Selenium2+python自动化
一、打开网站
1.第一步:从selenium里面导入webdriver模块
2.打开Firefox浏览器(Ie和Chrome对应下面的)
3.打开百度网址
二、设置休眠
1.由于打开百度网址后,页面加载需要几秒钟,所以最好等到页面加载完成后再继续下一步操作
2.导入time模块,time模块是Python自带的,所以无需下载
3.设置等待时间,单位是秒(s),时间值可以是小数也可以是整数
三、页面刷新
1.有时候页面操作后,数据可能没及时同步,需要重新刷新
2.这里可以模拟刷新页面操作,相当于浏览器输入框后面的刷新按钮
四、前进和后退
1.当在一个浏览器打开两个页面后,想返回上一页面,相当于浏览器左上角的左箭头按钮
2.返回到上一页面后,也可以切换到下一页,相当于浏览器左上角的右箭头按钮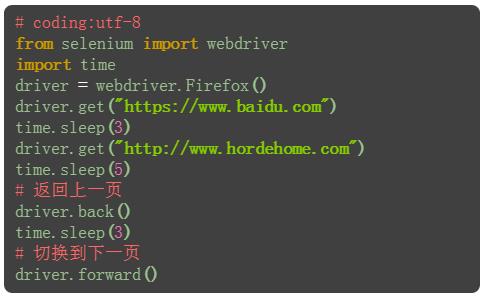
五、设置窗口大小
1.可以设置浏览器窗口大小,如设置窗口大小为手机分辨率540*960
2.也可以最大化窗口
六、截屏
1.打开网站之后,也可以对屏幕截屏
2.截屏后设置制定的保存路径+文件名称+后缀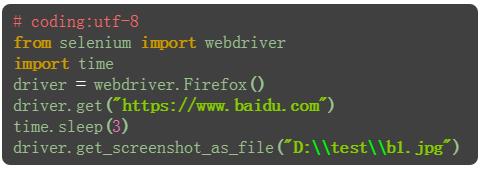
七、退出
1.退出有两种方式,一种是close;另外一种是quit
2.close用于关闭当前窗口,当打开的窗口较多时,就可以用close关闭部分窗口
3.quit用于结束进程,关闭所有的窗口
4.最后结束测试,要用quit。quit可以回收c盘的临时文件
八、基本的元素定位
selenium的webdriver提供了八种基本的元素定位方法,前面六种是通过元素的属性来直接定位的,后面的xpath和css定位更加灵活,需要重点掌握其中一个。
1.通过id定位:find_element_by_id()
2.通过name定位:find_element_by_name()
3.通过class定位:find_element_by_class_name()
4.通过tag定位:find_element_by_tag_name()
5.通过link定位:find_element_by_link_text()
6.通过partial_link定位:find_element_by_partial_link_text()
7.通过xpath定位:find_element_by_xpath()
8.通过css定位:find_element_by_css_selector()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号