Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD
一、 基本概念
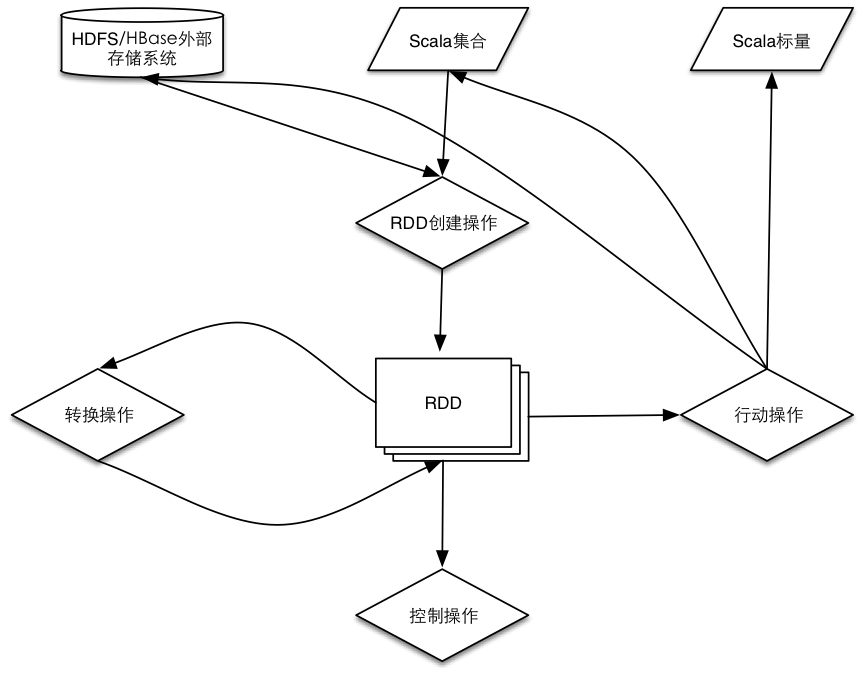
- RDD(resilient distributed datasets)弹性分布式数据集。
来自于两方面
① 内存集合和外部存储系统
② 通过转换来自于其他RDD,如map,filter等
2.创建操作(creation operation):RDD的创建由SparkContext来负责。
3.转换操作(transformation operation):将一个RDD通过一定操作转换为另一个RDD。
4.控制操作(control operation):对RDD进行持久化等。
5.行动操作(action operation):Spark为惰性计算,对RDD的行动操作都会触发Spark作业的运行。
基本分为两类
① 使操作结果变为Scala变量或者标量。
② 将RDD保存到外部文件或者数据库系统中。
6.RDD分区(partitions)
分区多少关系到对这个RDD进行并行计算的粒度,每一个RDD分区的计算操作都在一个单独的任务中被执行
7.RDD优先位置(preferredLocations)
是RDD中每个分区所存储的位置
8.RDD依赖关系(dependencies)
窄依赖:每一个父RDD的分区最多只被子RDD的一个分区使用
宽依赖:多个子RDD的分区会依赖同一个父RDD的分区
9.RDD分区计算(compute)
Spark中每个RDD的计算都是以分区为单位的,而且RDD中的compute函数都是在对迭代器进行复合,只返回相应分区数据的迭代器。
10.RDD分区函数(partitioner)
两类分区函数:HashPartitioner和RangPartitioner。
二、 创建操作
- 集合创建操作:makeRDD可以指定每个分区perferredLocations参数parallelize则没有
- 存储创建操作:Spark与Hadoop完全兼容,所以对Hadoop所支持的文件类型或者数据库类型,Spark同样支持。
- 基本转换操作
三、 转换操作
map:将RDD中T类型一对一转换为U
distinct:返回RDD不重复元素
flatMap:将元素一对多转换
reparation、coalesce:对RDD分区重新划分,reparation只是coalesce接口中shuffle为true的简易实现
randomSplit:将RDD切分
glom:将类型为T的元素转换为Array[T]
union等等
- 键值RDD转换操作
partitionBy、mapValues、flatMapValues等
- RDD依赖关系,Spark生成的RDD对象一般多于用户书写的Spark应用程序中包含的RDD,因为RDD在转换操作过程中产生临时的RDD
四、 控制操作
cache():
persist():保留着RDD的依赖关系
checkpoint(level:StorageLevel):RDD[T]切断RDD依赖关系
五、 行动操作
- 集合标量行动操作
first:返回RDD第一个元素
count:返回RDD中元素个数
reduce:对RDD的元素进行二元计算
aggregate:聚合函数
fold:是aggregate的便利借口
- 存储行动操作
saveAsHadoopFile
saveAsHadoopDataset等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号