ElasticSearch7.10的分词器
ElasticSearch7.10的分词器
现在有很多公司都在使用ElasticSearch,其中用来查询分析只要是词条,他的分词器分为:
| 分词器 | 用途 |
|---|---|
| Standard Analyzer | 标准分词器,适用于英语等 |
| Simple Analyzer | 简单分词器,基于非字母字符进行分词,单词会被转为小写字母 |
| Whitespace Analyzer | 空格分词器,安装空格进行切分 |
| Stop Analyzer | 和简单分词器类似,但是增加了停用词的功能 |
| Keyword Analyzer | 关键词分词器,输入文本等于输出文本 |
| Pattern Analyzer | 利用正则表达式对文本进行切分,支持停用词 |
| Language Analyzer | 针对特定语言的分词器 |
| Fingerprint Analyzer | 指纹分析分词器,通过创建标记进行重复检测 |
1、中文分词器
在中国,应该式中文分词器用的比较多,elasticsearch-analysis-ik,这是一个es的第三方插件,在GitHub的地址是:
https://github.com/medcl/elasticsearch-analysis-ik
下载下来,在plugins下创建一个ik,放在里面,重启elasticsearch,看到加载了插件即可。
1.1 ElasticSearch和关系型数据库的比较
| 关系型数据库 | ElasticSearch |
|---|---|
| 数据库 | 索引 |
| 表 | 类型 |
| 行 | 文档 |
| 列 | 字段 |
| 表结构 | 映射(Mapping) |
| SQL | DSL(Domain Specific Language) |
| select * from t_xx | curl -XGET 'http://ip:port/' |
| update t_xx set xx = xxx | curl -XPUT 'http://ip:port' |
| delete t_xx | curl -XDELETE 'http://ip:port/' |
| 索引 | 全文索引 |
1.2 IK Analysis for Elasticsearch
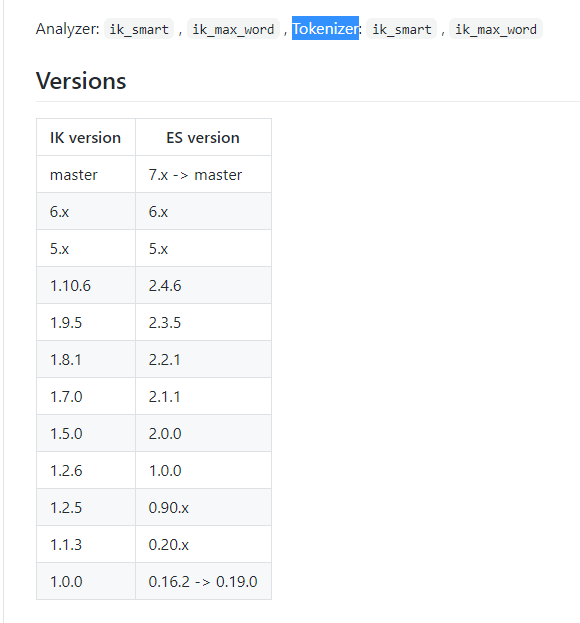
文中介绍了分词器的种类:ik_smart,ik_max_word。
1.2.1安装方式
- 下载编译
下在预编译的包,https://github.com/medcl/elasticsearch-analysis-ik/releases,在es的plugins目录下
创建ik目录,把它解压到ik下。
[~#root]cd your-es-root/plugins/ && mkdir ik
- 命令行安装
使用elasticsearch-plugin命令去安装,进入目录
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.10.0/elasticsearch-analysis-ik-7.10.0.zip
把v后面的版本号改成你选择的版本号。
1.2.2 测试用例
1.创建索引
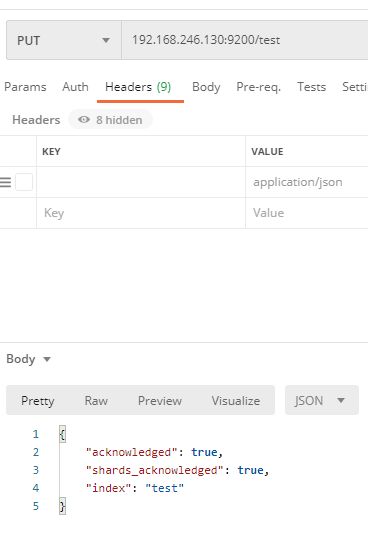
- 1.1 由于ElasticSearch支持Http Restful API、Native Java API,所以创建索引,可以用postman直接访问。
192.168.246.130:9200/test
- 1.2 可以命令行创建
curl -XPUT http://192.168.246.130:9200/test
2.创建映射
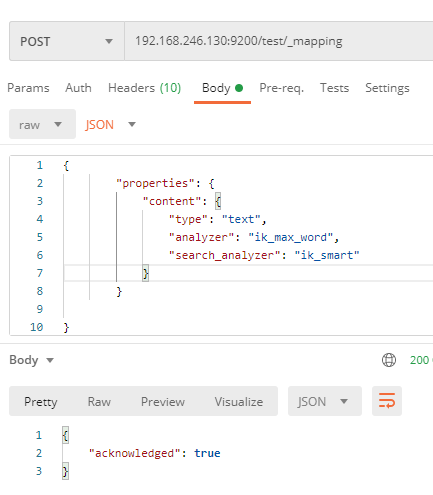
- 2.1 postman使用post请求,在请求头中设置,
Content-Type:application/json
192.168.246.130:9200/test/_mapping
# 参数
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
- 2.2 命令行模式
curl -XPOST http://localhost:9200/index/_mapping -H 'Content-Type:application/json' -d'
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}'
3.索引一些文档
curl -XPOST http://localhost:9200/index/_create/1 -H 'Content-Type:application/json' -d'
{"content":"美国留给伊拉克的是个烂摊子吗"}
'
curl -XPOST http://localhost:9200/index/_create/2 -H 'Content-Type:application/json' -d'
{"content":"公安部:各地校车将享最高路权"}
'
curl -XPOST http://localhost:9200/index/_create/3 -H 'Content-Type:application/json' -d'
{"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"}
'
curl -XPOST http://localhost:9200/index/_create/4 -H 'Content-Type:application/json' -d'
{"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"}
'
4.高亮查询
- 4.1 命令行
curl -XPOST http://localhost:9200/index/_search -H 'Content-Type:application/json' -d'
{
"query" : { "match" : { "content" : "中国" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}
'
- 4.2 postman查询
192.168.246.130:9200/test/_search
# 参数,请求头参照命令行
1.2.3 扩展词配置
这些返回结果,对于ik_smart和ik_max_word来说,ik_max_word更细化。但对于中文,有些文字我们不想让它
分开,这时我们可以在配置目录下增加扩展词ext_dict。
两种方式:
在ik目录下的config目录下,IkAnalyzer.cfg.xml可以配置扩展词,及远程扩展字典。也可以直接在config下创建ext_dic。
- 直接创建
[~#root]cd your-es-root/plugins/ik/confg/
[~#root]vim ext_dict
九月的山沉
- 配置文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext_dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">custom/ext_stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">location</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">http://xxx.com/xxx.dic</entry>
</properties>
其中ext_dic,我写入:
九月的山沉
1.2.4 分词器使用
重新启动Elasticsearch

在postman上
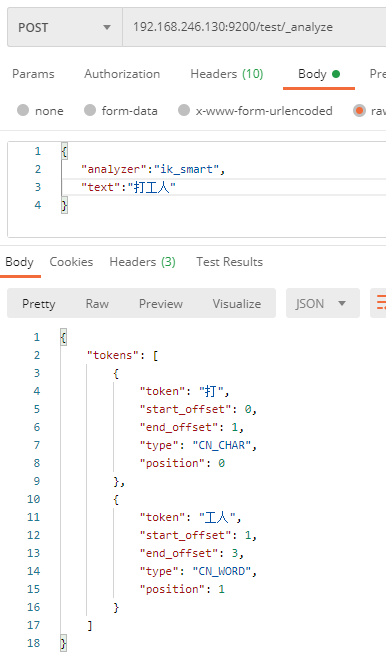
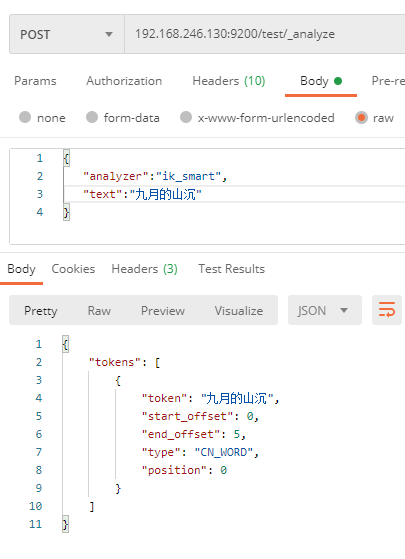
192.168.246.130:9200/test/_analyze
# 参数
{
"analyzer":"ik_smart",
"text":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
}
查看返回结果,与扩展词做对比。
没有加入扩展词
加入扩展词
弯弯月亮,只为美好的自己。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号