Elasticsearch7.10 -理论学习01
版权申明:
本文仅适用于学习,更多内容请访问原创作者:

微信公众号:江南一点雨
博客:https://www.javaboy.org/
下面有用到postman、kibana
一、ElasticSearch7.10的锁与版本控制
使用ES的API做 更新操作时,读取文档,对原文档更新,若是有多进程同时更新,可能出现问题。和关系型数据库一样,ES也有锁,分为
悲观锁和乐观锁。在ES中,使用的是乐观锁。版本控制也分为内部版本和外部版本。
1. 锁
-
乐观锁
读取数据时,认为别人不会修改数据,不锁定,在提交数据更新时,会去检查数据完整性。这种省去了锁的开销,提高吞吐量。 -
悲观锁
每次读取数据时,认为别人可能会修改数据,所以屏蔽一切数据一致性的操作。
2. 版本控制
-
内部版本
ES自己维护的就是内部版本,创建一个文档时,ES会给文档的版本赋值为1,每次修改一次文档,版本号就会自增1。
如果要使用内部版本,ES要求version参数的值必须和ES文档中version的值相当,才能操作成功。 -
外部版本
可以维护外部版本,在添加文档时,就可以指定版本号。
PUT book/_doc/1?version=100&version_type=external
{
"title":"3333"
}
在以后更新的时候,版本要大于已有的版本号。
- version_type=extenal 或者 version_type=external_gt表示以后更新,版本要大于已有的版本号
- version_type=exteranl_gte 表示以后更新的时候,版本要大于自己的版本号?
在Eslatic的6.7后,现在使用 if_seq_no 和 if_primary_term 两个参数来做并发控制。
创建文档,初始状态:
# GET
192.168.246.130:9200/blog
{
"_index": "blog",
"_type": "_doc",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
seq_no 不属于某一文档,它是属于整个索引的(version则是属于某一个文档的,每个文档的version互不影响)。现在更新文档时,使用
seq_no来做并发。由于seq_no是属于整个index的,所以任何文档的修改或者新增,seq_no是属于整个index的,所以任何文档的修改或者新增,seq_no都会自增。
现在就可以通过seq_no和primary_term来做乐观并发控制。
PUT book/_doc/2?if_seq_no=5&if_primary_term=1
{
"title":"555"
}
二、ElasticSearch中的倒排索引到底是什么?
倒排索引是ES中非常重要的索引结构,是从文档词项到文档ID的一个映射过程。
1.正排索引
在关系型数据库中索引就是“正排索引”。
关系型数据库中的索引如下,假设我有一个博客表:
| ID | 作者 | 标题 | 内容 |
|---|---|---|---|
| 1 | 江南一点雨 | (号外)倒排索引 | xxx |
| 2 | javaboy | Ealsticsearch倒排索引介绍 | xxx |
现在可以对这个表建立索引(正排索引)
| 索引 | 内容 |
|---|---|
| 1 | xxx |
| 2 | xxx |
| (号外) 倒排索引 | xxxxxxx |
| Elasticsearch倒排索引介绍 | xxxx |
当我们通过 id 或者标题去搜索文章时,就可以快速搜索到。
但是如果我们安装文章内容的关键字去搜索,就只能去内容中做字符匹配了。为了提高查询效率,就要考虑使用倒排索引。
2.倒排索引
倒排索引就是以内容的关键字建立索引,通过索引找到文档 id,再进而找到整个文档。
| 索引 | 文档id=1 | 文档id=2 |
|---|---|---|
| java | * | |
| Es | * | * |
| 索引 | * | |
| 江南一点雨 | * |
一般来说,倒排索引有两个部分:
- 单词词典(记录所有的文档词项,以及词项到排列表的关联关系)
- 倒排列表(记录单词与对应得关系,由一些列倒排索引项组成,倒排索引项指:文档、id、词频(TF)(词项再文档中出现得次数,评分时使用)、位置(Position,词项再文档中分词得位置)、偏移(记录词项开始和结束的位置))
当我们索引一个文档时,就回建立倒排索引,搜索时,直接根据倒排索引搜索。
三、Elasticsearch的动态映射与静态映射
映射就是Mapping,它用来定义一个文档以及文档所包含的字段如何被存储和索引。有点类似于关系型数据库中表的定义。
1.动态映射与静态映射
顾名思义,就是自动创建出来的映射。ES 根据存入的文档,自动分析出来文档中字段的类型以及存储方式,这种就是动态映射。
举例:创建一个索引book1,文档添加成功后,就会自动生成Mappings,查看索引信息:
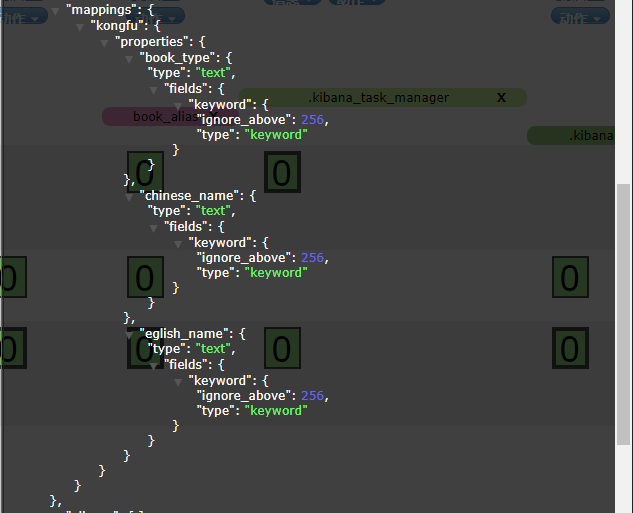
可以看到,book_type、chinese_name、english_name的类型有两个,text和keyword。默认情况下,文档中新增了字段,mapping中也会自动新增进来。
有的时候,如果希望新增字段时,能够抛出异常来提醒开发者,这个可以通过mappings中dynamic 属性来配置。
dynamic 属性有三种取值:
- true,默认即此。自动添加新字段。
- false,忽略新字段。
- strict,严格模式,发现新字段会抛出异常。
具体配置方式如下,创建索引时指定mappings(这其实就是静态映射):
#PUT url
192.168.246.130:9200/blog
{
"mappings":{
"dynamic":"strict",
"properties":{
"title":{
"type":"text"
},
"length":{
"type":"long"
}
}
}
}
然后想blog索引添加数据
#PUT url
192.168.246.130:9200/blog/_doc/1
{
"title":"Elastic的学习",
"date":"2020-12-12 23:00:00",
"length":100
}
返回信息为失败,当然,我们再blog文档中添加了一个date字段,我们设置的strict 严格模式,而该字段没有预定义,所以这个操作就报错了。
{
"error": {
"root_cause": [
{
"type": "strict_dynamic_mapping_exception",
"reason": "mapping set to strict, dynamic introduction of [date] within [_doc] is not allowed"
}
],
"type": "strict_dynamic_mapping_exception",
"reason": "mapping set to strict, dynamic introduction of [date] within [_doc] is not allowed"
},
"status": 400
}
动态映射还有一个日期检测的问题。
例如新建一个索引,然后添加一个含有日期的文档,添加成功后,remark字段会被推断是一个日期类型,如下:
{
"blog": {
"aliases": {},
"mappings": {
"properties": {
"remark": {
"type": "date"
}
}
},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "1",
"provided_name": "blog",
"creation_date": "1607786205857",
"number_of_replicas": "1",
"uuid": "xzNddGzRQ7yCB3tbgNIxzQ",
"version": {
"created": "7100099"
}
}
}
}
}
此时,remark字段就无法存储其他类型了。
#PUT
192.168.246.130:9200/blog
{
"remark":"Elasticsearch"
}
此时报错如下:
{
"error": {
"root_cause": [
{
"type": "mapper_parsing_exception",
"reason": "failed to parse field [remark] of type [date] in document with id '1'. Preview of field's value: 'Elasticsearch'"
}
],
"type": "mapper_parsing_exception",
"reason": "failed to parse field [remark] of type [date] in document with id '1'. Preview of field's value: 'Elasticsearch'",
"caused_by": {
"type": "illegal_argument_exception",
"reason": "failed to parse date field [Elasticsearch] with format [strict_date_optional_time||epoch_millis]",
"caused_by": {
"type": "date_time_parse_exception",
"reason": "Failed to parse with all enclosed parsers"
}
}
},
"status": 400
}
要解决这个问题,可以使用静态映射,即再索引定义时,将remark指定为text类型。也可以关闭日期检测。
#PUT
192.168.246.130:9200/blog
{
"mappings":{
"date_detection": false
}
}
此时日期类型就会当成文本来处理了。
2.类型推断
ES 中动态映射类型推断方式如下:
| JSON中的数据 | 自动推断出来的数据类型 |
|---|---|
| null | 没有字段被添加 |
| true/false | boolean |
| 浮点数字 | float |
| 数字 | long |
| JSON对象 | object |
| 数组 | 数组中的第一个非空值来决定 |
| string | text/keyword/date/double/long 都有可能 |
四、Elasticsearch 的四种字段类型学习
1.核心类型
1.1 字符串类型
- string:这是一个已经过期的字符串类型。再 es5 之前,用这个来描述字符串,现在,它已经被text和keyword替代了。
- text:如果一个字段是要被全文检索的,比如说博客内容、新闻内容、产品描述,那么可以使用text。用了text之后,字段内容会被解析,再生成倒排索引之前,字符串会被分词器分成一个个词项。text类型的字段不用于排序,很少用于聚合。这种字符串也被称为
analyzed字段。 - keyword:这种类型适用于结构化的字段,例如标签、email地址、手机号码等等,这种类型的字段可以用作过滤、排序、聚合等。这种字符串也称之为not-analyzed字段。
1.2 数字类型
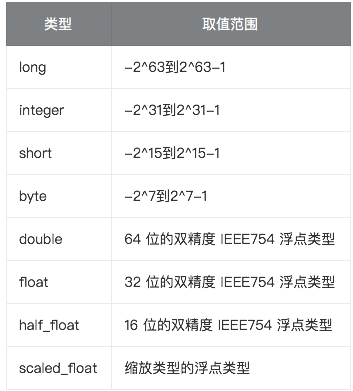
- 再满足需求的情况下,优先使用范围小的字段。字段长度越短,索引和搜索的效率越高。
- 浮点数,优先考虑使用
scaled_float
scaled_float 举例:
#PUT
192.168.246.130:9200/product
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"price":{
"type": "scaled_float",
"scaling_factor": 100
}
}
}
}
1.3 日期类型
由于JSON中没有日期类型,所以 es 中的日期类型形式就比较多样:
- 2020-12-12 或者 2020-12-12 23:58:00
- 一个从1970.1.1 零点到现在的一个秒数或者毫秒数。
es 内部将时间转为UTC,然后将时间按照millseconds-since-the-epoch的长整型来储存。
自定义日期类型:
PUT product
{
"mappings": {
"properties": {
"date":{
"type": "date"
}
}
}
}
这个能够解析出来的时间格式比较多。
PUT product/_doc/1
{
"date":"2020-11-11"
}
PUT product/_doc/2
{
"date":"2020-11-11T11:11:11Z"
}
PUT product/_doc/3
{
"date":"1604672099958"
}
上面三个文档中的日期都可以被解析,内部存储的是毫秒计时的长整型。
1.4 布尔类型(boolean)
JSON 中的 " true " 、“ false” 、 true、 false都可以
1.5 二进制类型(binary)
二进制接受的是 base64 编码的字符串,默认不存储,也不可以搜索。
1.6 范围类型
- integer_range
- float_range
- long_range
- double_range
- date_range
- ip_range
定义的时候,指定范围类型即可:
PUT product
{
"mappings": {
"properties": {
"date":{
"type": "date"
},
"price":{
"type":"float_range"
}
}
}
}
指定范围的时,可以使用 gt、gte、lt、lte 。
2. 复合类型
2.1 数组类型
es 中没有专门的数组类型。默认情况下,任何字段都可以有一个或者多个值。需要注意的是,数组中的元素必须是同一类型。
添加数组是,数组中的第一个元素决定了整个数组的类型。
2.2 对象类型
由于JSON本身具有层级关系,所以文档包含内部对象。内部对象中,还可以在包含内部对象。
PUT product/_doc/2
{
"date":"2020-11-11T11:11:11Z",
"ext_info":{
"address":"China"
}
}
2.3 嵌套类型
nested 是 object 中的一特例。
如果使用 object 类型,假如有如下文档:
{
"user":[
{
"first":"Zhang",
"last":"san"
},
{
"first":"Li",
"last":"si"
}
]
}
由于Lucene 没有内部对象的概念,所以 es 会将对象层次扁平化,将一个对象转为字段名和值构成的简单列表。即上面的文档,最终存储形式如下:
{
"user.first":["Zhang","Li"],
"user.last":["san","si"]
}
扁平化之后,用户名之间的关系没了。这样会导致搜索 Zhang si 这个人,会搜索到。
此时可以 nested 类型将数组中每个对象作为独立隐藏文档来索引,这样每一个嵌套对象都可以独立被索引。这个时底层的存储形式。
{
{
"user.first":"Zhang",
"user.last":"san"
},{
"user.first":"Li",
"user.last":"si"
}
}
优点
文档存储在一起,读取性能高
缺点
更新父或者子文档时需要更新这个文档。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号