第四章 语言模型与中文分词
1. 马尔可夫 Markov chain / hidden Markov model
Markov Property: 现在的状态只与前一时刻有关

2. Tri-Gram Model
1) 上一讲的 Bag-of-Words 属于 Uni-Gram : 代表每一个词之间没有关联关系
2)Bi-Gram 代表每一个两元组之间存在关系:
例如: 我爱北京天安门(ABCD)每一个词出现概率都与前面有关 ‘天安门’与‘北京’有关
3)Tri-Gram Model:
求一个词概率时,将考虑前两个词 P(‘北京’) = P(北京|我,爱)



4) c(u,v) 代表一个二元组出现次数,c(u,v,w) 代表三元组出现次数
* 代表无/任意词 ; c(*,*)代表任意二元组出现次数
3. N-Gram Model
根据马尔可夫特性,根据统计频率,来计算概率

4. Language Model Evaluation
perplexity: 可以更改不同Model ,Uni-gram,Bi,Tri 分别计算perplexity,看哪个最好
perplexity越小越好
5. Entropy
1)

2) Cross-Entropy


3) Dara Compression
2)中的交叉熵为 Hp(q) = q(x)* log (1/p(x))这里例子里假设所有的 q(x)都是均等的,所以直接 -1/7
这里bi-gram只需要6个bits,unigram则需要11个


6. interpolation
1) 结合不同的 n-gram 比如 2-gram , 3-gram , 和Uni-gram


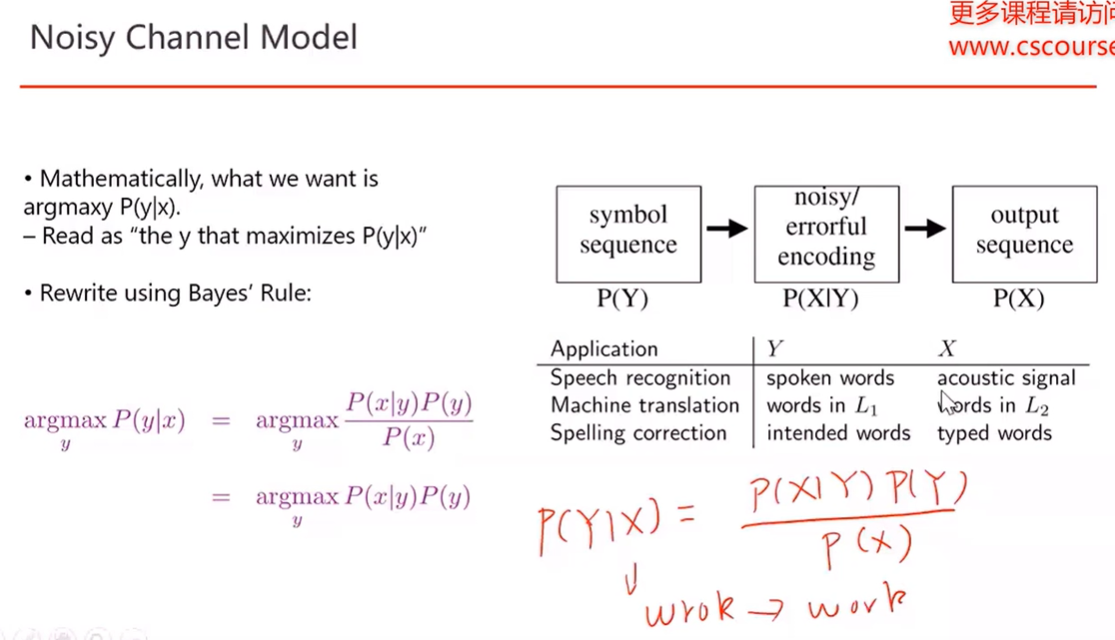
7. Bayesian Model
1) 贝叶斯应用:语音识别 给定音频X,对应的单词Y

2) 朴素贝叶斯模型,进行垃圾邮件分类
1.假定邮件E中每一个单词都是独立的,即可使用累乘
2.每一个单词的概率计算 = c(x|y=1) / c(y=1) ;即label为垃圾邮件中,某单词出现次数 / 垃圾邮件总数
3. 累乘时,若有单词在之前的样本中出现次数为0,就假设出现一次,即该P设为 1/V V为样本总量

3) Bayesian Probability model 检测 Spelling Correction






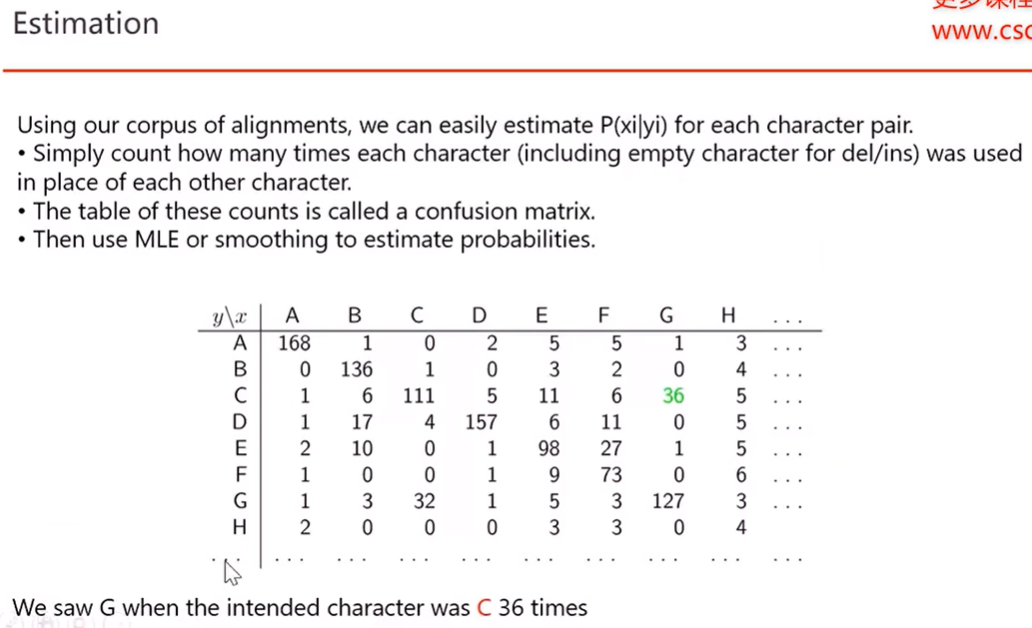
P(C|W)正比于 P(W|C)与 P(C)
P(C)Language Model可通过词频计算获得
P(W|C)Error Model 可通过以下计算
单词出错有一下几种:
1) Substitution: 某个字母发生替换 n*(26-1)种情况 P(W|C) = 1/n*25
2) deletion:删了某一个 n P(W|C) = 1/ n
3)insertion: 插入某一个 (n+1)*26 P(W|C) = 1/(n+1)*26
4)swap:调换位置 n! P(W|C) = 1/ n!
candidate model:
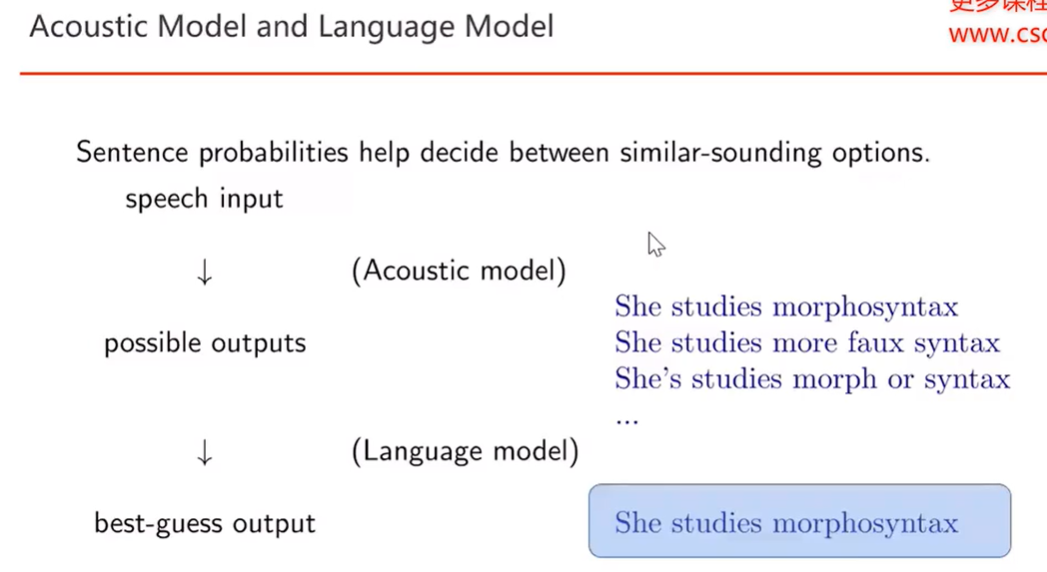
4) Acoustic Model (声学模型)and Language Model
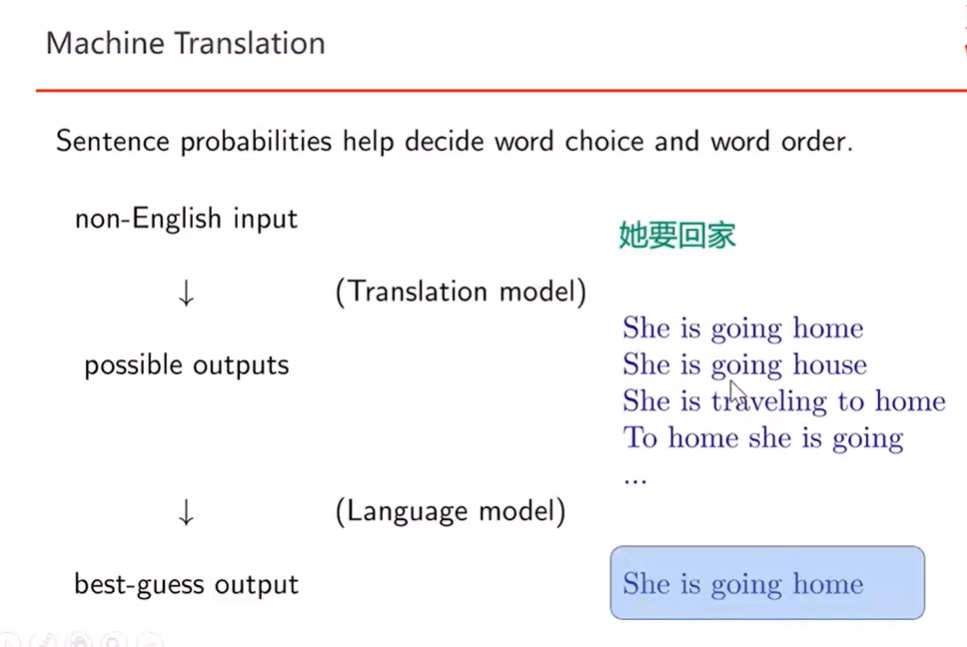
5) Machine Translation
8. Chinese Word Segmentation
有时英文连在一起,也需要分词。

中文一个拼音可对应多个汉语词组 qingtian,英文一个音标所对应单词少 television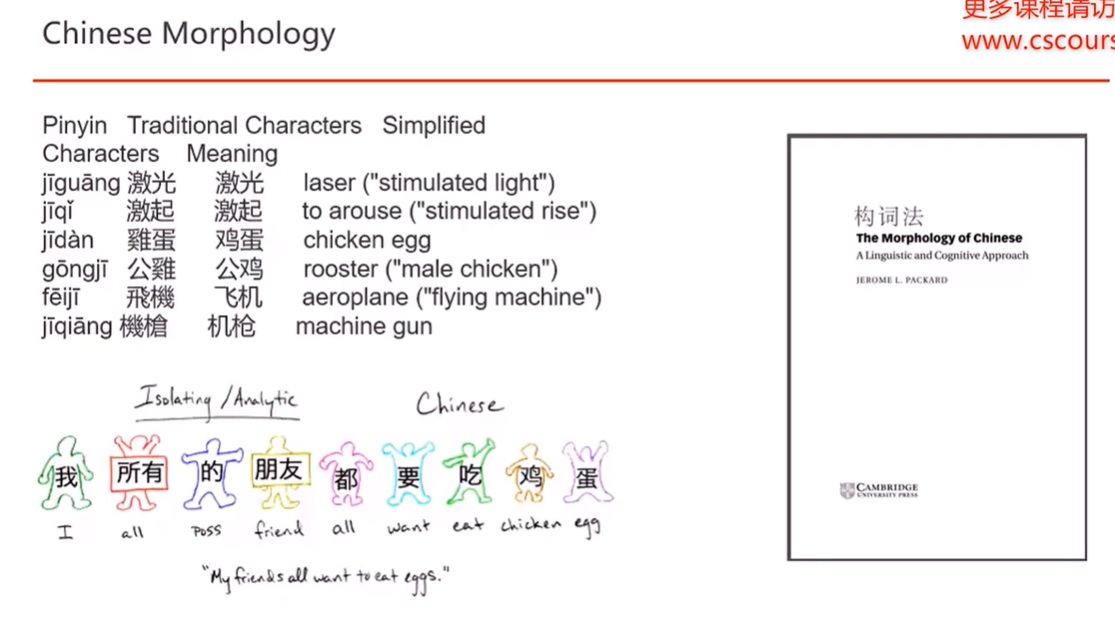

1) Maximum Matching
尽可能取最长的词 ,词典中找最大匹配
Bi-direction Matching 从左到右 和 从右到左 同时匹配最长,取出现概率最大的词语分法

2) N-gram
例子 : Bi-gram 看几种分发哪种概率更大

3) Optimal Path
动态规划
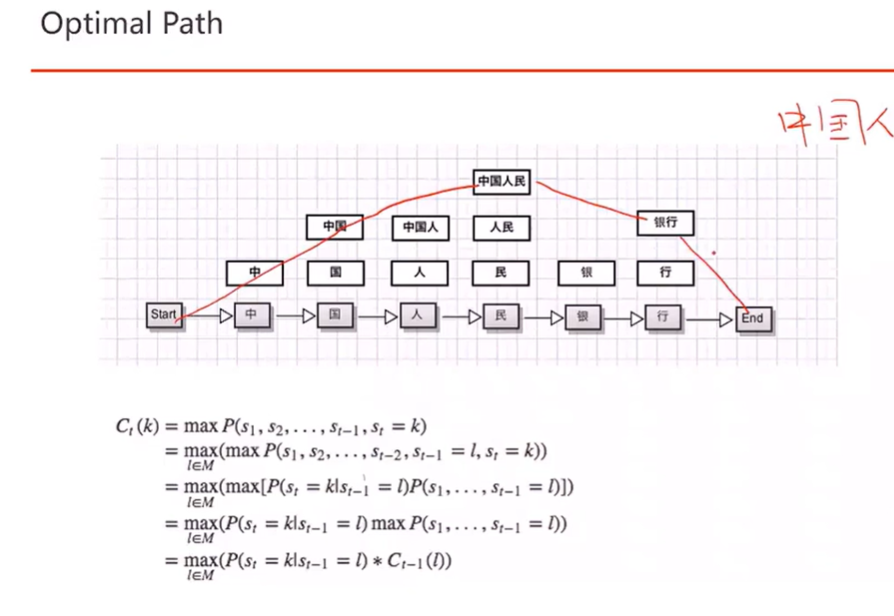
4) 分词库 jieba 

 浙公网安备 33010602011771号
浙公网安备 33010602011771号