黏包问题
黏包
首先看下Socket传输数据的原理:
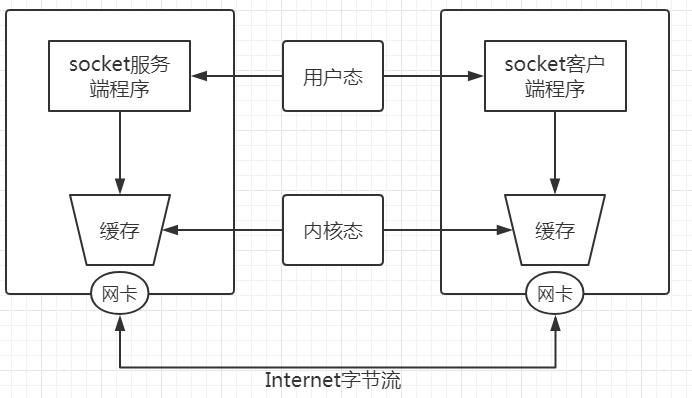
两端的socket程序要发送数据是先将数据发送到本地的缓存当中,然后发起系统调用,让系统控制网卡,将数据发送出去。接收端收到数据后,也是先放到本地的缓存队列中,socket程序都是从缓存队列中取数据。
对TCP协议来讲,数据没有接收干净并不会丢弃,而是放在缓存队列中,先进入队列的数据会先被读取。TCP是可靠协议,如果缓存溢出,接收方没有收到数据就不会发送ACK确认信息,TCP协议会过段时间后再次发送数据,直到对方确认接收或多次发送无果后,认为对方已断开连接。
如果是UDP协议的话,缓存队列溢出,未发送成功的数据会被丢弃。
send(字节流)和recv(1024)以及sendall()
recv()是指从缓存里一次最大拿出1024个字节的数据。
send()的字节流是先放入己端缓存,然后由协议控制将缓存内容发往对端,如果待发送的字节流大于缓存剩余空间,那么数据丢失;用sendall就会循环调用send,数据不会丢失。
黏包现象
- 1、当发送端连续多次
send()很少的数据量时,接收端一次recv()就会接收到全部的数据,无法区分多个数据。
# 客户端
import socket
with socket.socket(socket.AF_INET,socket.SOCK_STREAM) as s:
s.connect(('127.0.0.1',8080))
# 多次send()
s.send(b'123')
s.send(b'456')
s.send(b'7890')
# 服务端
import socket
with socket.socket(socket.AF_INET,socket.SOCK_STREAM) as s:
s.bind(('127.0.0.1',8080))
s.listen(3)
conn,addr = s.accept()
# 一次recv()
data = conn.recv(1024)
print(data.decode('utf-8'))
conn.close()
1234567890
-
2、根据上篇基于TCP协议开发的远程执行命令的程序,当发送方
send()发送的数据大于接收方recv()接收的数据时,就会出现数据接收不干净,第二次再接收时,接收的是上一次残留的数据。也就是说,基于TCP的套接字发送端向接收端上传数据时,数据是按照一段一段的字节流发送的,接收方并不知道该数据的字节流起始和结尾。
黏包原因
所谓黏包问题还是因为接收方不知道数据之间的界限,不知道一次性提取多少字节的数据而造成的。
现象1是由于TCP协议本身设计造成的,TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一个TCP段。若连续几次需要send()的数据很少,通常TCP会根据优化算法(Nagle算法)把数据合成一个TCP段后一次发送出去,这样接收方就收到了黏包数据。
只有TCP会发生黏包,UDP不会出现黏包的原因:
- 1、TCP(Transport Control Protocol,传输控控制协议)是面向连接的,面向流的,提供高可靠性服务。收发两端都要有成对的Socket,因此,发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化算法(Nagle算法),将多次时间间隔短且数据量小的数据,合并成一个大的数据段,然后进行封包。这样,接收端就无法分辨数据了,必须提供科学的拆包机制。即面向流的通信是无消息保护边界的。
- 2、UDP(User Datagram Protocol,用户数据报协议)是无连接的,面向消息的,提供高效率服务。不会使用块的合并优化算法,由于UDP支持的是一对多的模式,所以接收端的skbuff(套接字缓冲区)采用了链式结构来记录每一个到达的UDP包,在每个UDP包中就有了消息头(消息来源地址、端口等信息),这样,对于接收端来说,就容易进行区分处理了。即面向消息的通信是有消息保护边界的。
拆包发生的情况
当发送端缓冲区的长度大于网卡的MTU时,TCP会将这次发送的数据拆成几个数据包发送出去。
黏包的解决
黏包的问题根源在于,接收端不知道发送端将要传送的字节流的长度,所以解决黏包的方法就是围绕如何让发送端在发送数据前,把自己将要发送的字节流大小让接受端知晓,然后接收端再通过一个循环接收完所有的数据。
解决黏包问题的粗糙方法
使用len()函数获得要发送字节流的大小。
远程执行命令的服务端:
import socket
import subprocess
with socket.socket(socket.AF_INET,socket.SOCK_STREAM) as s:
s.bind(('127.0.0.1',8080))
s.listen(5)
# 链接循环
while 1:
conn,addr = s.accept()
print(f'{addr} 已连接!')
# 通信循环
while 1:
try:
cmd = conn.recv(1024)
if not cmd:
break
popen = subprocess.Popen(cmd.decode('utf-8'),shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
res = popen.stdout.read() + popen.stderr.read()
# 先发送数据长度
conn.send(str(len(res)).encode('utf-8'))
# 待对方确认收到
back_msg = conn.recv(1024).decode('utf-8')
# 再发送实际数据
if back_msg == 'is_read':
conn.send(res)
except Exception:
break
conn.close()
客户端:
import socket
with socket.socket(socket.AF_INET,socket.SOCK_STREAM) as s:
s.connect(('127.0.0.1',8080))
while 1:
cmd = input('>>> ')
if not cmd:
continue
s.send(cmd.encode("utf-8"))
# 先接收返回数据的长度
data_size = s.recv(1024)
print(data_size.decode('utf-8')) # 查看要接收的数据长度
# 确认接收到长度数据
s.send('is_read'.encode('utf-8'))
# 再根据长度使用一个循环接收实际数据,当剩余数据大于1024则每次接收1024,当小于1024则接收剩下全部
recv_size = 0
res = b''
while recv_size < data_size:
if int(data_size.decode('utf-8')) - recv_size >= 1024:
data = s.recv(1024)
else:
data = s.recv(int(data_size.decode('utf-8')) - recv_size)
recv_siez += len(data)
res += data
print(res.decode('utf-8'))
1、为了避免len()的结果和实际数据黏在一起,所以在中间加了一道确认信息“is_read”。
2、这里使用一个循环每次接收1024个字节,而不是直接按照已获得的数据总长度来一次性接收,是为了防止发送的数据量大于接收端的缓存队列,接收端每次recv的值即便设置的足够大,但每次取值也不会超过缓存队列的总大小,所以使用一个循环,每次接收少量数据,直到全部取完。
3、每次判断剩余数据量是否足够1024字节。
说它粗糙是因为在发送实际的数据前会先双方会先进行一次交互,这种方式会放大网络延迟带来的性能损耗。如果我们每次发送的报头长度固定,接收方第一次仅需接收指定长度的字节,就能减少这个交互。
改进后的解决方法
使用struct模块,它能将一个Python类型转成固定长度的bytes。比如能将一个int类型转为4个字节的bytes,这样接收方每次固定接收4个字节即可。
改进后的服务端:
import socket
import struct
import subprocess
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.bind(('127.0.0.1', 8080))
s.listen(5)
while 1:
conn, addr = s.accept()
print(addr)
while 1:
try:
cmd = conn.recv(1024)
if not cmd:
break
res = subprocess.Popen(cmd.decode('utf-8'), shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
back_data = res.stdout.read() + res.stderr.read()
# 使用struct模块将int转成4字节的bytes
back_data_size = struct.pack('i', len(back_data))
# 先发送4个字节的报头
conn.send(back_data_size)
# 再发送实际数据
conn.send(back_data)
except Exception:
break
conn.close()
print(f'{addr}已断开连接!')
改进后的客户端:
import socket
import struct
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.connect(('127.0.0.1', 8080))
while 1:
cmd = input('>>>: ').strip()
if not cmd:
continue
s.send(cmd.encode('utf-8'))
# 先接收4个字节的报头
data_size_bytes = s.recv(4)
data_size = struct.unpack('i', data_size_bytes)[0]
# 再循环接收实际数据
recv_size = 0
data = b''
while recv_size < data_size:
if data_size - recv_size <= 1024:
res = s.recv(1024)
else:
res = s.recv(data_size - recv_size)
recv_size += len(res)
data += res
print(data.decode('gbk'))
上述我们是将要发送的数据长度优先发送对方,更近一步,我们要进行文件传输,则可以将文件的其他描述信息,比如文件名、文件大小、hash值等都传给对方。
文件传输程序
先将文件的描述信息构造成一个字典,将其通过json模块序列化,先发送字典的长度,接收方根据长度接收字典对其反序列化,拿到文件大小,根据文件大小再接收实际的数据。
ftp服务端:
# 使用TCP协议,客户端连接就返回目录下的文件名,根据文件名发送文件
import socket
import json
import struct
import os
import hashlib
ip_port = ('127.0.0.1',8080)
# 构建当前目录中文件的字典
file_dic = {}
def get_file_dic():
# 获取当前路径
dir_path = os.getcwd()
file_list = os.listdir(dir_path)
for file in file_list:
if os.path.isfile()
# 获取文件大小
file_size = os.path.getsize(file)
# 获取文件hash值
m = hashlib.md5()
with open(file,'rb') as f:
for line in f:
m.update(line)
file_md5 = m.hexdigest()
# 添加到file_dic
file_dic[file] = [file_size,file_md5]
get_file_dic()
# 建立链接,传输文件
with socket.socket(socket.AF_INET,socket.SOCK_STREAM) as s:
s.bind(ip_port)
s.listen(5)
while 1:
print('服务端已启动。。。')
conn,addr = s.accept()
print(f'来自{addr}的连接!')
while 1:
try:
# 发送文件字典的大小
file_dic_json = json.dumps(file_dic)
file_dic_json_size = len(file_dic_json)
file_dic_json_size_bytes = struct.pack('i',file_dic_json_size)
conn.send(file_dic_json_size_bytes)
# 发送文件字典
conn.send(file_dic_json.encode('utf-8'))
# 接收对方要下载的文件名
file = conn.recv(1024)
if not file:
break
with open(file,'rb') as f:
for line in f:
conn.send(line)
except Exception:
break
conn.close()
print(f'客户端{addr}已断开连接!')
ftp客户端:
import socket
import struct
import json
ftp_server = ('127.0.0.1',8080)
with socket.socket(socket.AF_INET,socket.SOCK_STREAM) as s:
s.connect(ftp_server)
# 接收文件字典大小
file_dic_size_bytes = s.recv(4)
file_dic_size = struct.unpack('i',file_dic_size_bytes)[0]
# 根据大小接收实际的字典
file_dic_json = s.recv(file_dic_size)
file_dic = json.loads(file_dic_json)
while 1:
print(file_dic)
file = input('输入要下载的文件名:').strip()
if file not in file_dic:
print('文件不存在!')
continue
s.send(file.encode('utf-8'))
# 接收实际的文件
recv_file = 0
with open(file, 'ab') as f:
while recv_file < file_dic[file][0]:
if file_dic[file][0] - recv_file > 1024:
data = s.recv(1024)
else:
data = s.recv(file_dic[file][0] - recv_file)
recv_file += len(data)
f.write(data)
f.flush()
