 50 int n = data.size() * 2; 51 HashTable h(n); 52 for(int i = 0; i < data.size(); i++) { 53 if(!flag[i]) continue; 54 h.insert(data[i]); 55 } 56 for(auto x : buff){ 57 h.insert(x); 58 } 59 *this = h; 60 return; 61 } 62 }; 63 64 int main() 65 { 66 int op; 67 string s; 68 HashTable h; 69 while(cin >> op >> s) { 70 switch(op) { 71 case 1: h.insert(s); break; 72 case 2: cout << "find " << s << "in h : " << h.find(s) << endl; break; 73 74 } 75 } 76 77 return 0; 78 }
3. 拉链法:将所有值放在链表中存储;更新了查找方式;
1 #include <iostream> 2 #include <string> 3 #include <vector> 4 using namespace std; 5 6 struct Node { 7 string str; 8 Node *pre, *next; //其实不用pre 也可以,当前实现中并没有用到pre 9 Node(string s1 = "", Node* p1 = nullptr, Node* n1 = nullptr) : str(s1), pre(p1), next(n1){} 10 11 void insert_front(string n1) { 12 Node *np = new Node(n1); 13 if(next) next->pre = np; 14 np->next = next; 15 np->pre = this; 16 next = np; 17 return; 18 } 19 }; 20 class HashTable { 21 public: 22 HashTable(int n = 100): cnt(0) , data(n, new Node()){} 23 void insert(string s) { 24 int ind = hash_func(s) % data.size(); //计算hash 值 25 recalc_ind(ind, s); //冲突处理 26 //rev1 : 没有查重 27 //rev1 data[ind]->insert_front(s); 28 //rev1 cnt++; 29 //rev1 if(cnt * 100 > data.size() * 75) { 30 //rev1 expand(); 31 //rev1 } 32 Node *p = data[ind]; 33 while(p->next && p->next->str != s) p = p->next; 34 if(nullptr == p->next) { 35 p->insert_front(s); 36 cnt++; 37 //拉链法装填因子可以 > 1 38 if(cnt > data.size() * 3) expand(); 39 } 40 return ; 41 } 42 bool find(string s) { 43 int ind = hash_func(s) % data.size(); 44 Node *temp = data[ind]->next; 45 while(temp) { 46 if(temp->str == s) return true; 47 temp = temp->next; 48 } 49 return false; 50 } 51 private: 52 int cnt; 53 vector<Node*> data; 54 int hash_func(string &s) { 55 int seed = 131, hash = 0; 56 for(int i = 0 ; s[i]; i++){ 57 hash = hash * seed + s[i]; //BKDR hash 58 } 59 return hash & 0x7FFFFFFF; 60 } 61 //拉链法 62 void recalc_ind(int &ind, string &s) { 63 return; 64 } 65 void expand(){ 66 int n = data.size() * 2; 67 HashTable h(n); 68 for(int i = 0; i < data.size(); i++) { 69 Node *p = data[i]->next; 70 if(!p) continue; 71 h.insert(p->str); 72 p = p->next; 73 } 74 *this = h; 75 return; 76 } 77 78 79 }; 80 81 int main() 82 { 83 int op; 84 string s; 85 HashTable h; 86 while(cin >> op >> s) { 87 switch(op) { 88 case 1: h.insert(s); break; 89 case 2: cout << "find " << s << "in h : " << h.find(s) << endl; break; 90 91 } 92 } 93 94 return 0; 95 }
4. 再hash 法,需要收集足够多hash 转换方法,将高维数据 映射成低维数据;
另外在STL 中对于基于哈希表的数据结构,在初始化中,自定义数据结构要提供对应的hasher方法;
======================= **经典问题** =======================
======================= **应用场景** =======================
1. STL 中 unordered_map/unordered_set/unordered_multimap/unordered_multiset 实现都是通过哈希表实现;
2. 布隆过滤器: 大数据(爬虫,url 重复判定); 信息安全有要求(因为即使拿到存储的数据,也无法判断原始数据);
3. 哈希链表实现 LRU(Least Recently Used); 里面应用复杂链表(剑指 Offer 35. 复杂链表的复制);
1 //哈希表,以及LRU 不断更新关系,全部自己实现;冲突处理采用拉链法,大数据时候超时,主要还是hashFunc/冲突处理都太粗糙了; 2 //不过主要锻炼自己能力,leetcode146 也有用现有容器,实现封装; 3 // 4 5 class LRUCache { 6 struct Node { 7 Node(int k = -2, int v = -2): key(k), val(v), 8 prev(nullptr), next(nullptr), Hprev(nullptr), Hnext(nullptr) {} 9 10 Node(int k, int v, Node* HP): key(k), val(v), 11 prev(nullptr), next(nullptr), Hprev(HP), Hnext(nullptr) { 12 HP->Hnext = this; 13 } 14 void remove_this() { 15 prev->next = next; 16 next->prev = prev; 17 prev = nullptr; 18 next = nullptr; 19 return; 20 } 21 22 void insert_prev(Node *pn) { 23 prev->next = pn; 24 pn->prev = prev; 25 pn->next = this; 26 prev = pn; 27 return; 28 } 29 30 void pop_next() { 31 Node *rp = next; 32 rp->remove_this(); 33 34 rp->Hprev->Hnext = rp->Hnext; 35 if(rp->Hnext) rp->Hnext->Hprev = rp->Hprev; 36 delete rp; 37 rp = nullptr; 38 return; 39 } 40 41 int key, val; 42 Node *prev, *next, *Hprev, *Hnext; //H:同一组index 对应的关系; 43 }; 44 public: 45 int capacity, size; 46 vector<Node*> addr; 47 Node *head, *end; 48 49 int hashFunc(int key) { 50 return key; 51 } 52 LRUCache(int capacity): capacity(capacity), size(0), 53 addr(capacity, new Node()), head(new Node()), end(new Node()){ 54 head->next = end; 55 head->prev = end; 56 end->prev = head; 57 end->next = head; 58 } 59 60 void update_seq(Node *temp) { 61 end->insert_prev(temp); 62 if(size > capacity){ 63 head->pop_next(); 64 size -= 1; 65 } 66 return; 67 } 68 69 int get(int key) { 70 int ret = -1; 71 int index = hashFunc(key) % capacity; 72 Node *temp = addr[index]; 73 while(temp->Hnext && temp->Hnext->key != key) temp = temp->Hnext; 74 if(temp->Hnext) { 75 ret = temp->Hnext->val; 76 temp->Hnext->remove_this(); 77 update_seq(temp->Hnext); 78 } 79 return ret; 80 } 81 82 void put(int key, int value) { 83 int index = hashFunc(key) % capacity; 84 Node *temp = addr[index]; 85 while(temp->Hnext && temp->Hnext->key != key) temp = temp->Hnext; 86 if(temp->Hnext) { 87 temp = temp->Hnext; 88 temp->val = value; 89 temp->remove_this(); 90 } else { 91 temp = new Node(key, value, temp); 92 size += 1; 93 } 94 update_seq(temp); 95 } 96 }; 97 98 /** 99 * Your LRUCache object will be instantiated and called as such: 100 * LRUCache* obj = new LRUCache(capacity); 101 * int param_1 = obj->get(key); 102 * obj->put(key,value); 103 */
4. 哈希函数 对于 文本串匹配中的应用(单模匹配):
文本串长度为 n, 模式串长度为 m, 暴力匹配时间复杂度为 O(n * m);
使用hash 函数映射模式串,然后将 文本串分别使用哈希函数,并与模式串hash值比较,如果相同,进行暴力匹配;
这里对于hash 函数,最好是能够减少计算次数,包含滑动窗口法的hash 函数最好,每次只需要 减去前面移出一位,加上 后面新进一位;
如果hash 值范围为 p, 时间复杂度为: O( n + n / p * m); //n: 遍历文本串求hash 值, n / p * m : 文本串中匹配并进行暴力匹配次数;
如果p 足够大,每种组合都对应不一样的hash 值,则时间复杂度为 O(n + m) (遍历文本串做hash, 以及一次暴力匹配);
5. 作为相互映射关系,实现相互链接;(数组是 展开的函数; 函数是 压缩的数组; 哈希实现高维数据 到 低维数据 映射; --> 哈希表实现了复杂结构(高维数据)的 展开)
1 class Solution { 2 public: 3 unordered_map<string, string> arr; 4 // Encodes a URL to a shortened URL. 5 string encode(string longUrl) { 6 string cur = "http://tinyurl.com/" + longUrl.substr(longUrl.rfind("/")); 7 arr[cur] = longUrl; 8 return cur; 9 } 10 11 // Decodes a shortened URL to its original URL. 12 string decode(string shortUrl) { 13 return arr[shortUrl]; 14 } 15 }; 16 17 // Your Solution object will be instantiated and called as such: 18 // Solution solution; 19 // solution.decode(solution.encode(url));

 浙公网安备 33010602011771号
浙公网安备 33010602011771号