
BUAA_OO_2022_Unit_3_Summary
一、设计构架
第一次作业
-
需求简述:
实现一个简单社交网络,构建人际网、群组,并满足其对应的查询功能。
-
代码构架:
主要构架已经被JML规格规定好了,没有什么可以发挥的空间。唯一做了设计的部分就是 UnionFind 类,用于实现并查集算法。
同时,为了代码的可扩展性,设计 UnionFind 类时运用了泛型
<T>。这一设计在第二次作业的确得到了复用的机会(最小生成树)。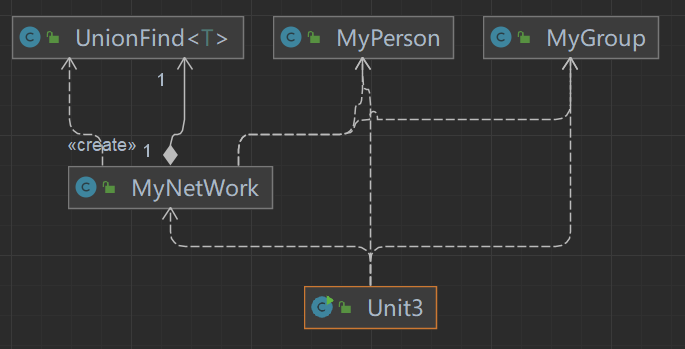
第二次作业
-
需求简述:
实现一个简单社交网络,强化关系网、群组信息的查询功能,增加简单的消息交流功能。
-
代码构架:
本次作业在上次的基础上增加了 Edge 类,用于整合每条关联边的信息,助力最小生成树Kruskal算法实现。
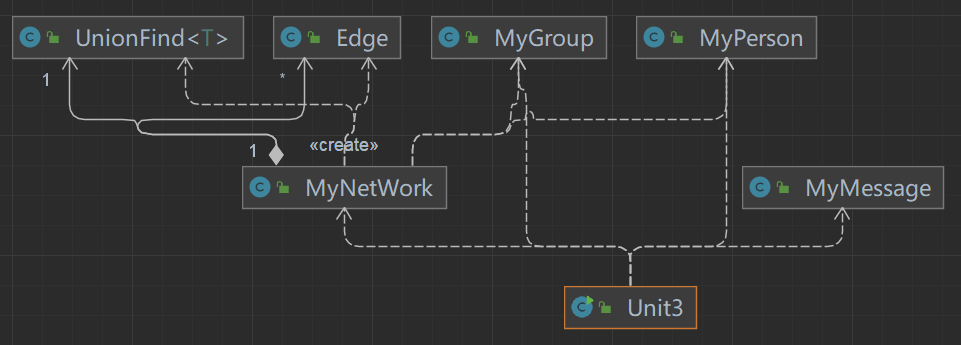
第三次作业
-
需求简述:
实现一个简单社交网络,强化消息交流功能,支持多种消息类型、定义发送对象、消息管理。
-
代码构架:
本次作业在上次的基础上增加了 Node 类,用于整合每个节点的距离信息,助力最短路径 Dijskstra 算法实现。
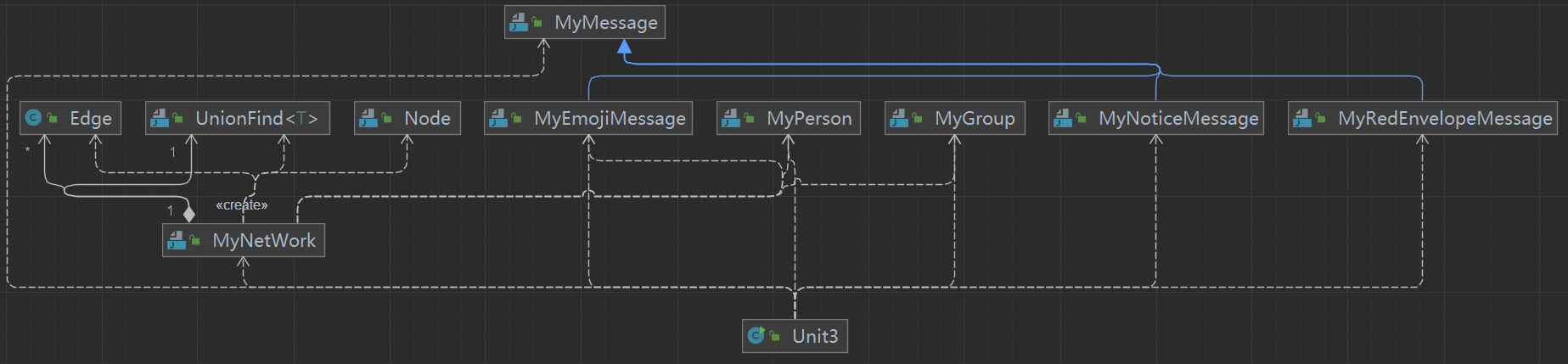
二、性能问题
在本单元的三次作业中,需要保证每一条指令的执行时间复杂度低于 O(n^2) 才能保证强测/互测都完整通过。否则,极端情况下 O(n^2) 会变为 O(n^3),导致超时。
容器选择
由于各类指令涉及到大量“通过 id 获取对应 Person、Group、Message 等”的情况,因此,绝大部分容器可选用 HashMap ,实现 O(1) 存取。
维护变量代替查询时遍历
- valueSum:关系权重之和
- ageSum:年龄之和
- ageTimeSum:年龄平方和
在 MyGroup 中维护上述3个变量,均在 atg、dfg 时修改。使得执行指令 qgvs、qgav 时时间复杂度降为 O(1)。
// MyGroup.java
public int getValueSum() {
return this.valueSum;
}
public int getAgeMean() {
// ...
return ageSum / people.size();
}
public int getAgeVar() {
// ...
int mean = getAgeMean();
return (ageTimeSum - 2 * mean * ageSum
+ people.size() * mean * mean) / people.size();
}
尽管 qgvs 的朴素实现方法复杂度仅为 O(n),但维护变量后为其他指令节省出一些时间也不是坏事。
而 qgav 如果完全按照 JML 规格描述方法实现,其复杂度最高可达 O(n) 甚至 O(n^2) [如果在 ageVar 的循环中调用遍历计算的 getAgeMean 方法],互测时针对性构造的数据就可以轻易地卡出 TLE 。
并查集及其优化
合并时,根据两棵树的 size 进行路径压缩(让 size 小的树根指向 size 大的树根),使得合并后整棵树的深度尽可能小。由此,可减轻每个节点寻找祖先节点时的时间负担。
// UnionFind.java
public void union(T a, T b) {
// ...
if (setSize.get(ra) <= setSize.get(rb)) {
roots.replace(ra, rb);
setSize.replace(rb, setSize.get(ra) + setSize.get(rb));
} else {
roots.replace(rb, ra);
setSize.replace(ra, setSize.get(ra) + setSize.get(rb));
}
}
此时,qci 的时间复杂度接近 O(1),qbs 的时间复杂度为 O(n) [采用遍历查找“根节点是自己”的节点个数的方法]。当然,维护 blockSum 变量使 qbs 降到 O(1) 也许会更好。
Kruskal算法并查集优化
将所涉关系(边)用并查集储存起来,便于快速判断当前边是否需要加入最小生成树。
// MyNetWork.java
public int queryLeastConnection(int id) throws PersonIdNotFoundException {
// ...
Collections.sort(blockEdges);
int ans = 0;
int cnt = 0;
int peopleCnt = blockPeople.size();
for (Edge x: blockEdges) {
if (ufe.findRoot(x.getPerson1()).equals(
ufe.findRoot(x.getPerson2()))) { continue; }
ufe.union(x.getPerson1(), x.getPerson2());
ans += x.getValue();
cnt++;
if (cnt >= peopleCnt - 1) { break; }
}
return ans;
}
Dijkstra算法堆优化
加入一个优先队列,从而加快了每一次处理之初“找与起点之间距离最小的节点”这一步。
记该图中有 n 个顶点和 m 条边,则
| 算法 | 时间复杂度 |
|---|---|
| 朴素Dijkstra | O(m+n^2) |
| 堆优化Dijkstra | O((m+n)log n) |
// MyNetWork.java
public int sendIndirectMessage(int id) throws MessageIdNotFoundException {
// ...
PriorityQueue<Node> queue = new PriorityQueue<>();
queue.add(new Node(p1.getId(), 0));
while (mark.contains(p2)) {
Person p = getPerson(Objects.requireNonNull(queue.poll()).getId());
for (Person x: ((MyPerson) p).getLinkage().keySet()) {
// ...更新最短路径长度
}
mark.remove(p);
}
return distance.get(p2);
}
因为第三次作业的那一周各项任务繁重,我心存侥幸心理,没有进行堆优化,结果终于在这单元的最后一次作业被强测互测都 gank 了。本还以为可以在这个单元实现一次不败之身咧(大哭
三、测试策略
形式化检查 + 随机数据测试(功能性测试)+ 针对性数据测试(承压性测试)
形式化检查
注重分析每个方法的时间复杂度,一旦出现 O(n^2) 及以上的情况,则考虑改进和维护变量,或构造针对性数据测试运行时间。
随机数据测试(功能性测试)
数据生成器中,除开头若干条指令指定为 ap、ar 或 ag 以外(保证后续指令有节点和边可操作),其他指令出现概率基本均等。在指令数量足够大时,可保证每条指令都被测试到(包括异常)。
为保证大部分指令不产生异常,数据生成器中会模拟程序的运行,即 Person、Group、Relation、Message 等状态随指令发出而同步变化。
PERSONS = {}
# {id: {"id": 111, "name": aaa, "age": 222}, id: {}}
RELATIONS = []
# [(id1, id2), ()]
GROUPS = {}
# {id: [per_id, per_id]}
MESSAGES = {}
# {
# 0: {id: (per1_id, per2_id), id: (per1_id, per2_id, emoji_id)},
# 1: {id: (per1_id, grp_id), id: (per1_id, per2_id, emoji_id)}
# }
EMOJIS = {}
# {id: 0, id: 3}
NOTICES = []
# [id1, id2]
大部分指令从正常状态出发,但也保证一定的异常概率,且覆盖各类异常情况。以 atg 为例:
def add_to_group():
# id2 (group) 组号来自目前存在的组别
grp_id = random.choice(list(GROUPS.keys())) if GROUPS else random.randint(GRP_ID_MIN, GRP_ID_MAX)
# id1 (person) 用户号来自目前存在的用户
per_id = random.choice(list(PERSONS.keys())) if PERSONS else random.randint(PER_ID_MIN, PER_ID_MAX)
rd = random.randint(1, 100)
if 1 <= rd <= 2:
# 设置为 PersonIdNotFoundException 异常
per_id = random.randint(PER_ID_MIN, PER_ID_MAX)
elif rd == 10 and grp_id in GROUPS and GROUPS[grp_id]:
# 设置为 EqualPersonIdException 异常
per_id = random.choice(GROUPS[grp_id])
if 2 <= rd <= 3:
# 设置为 GroupIdNotFoundException 异常
grp_id = random.randint(GRP_ID_MIN, GRP_ID_MAX)
if grp_id in GROUPS and per_id not in GROUPS[grp_id]:
GROUPS[grp_id].append(per_id)
print("atg %d %d" % (per_id, grp_id))
INSTR_CNT["atg"] += 1
针对性数据测试(承压性测试)
针对某一条可能因为复杂度而出错的指令,进行大量的集中测试,排除出错和 CTLE 的可能性。
|- unit3_2.py // 通用
|- unit3_2_atg.py
|- unit3_2_qbs.py
|- unit3_2_qci.py
|- unit3_2_qgav.py
|- unit3_2_qgvs.py
|- unit3_2_qlc.py
# unit3_2_qgvs.py
import random
print("ag 1")
for i in range(1115):
s = "ap {per} aaaa {age}\natg {per} 1"
age = random.randint(0, 200)
print(s.format(per=i, age=age))
for i in range(3000-1116):
s = "ar {id1} {id2}"
id1 = random.randint(0, 1114)
id2 = random.randint(0, 1114)
print(s.format(id1=id1, id2=id2))
for i in range(2000):
print("qgvs 1")
四、扩展任务
假设出现了几种不同的Person
- Advertiser:持续向外发送产品广告
- Producer:产品生产商,通过Advertiser来销售产品
- Customer:消费者,会关注广告并选择和自己偏好匹配的产品来购买 -- 所谓购买,就是直接通过Advertiser给相应Producer发一个购买消息
- Person:吃瓜群众,不发广告,不买东西,不卖东西
如此Network可以支持市场营销,并能查询某种商品的销售额和销售路径等 请讨论如何对Network扩展,给出相关接口方法,并选择3个核心业务功能的接口方法撰写JML规格(借鉴所总结的JML规格模式)
-
Advertiser、Producer、Customer 继承 Person
-
AdvertiseMessage、ProductMessage、PurchaseMessage 继承 Message
-
新增类 product,包含产品名称/id、价格、库存数目、生产商、销售路径、销售额。
-
新增核心业务功能的接口方法如下:
-
发送产品广告 advertise:
- Advertiser 向所有关联的 Person 发送 AdvertiseMessage(包含所有产品信息),可重复发送
- AdvertiseMessage 包含信息:Advertiser(消息发送者),Person(消息接收者),产品列表
-
销售产品 sendSellMessage(整合在 sendMessage 中):
- Producer 向关联的 Advertiser 发送 ProductMessage(包含产品信息)
- ProductMessage 包含信息:Producer(消息发送者),Advertiser(信息接收者),产品
- 会使接收者的产品列表更新
-
购买产品 sendPurchaseMessage(整合在 sendMessage 中):
- Customer 向关联的 Advertiser 发送 PurchaseMessage(钱可直接汇给 Producer)
- PurchaseMessage 包含信息:Customer(消息发送者),Advertiser(消息接收者),产品
- 会使发送者的钱减少,接收者的钱增多,产品信息更新。
-
// Network.java
/*@ public normal_behavior
@ requires contains(advId) && (getPerson(advId) instanceof Advertiser);
@ assignable people[*].messages;
@ ensures (\forall int i; 0 <= i && i <= people.length &&
@ people[i].isLinked(getPerson(advId)) && people[i].getId() != advId;
@ \old(people[i].messsages.length) == people[i].messsages.length - 1);
@ ensures (\forall int i; 0 <= i && i <= people.length &&
@ people[i].isLinked(getPerson(advId)) && people[i].getId() != advId;
@ (\forall int j; 0 <= j && j <= \old(people[i].messages.length);
@ (\exists int k; 0 <= k && k <= people[i].messages.length;
@ people[i].messages[j] == people[i].messages[k])));
@ ensures (\forall int i; 0 <= i && i <= people.length &&
@ people[i].isLinked(getPerson(advId)) && people[i].getId() != advId;
@ (\forall int j; 0 <= j && j <= getPerson(advId).messages.length;
@ (\exists int k; 0 <= k && k <= people[i].messages.length;
@ getPerson(advId).messages[j] == people[i].messages[k])));
@ also
@ public exceptional_behavior
@ signals (PersonIdNotFoundException e) !contains(advId);
@ signals (AdvertiserIdNotFoundException e) contains(advId) &&
@ !(getPerson(advId) instanceof Advertiser);
@*/
public void advertise(int advId) throw
PersonIdNotFoundException, AdvertiserIdNotFoundException;
/* 仅展示原规格没有的、新增的描述 */
/*@ public normal_behavior
@ requires containsMessage(id) && getMessage(id).getType() == 0 &&
@ getMessage(id).getPerson1().isLinked(getMessage(id).getPerson2()) &&
@ getMessage(id).getPerson1() != getMessage(id).getPerson2();
@ assignable products, ((Advertiser) (getMessage(id).getPerson2()).products);
@ ensures (\old(getMessage(id)) instanceof ProductMessage) ==>
@ ((\old((Advertiser) (getMessage(id).getPerson2().products.length) ==
@ \old((Advertiser) (getMessage(id).getPerson2()).products.length - 1))
@ ensures (\old(getMessage(id)) instanceof ProductMessage) ==>
@ (\forall int i; 0 <= i &&
@ i <= (\old((Advertiser) (getMessage(id).getPerson2().products.length);
@ (\exists int j; 0 <= j &&
@ j <= (\old((Advertiser) (getMessage(id).getPerson2()).products.length;
@ \old((Advertiser) (getMessage(id).getPerson2().products[i]))) ==
@ \old((Advertiser) (getMessage(id).getPerson2()).products[j])));
@ ensures (\old(getMessage(id)) instanceof ProductMessage) ==>
@ (\exists int i; 0 <= i &&
@ i <= (\old((Advertiser) (getMessage(id).getPerson2()).products.length;
@ \old((Advertiser) (getMessage(id).getPerson2()).products[i])) ==
@ ((ProductMessage) \old(getMessage(id)))).product);
@ ensures (!(\old(getMessage(id)) instanceof ProductMessage) &&
@ (\old(getMessage(id)).getPerson2() instanceof Advertiser)) ==>
@ \not_assigned((Advertiser) (getMessage(id).getPerson2()).products);
@ ensures (\old(getMessage(id)) instanceof PurchaseMessage) ==>
@ (\old(getMessage(id)).getPerson1().getMoney() ==
@ \old(getMessage(id).getPerson1().getMoney()) -
@ ((PurchaseMessage) \old(getMessage(id))).getProduct.getPrice() &&
@ \old(getMessage(id)).getPerson2().getMoney() ==
@ \old(getMessage(id).getPerson2().getMoney()) +
@ ((PurchaseMessage) \old(getMessage(id))).product.getPrice());
@ ensures (\old(getMessage(id)) instanceof PurchaseMessage) ==>
@ (\exists int i; 0 <= i && i < products.length &&
@ products[i].equals(((PurchaseMessage) \old(getMessage(id))).getProduct());
@ products[i].sales == \old(products[i].sales) + 1);
@ ensures (!(\old(getMessage(id)) instanceof PurchaseMessage)) ==>
@ (\not_assigned(products));
@ ensures (!(\old(getMessage(id)) instanceof RedEnvelopeMessage) &&
@ !(\old(getMessage(id)) instanceof PurchaseMessage)) ==>
@ (\not_assigned(people[*].money));
@*/
public void sendMessage(int id) throws
RelationNotFoundException, MessageIdNotFoundException, PersonIdNotFoundException;
五、心得体会
这单元的主角是 JML:老师课堂上的强调的是诸如前后置条件这样的规格要求,作业里(个人认为)要求的是如何将 JML 读成人话 && 关注实现方法的复杂度。感觉有一些割裂。
能明显感觉到,实验和研讨是和老师授课紧密贴合的,但作业差点火候,导致上机实验时,面对 JML 的撰写,略微有些无助(没有在作业里得到很好的训练)。但总的来说,我在课堂和实验中的收获才是最大的,只有这些部分我能真正接触、运用更丰富的 JML,而不是作业里种类和表达十分有限的 JML 规格描述。这一点和前两个单元有很大的区别——作业好像跟本单元的核心知识有些脱离了。
此外,经过了这一个单元的学习,我有一个很大的疑惑:JML 到底是给谁看的?
对于程序员来说,看代码显然比看 JML 要来的轻松;对非程序员来说,JML 好像也不是那么通俗易懂。
若是如总设计师--分设计师这样的结构,让总设计师把 JML 写好花费的功夫似乎并不亚于直接把代码全写好?(可能只是目前我接触到的 JML 是这样?)
总而言之,这单元我的收获,一是基于规格的代码设计的这样一种思想(来自课堂),二是复习了一些算法和优化方法(来自作业)吧。

