

======================= 基础知识 =======================
包含数据域(内置类型,任意定义的结构), 指针域(绝对地址:pointer, 相对地址:下标...),通过指针域的值指向下一个位置,形成一个线性结构;
复杂度:插入O(1), 查找O(n), 更新O(1), 删除O(1);
特点:不适合快速定位查找数据,适合动态的插入和删除数据场景
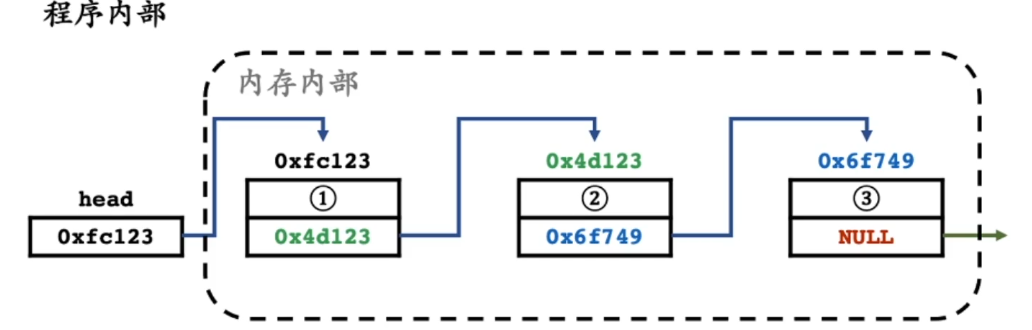
- 扩展:
- 单向链表: 只能向下寻找下一个节点
- 双向链表: 可以向下寻找下一个节点,也可以向上寻找上一个节点;
- hash 链表:通过对每一个链表对应的数据存储到一个hash map 中,这样可以快速获取某个值对应的节点位置,从而解决上面说的查找复杂度O(n)-> O(1);
![]()
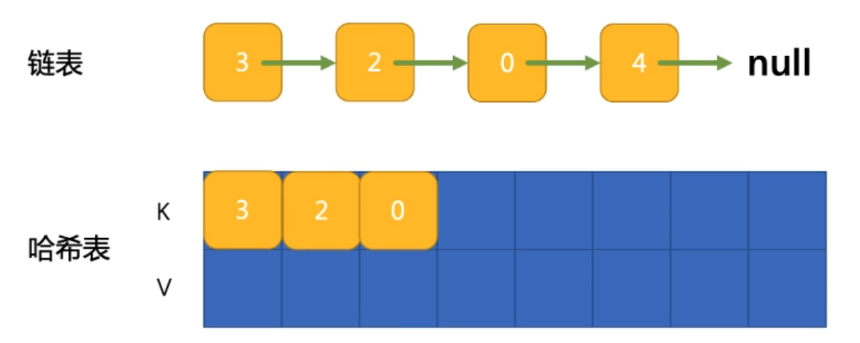
======================= 代码演示 =======================
简单实现(基于Node);


1 struct Node { 2 Node(int val): data(val), next(nullptr){} 3 Node(): Node(-1) {} 4 int data; 5 Node *next; 6 }; 7 8 int main(){ 9 Node *head = new Node(1); 10 head->next = new Node(2); 11 head->next->next = new Node(3); 12 13 Node *temp = head; 14 while(temp->next) { 15 cout << temp->data << "->"; 16 temp = temp->next; 17 } 18 cout << temp->data << endl; 19 return 0; 20 }
简单实现(基于数组):同种数据结构可能存在多种表现形式(trie实现方式也是这样),重点是数据结构自身特点以及针对解决的问题;
1 int data[10]; 2 int nt[10]; 3 4 void add(int index, int nxt, int val) { 5 nt[index] = nxt; 6 data[nxt] = val; 7 } 8 int main() 9 { 10 int head = 4; 11 add(4, 7, 1); 12 add(7, 2, 2); 13 add(2, 8, 3); 14 add(8, 5, 9); 15 16 while(nt[head] != 0) { 17 printf("%d -> ", data[nt[head]]); 18 head = nt[head]; 19 } 20 printf("\n"); 21 return 0; 22 }
面对对象方式:
1 struct Node { 2 Node(int val): data(val), next(nullptr){} 3 Node(): Node(-1) {} 4 int data; 5 Node *next; 6 }; 7 8 class List{ 9 Node *pre; 10 int size; 11 12 public: 13 List(): size(0) { 14 pre = new Node(); //前置节点为-1; 15 } 16 17 void __del(Node *pn) { 18 if(pn->next) __del(pn->next); 19 delete pn; 20 return; 21 } 22 ~List() {__del(pre);} 23 24 void addNode(int val) { 25 Node *temp = pre; 26 while(temp->next) temp = temp->next; 27 temp->next = new Node(val); 28 size += 1; 29 return; 30 } 31 bool searchNode(int val) { 32 if(!size) return false; 33 Node *temp = pre; 34 while(temp->next) { 35 if(temp->next->data == val) return true; 36 temp = temp->next; 37 } 38 return false; 39 } 40 41 void delNode(int val) { 42 if(!size) return; 43 Node *temp = pre; 44 while(temp->next) { 45 if(temp->next->data == val) { 46 temp->next = temp->next->next; 47 size -= 1; 48 break; 49 } 50 temp = temp->next; 51 } 52 return ; 53 } 54 55 void output() { 56 if(!size) return; 57 Node *temp = pre->next; 58 while(temp->next){ 59 cout << temp->data << "->"; 60 temp = temp->next; 61 } 62 cout << temp->data << endl; 63 return; 64 } 65 66 int getSize() { 67 return size; 68 } 69 }; 70 71 int main() { 72 List *l1 = new List(); 73 for(int i = 10; i < 25; ++i) l1->addNode(i); 74 cout << "list size is: " << l1->getSize() << endl; 75 l1->output(); 76 77 cout << "search 10 in list is " << l1->searchNode(10) << endl;; 78 79 cout << "search 25 in list is " << l1->searchNode(25) << endl;; 80 81 l1->delNode(18); 82 l1->output(); 83 return 0; 84 }
OS 中对于内存使用(待更新):
======================= 经典问题 =======================
1. 环形链表,以及找到第一个重复节点(leetcode141, 202)
解决思路:
a.通过hash map 实现对环形链表中每一个节点存储下面,当到达重复出现的位置hash map 中可以找到;
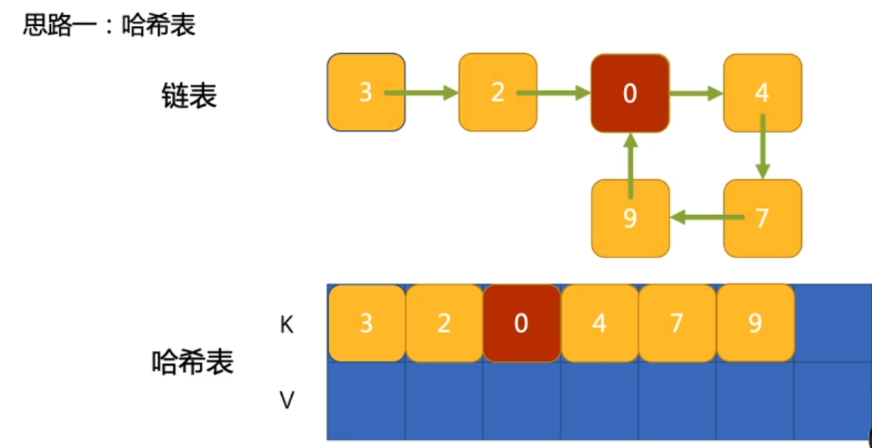
1 class Solution { 2 public: 3 bool hasCycle(ListNode *head) { 4 if(!head) return false; 5 unordered_set<ListNode*> us; 6 while(head) { 7 if(us.find(head) != us.end()) return true; 8 us.insert(head); 9 head = head->next; 10 } 11 return false; 12 } 13 };
快慢指针(fast_pointer:step = 2; slow_pointer: step = 1): 无环链表中,快慢指针永远不会相遇,但是环状链表终究会重合;
注意点: 快慢指针重合的条件:在开始时快慢指针也是重合的!
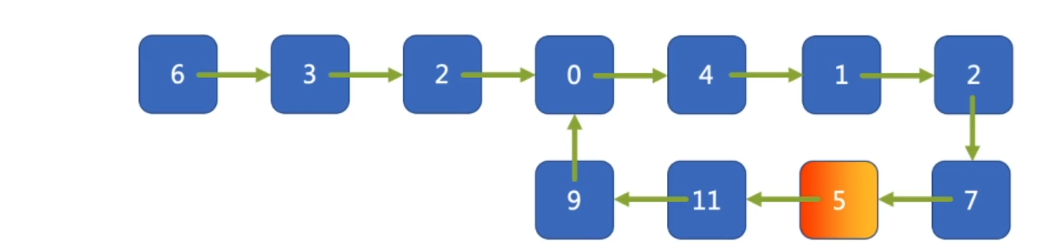
1 class Solution { 2 public: 3 bool hasCycle(ListNode *head) { 4 if( head == NULL) return false; 5 ListNode* Slow = head ,* Fast = head ; 6 7 while((Fast->next != NULL) && (Fast->next->next !=NULL)) 8 { 9 Slow = Slow->next; 10 Fast = Fast->next->next; 11 if(Slow == Fast) return true; 12 } 13 return false; 14 } 15 };
2. 翻转链表前k个节点(区间段节点) (leetcode92) (加强版:25)
---代码技巧: 虚拟头节点的使用来解决; 一旦链表的头节点有可能被改编,就可能需要用到虚拟头节点,可以有效减少边界条件的判断;
1 //默认k 小于链表长度,这里利用递推有效保存了必要的数据 2 Node *reverseKNode(Node *head, int k) { 3 if(k == 1) return head; 4 Node *tail = head->next, *np = reverseKNode(head->next, k - 1); 5 head->next = tail->next; // 这两步很锻炼思维能力 6 tail->next = head; 7 return np; 8 }
--锻炼虚拟节点技巧(leetcode 725): 优点在于可以把一些复杂的边界条件,归类为同一种操作方式,但是要理清楚哪些节点变动到哪里;
1 /** 2 * Definition for singly-linked list. 3 * struct ListNode { 4 * int val; 5 * ListNode *next; 6 * ListNode() : val(0), next(nullptr) {} 7 * ListNode(int x) : val(x), next(nullptr) {} 8 * ListNode(int x, ListNode *next) : val(x), next(next) {} 9 * }; 10 */ 11 class Solution { 12 public: 13 vector<ListNode*> splitListToParts(ListNode* head, int k) { 14 vector<ListNode*> ans; 15 16 int cnt = 0; 17 ListNode *pre = new ListNode(0, head); 18 while(head) cnt += 1, head = head->next; 19 int each = cnt / k, more = cnt % k; 20 21 22 for(int i = 0; i < k; ++i) { 23 int loop = each; 24 ans.push_back(pre->next); 25 26 head = pre; 27 while(loop--) head = head->next; 28 if(more) head = head->next, more -= 1; 29 30 if(head->next) { 31 pre->next = head->next; 32 head->next = nullptr; 33 } 34 } 35 36 return ans; 37 } 38 };
3. 复制复杂的链表: (leetcode.offer35)
核心在于如何保存链表(有些节点还未分配的情况下)之间的相互关系(map 映射,插入新生成的节点在原节点之后,然后在打开成2个节点);
下面是通过自身节点链接到新节点来实现映射;
1 /* 2 // Definition for a Node. 3 class Node { 4 public: 5 int val; 6 Node* next; 7 Node* random; 8 9 Node(int _val) { 10 val = _val; 11 next = NULL; 12 random = NULL; 13 } 14 }; 15 */ 16 class Solution { 17 public: 18 Node* copyRandomList(Node* head) { 19 if(!head) return nullptr; 20 21 unordered_map<Node*, Node*> um; 22 Node *pre = new Node(0), *temp_o = head, *temp_n = pre; 23 24 while(temp_o){ 25 Node *n = new Node(temp_o->val); 26 um[temp_o] = n; 27 temp_n->next = n; 28 temp_n = temp_n->next; 29 temp_o = temp_o->next; 30 } 31 32 temp_n = pre; 33 temp_o = head; 34 while(temp_o){ 35 temp_n->next->random = um[temp_o->random]; 36 temp_o = temp_o->next; 37 temp_n = temp_n->next; 38 } 39 return pre->next; 40 } 41 };
======================= 应用场景 =======================
(可以扩展细节)
- 操作系统内的动态内存分配;
通过链表将原始 或 释放后的空闲内存碎片串联起来,管理剩余的内存空间; - LRU缓存淘汰算法(hash链表方式实现数据串联):
如果当前缓存只能存放4 个数据,当缓存未命中时,需要将新数据存入缓存中,此时会将新数据放在链表尾部,然后将头部节点删除;
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号