COMP9313 week7b Spark SQL
https://www.cse.unsw.edu.au/~cs9313/20T2/slides/L6.pdf
Table recall:
1. rows: entity
2. columns: attributes
Spark SQL:
1. Spark SQL is not about sql, Aims to Create and Run Spark programs faster
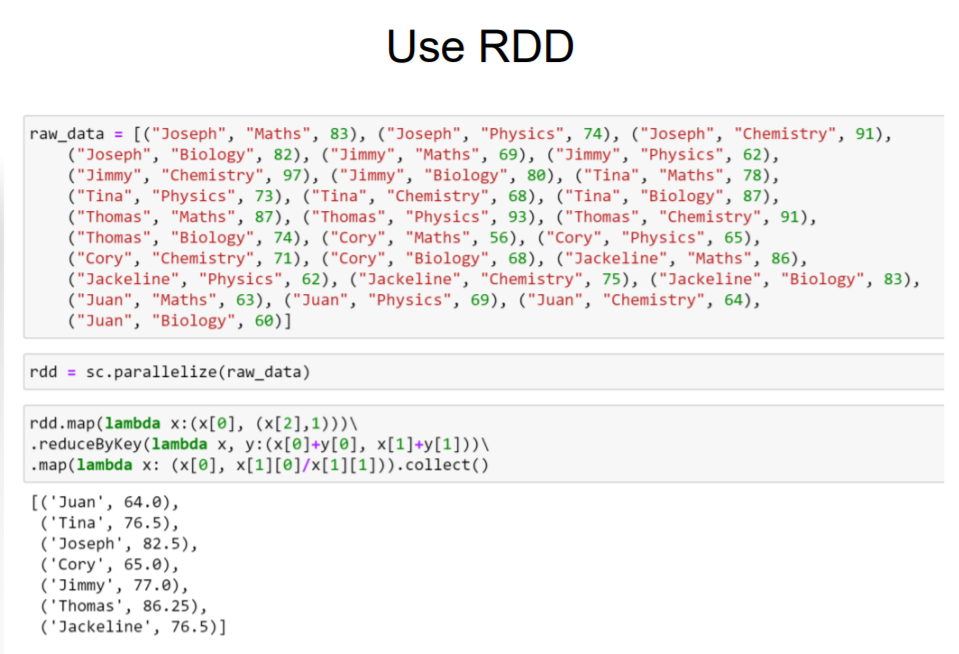
2. RDD 与 Spark SQL 操作算平均乘积

DataFrame:
1. faster than Spark SQL in single machine
2. DataFrames APS is an extension to the existing RDD API
3. SparkSession is the entry point of DataFrame API
spark = SparkSession.builder.config(conf=conf).getOrCreate()
df = spark.read.format( 'json' ).load('example.json')
df.show()
4. sql() enables applications to run SQL queries programmatically and returns the result as a DataFrame.
5. You can mix DataFrame methods and SQL queries in the same code.
6. DataFrames are lazy. Actions cause the execution of the query
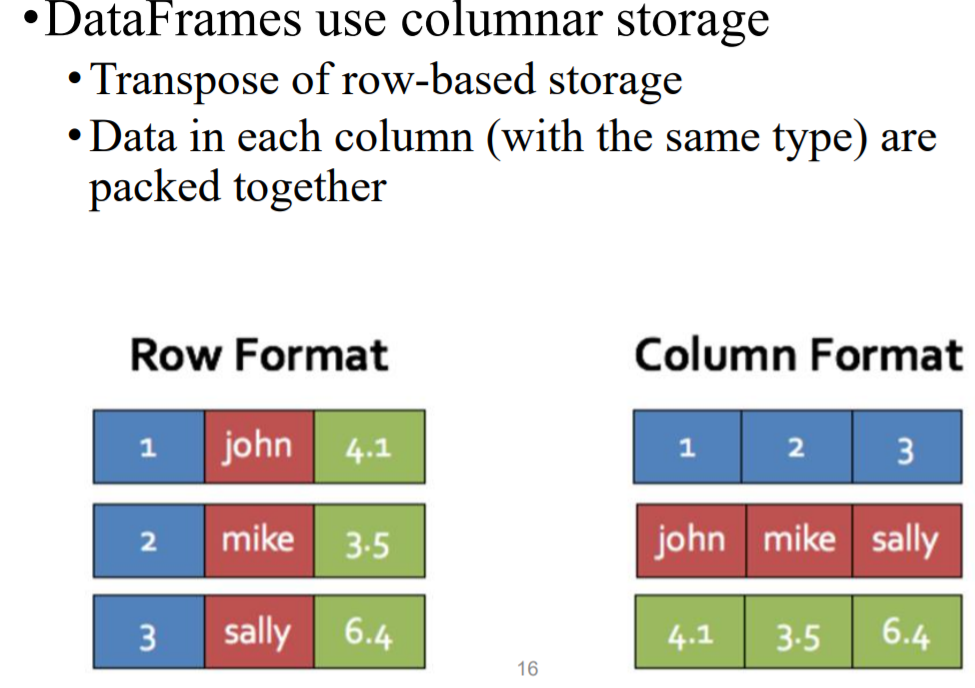
7. DataFrames uses columnar storage
1)保证每行的数据是相同type

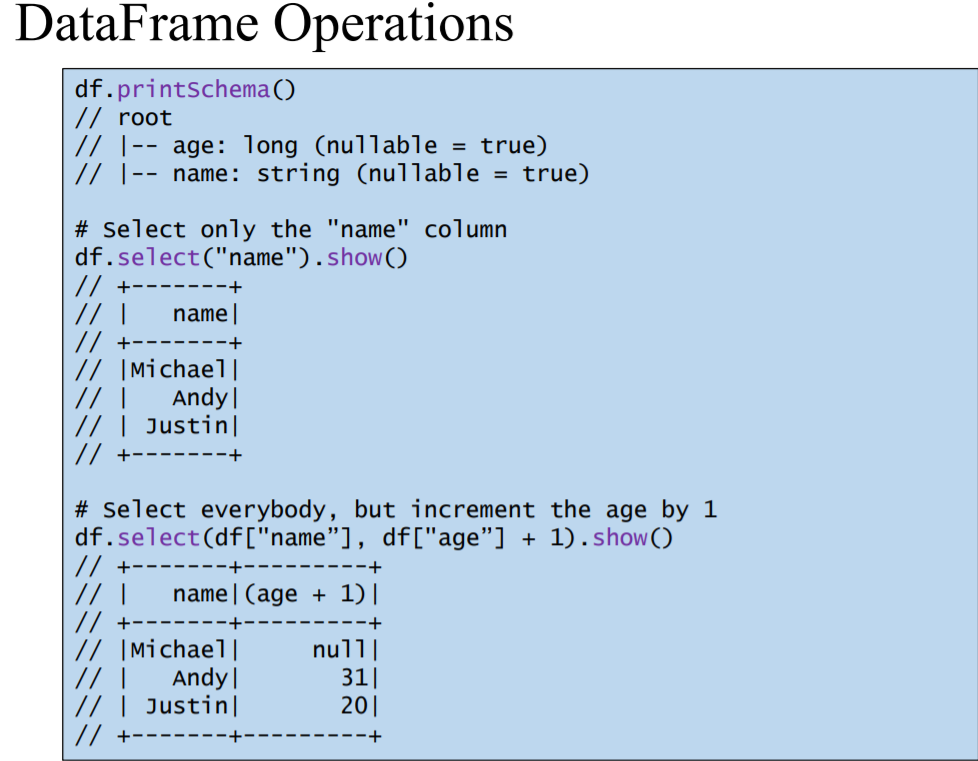


DataFrame and RDD
1. •DataFrames are built on top of the Spark RDD API
1)You can use normal RDD operations on DataFrames
2.Stick with the DataFrame API if possible
1)Using RDD operations will often give you back an RDD, not a DataFrame
2)The DataFrame API is likely to be more efficient, because it can optimize the underlying operations with Catalyst
Spark SQL:
1. Plan optimization and Execution
1) logical plan
Logical Plan is an abstract of all transformation steps that need to be performed
• It does not refer anything about the Driver (Master Node) or Executor (Worker Node)
• SparkContext is responsible for generating and storing it
• Unresolved Logical Plan
• Resolved Logical Plan
• Optimized Logical Plan
2) physical plans

 浙公网安备 33010602011771号
浙公网安备 33010602011771号