
一 前言
很少接触HashTable晚上回来简单看了看,然后做一些增加和移除的操作,就想和List 与 Dictionary比较下存数据与取数据的差距,然后便有了如下的一此测试,
当然我测的方法可能不是很科学,但至少是我现在觉得比较靠谱的方法。如果朋友们有什么好的方法,欢迎提出大家来交流下。
先来简单介绍这三个容器的各自特点吧
1 hashtable 散列表(也叫哈希表),是根据关键字(Key value)而直接访问在内存存储位置的数据结构。
2 List<T> 是针对特定类型、任意长度的一个泛型集合,实质其内部是一个数组。
3 Dictionary<TKey, TValue> 泛型类提供了从一组键到一组值的映射。字典中的每个添加项都由一个值及其相关联的键组成。通过键来检索值,实质其内部也是散列表
有了简单的介绍后下面开始来比较了
二 效率比较
2.1 插入效率
先以10万条为基础,然后增加到100万
细心的园友发现我代码存在不合理之处,在Hashtable 与Dictionary中都有发生装箱操作,所以重定定义了两个object类型参数以避免装箱
结果也有区别了

Hashtable hashtable = new Hashtable(); List<string> list = new List<string>(); Dictionary<string, object> dic = new Dictionary<string, object>();
object value1 =123;
object value2 =456; var watchH = new Stopwatch(); var watchL = new Stopwatch(); var watchD = new Stopwatch(); //Hashtable watchH.Start(); for (int i = 0; i < 100000; i++) { hashtable.Add( i.ToString(), value1); } Console.WriteLine(watchH.Elapsed); //List watchL.Start(); for (int i = 0; i < 100000; i++) { list.Add(i.ToString()); } Console.WriteLine(watchL.Elapsed); //Dictionary watchD.Start(); for (int i = 0; i < 100000; i++) { dic.Add(i.ToString(), value2); } Console.WriteLine(watchD.Elapsed); Console.WriteLine("插入结束!");
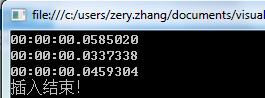
10万结果如下测试3次以上
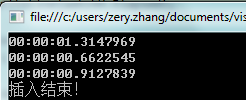
100万结果如下测试3次以上
2.2 结论
1 不管是10万还是100万List集合所用的时间总是最少的,我想这与其内部是数组有关,都是按顺序插入而且大小是一至的,在空间上应该占用是最小的
2 Hashtable在10万次时,所花时间多于List,比List时间多我想是因为要把Key做一个散列值计算 在这一步会花掉部分时间,空间上占用应该要比List大得多,因为散列值是无序的。
3 Dictionary 这个结果让我不太明白了,内部同样也是Hashtable也要做散列值计算,为什么要比原生的hashtable花的时间更少呢?
求助朋友们~~!!
2.3 查找效率
同样以10万次和100万次做测试 插入的代码就不重复贴与上面一致
var watchH = new Stopwatch(); var watchL = new Stopwatch(); var watchD = new Stopwatch(); //HashTable watchH.Start(); object valueH = hashtable["90000"]; Console.WriteLine(watchH.Elapsed); //List watchL.Start(); string valueL = list.Find(o => o == "90000"); Console.WriteLine(watchL.Elapsed); //Dictionary watchD.Start(); object valurd = dic["90000"]; Console.WriteLine(watchD.Elapsed); Console.WriteLine("查找完毕!"); Console.Read();
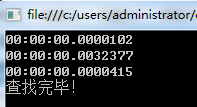
在10万次的情况下
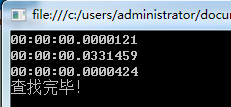
在100万次的情况下
2.4 结论
1 Hashtable 不认在10万次还是100万次的情况下在查找时速度都是惊人的快为什么会这么快呢,我用超精减的话说,hashtable在存数据时会把key通过散列函数计算出地址然后存入,那在取值同样把key通过散列函数计算出地址,然后直接取值,所以速度很快
2 Dictionary 因其内部是Hashtable所以速度也很快,但总是要比Hashtable慢一点,我猜这与Dictionary把Hashtable当做自己的数据容器时应该有相应的代码来操作,可能是这些代码花掉了时间,当然这个只是我的猜测 至于真正原因 我 再一次求助朋友们~~!!
3 List 这个就简单了要想在数组中查找一条记录唯一的办法就是遍历数组,而且我试过把查找的对象换成"0"与"999999"两者的时间差距非常大,也更足以证明了List的查找是用遍历的方式处理的
三 总结
通过对三种数据结构做插入与查找的对比,还是有亮点的,至少让我知道原来Hashtable是这么的强悍,对于需要从大量唯一数据中查找唯一值时Hashtable是很值得考虑的,
但是hashtable是用空间来换取时间的,花的时间少了点用的空间就必然大了,而List则用时间来换取空间的,总是三种数据结构各自己有各自存在的优点,我们应该在合理的情况下合理的使用这三种结构,本文也只是单一的从效率上测试而以。
另外 文章我还有两个疑问希望园子里的朋友们能指点一二 谢谢~
1 Dictionary 内部同样也是Hashtable也要做散列值计算,为什么在插入数据时要比原生的hashtable要快呢?
2 Dictionary 内部实质也是hashtable为什么在查找时总是要比原生的Hashtable要慢呢?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号