强化学习之policy gradient(PPO)
强化学习分为model-based, (model-freed=>policy based, value-based),其中mode-based需要对环境进行建模,以及对神经网络后的状态和奖励建模,相对实现起来比较复杂,但是产出的样本效率高。Model-freed方法自然样本效率很低,但是简单,可以通过计算能力的提升来弱化样本效率问题。
policy gradient:Policy 可以理解为一个包含参数 θ的神经网络,该网络将观察到的变量作为模型的输入,基于概率输出对应的行动action。Trajectory τ 是由行动action和状态state的序列,简称行动状态序列。
给定神经网络参数θ 的情况下,出现行动状态序列 τ的概率:
初始状态出现的概率给定当前状态,采取某一个行动的概率;以及采取该行动之后,基于该行动以及当前状态返回下一个状态的概率。
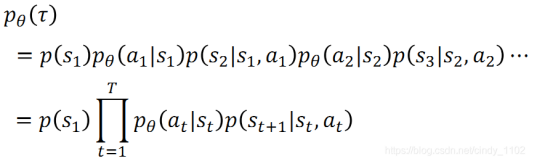
给定一个行动状态序列 τ , 我们可以得到它对应的收益reward,通过控制actor,我们可以得到不同的 τ 以及reward。由于actor采取的行动以及给定环境下出现某一个状态state是随机的,最终的目标是找到一个具有最大期望收益(即下述公式)的actor,既目标函数
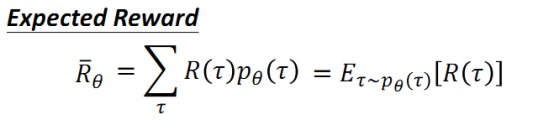
求目标函数最大值,则是最大值对应policy的神经网络参数θ ,梯度上升。
求解梯度的步骤如下,以前文所述目标函数为基础,对参数 θ 求导,其中,对概率加权的reward求和就是求reward的期望,因此有红框部分的改写,又因为训练的过程中会进行采样训练,采样个数为N,因此公式可以近似表示为N词采样得到的reward的平均。
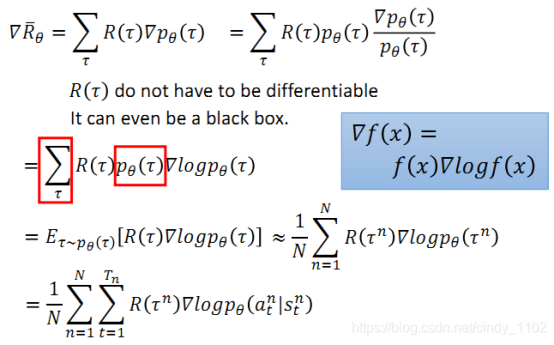
Tip1添加基准线:由于训练过程中采样是随机的,可能会出现某个行动不被采样的情况,这会导致采取该行动的概率下降;另外,由于采取的行动概率和为一,可能存在归一化之后,好的action的概率相对下降,坏的action概率相对上升的情况,因此需要引入一个基准线baseline b
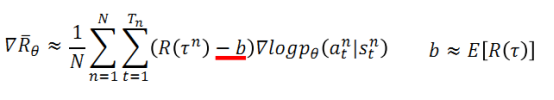
Tip 2: 进一步考虑各个时间点的累积收益计算方式
考虑到在时间t采取的行动action与t时期之前的收益reward无关,因此只需要将t时刻开始到结束的reward进行加总。并且,由于行动action对随后各时间点的reward的影响会随着时间的推移而减小,因此加入折旧因子 γ

On-policy: 学习到的agent以及和环境进行互动的agent是同一个agent
Off-policy: 学习到的agent以及和环境进行互动的agent是不同的agent
如果我们使用 π θ 来收集数据,那么参数 θ 被更新后,我们需要重新对训练数据进行采样,这样会造成巨大的时间消耗。
目标:利用 π θ ′ 来进行采样,将采集的样本拿来训练 θ, θ ′是固定的,采集的样本可以被重复使用。
Important sampling:当我们只有通过另外一个分布得到的样本时,期望值可以做出以下更改,更换分布之后,需要使用重要性权重 p(x)/q(x)来修正f(x),这样就实现了使用q分布来计算p分布期望值。需要注意的是,两个分布p,q之间的差别不能太大,否则方差会出现较大的差别。
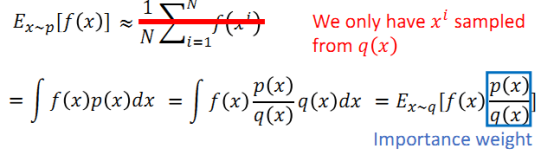
加入约束: (θ不能与θ′差别过大)
Tip: 这是一项加在行为上的约束,而不是加在参数上的约束,因此 PPO,TRPO
Advantage function:
优势函数其实就是将Q-Value“归一化”到Value baseline上,如上讨论的,这样有助于提高学习效率,同时使学习更加稳定;同时经验表明,优势函数也有助于减小方差,而方差过大导致过拟合的重要因素。
PPO
PPO在原目标函数的基础上添加了KL divergence(KL散度) 部分,用来表示两个分布之前的差别,差别越大则该值越大。那么施加在目标函数上的惩罚也就越大,因此要尽量使得两个分布之间的差距小,才能保证较大的目标函数。
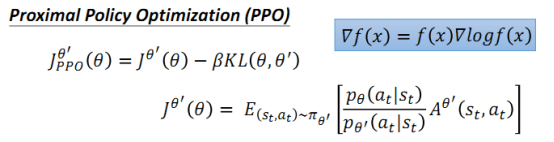
PPO算法:
1、初始化policy的参数 θ
2、在每一次迭代中,使用θ k来和环境互动,收集状态和行动并计算对应的advantage function
3、不断更新参数,找到目标函数最优值对应的参数 θ
4、在训练的过程中采用适应性的KL惩罚因子:当KL过大时,增大beta值来加大惩罚力度当KL过小时,减小beta值来降低惩罚力度


 浙公网安备 33010602011771号
浙公网安备 33010602011771号