COMP9517 week5 机器学习
https://echo360.org.au/lesson/29e8e4ac-4007-4e31-b682-aa9da17ddd36/classroom#sortDirection=desc
总结:
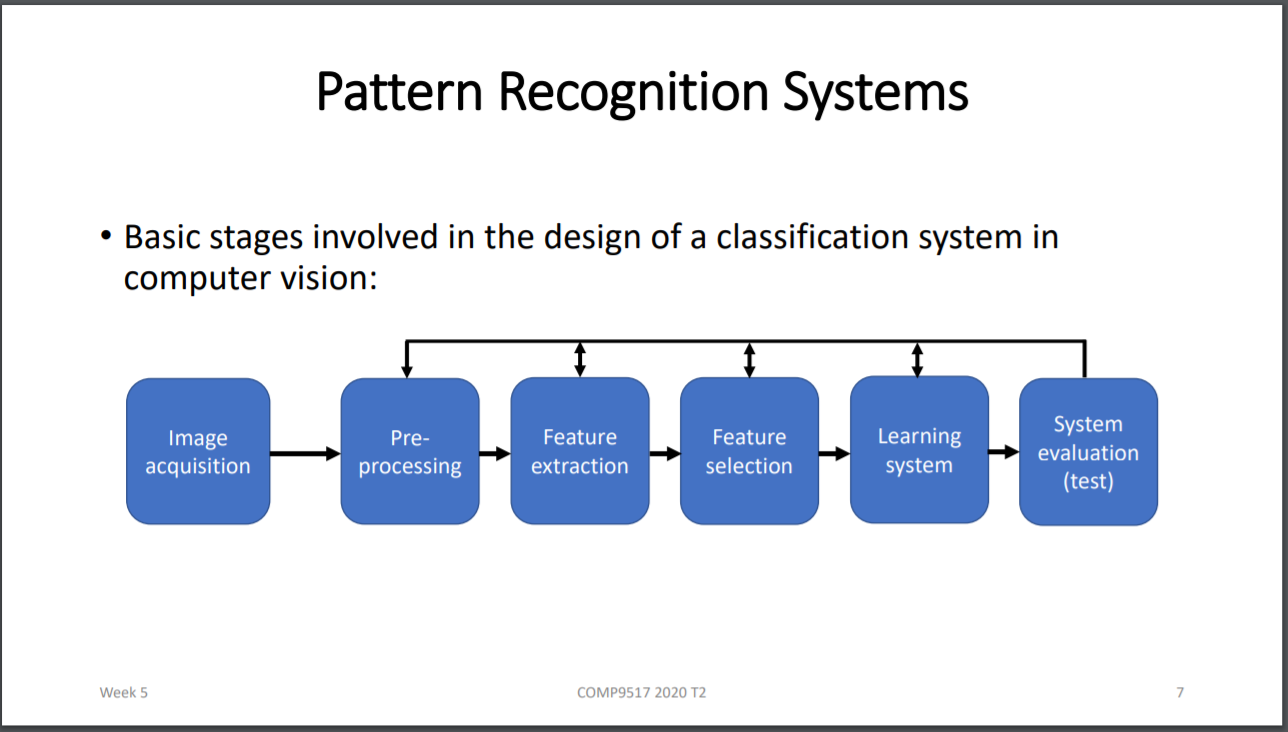
1.Pattern recognition

2. Nearest Class Mean Classifier
1) 计算 k 类样本的class mean vector
2) test set的输入向量X,被分到一类,if it is much closer to the mean vector of class 𝑘 than to any other class mean vector
3) X与 mean vector 之间的距离用 Euclidean distance 计算
4) 如果某类k,有两个子类,则分别计算两个子类的 mean vector
5) Pros : classes之间间隔远,区别明显时,该模型效果好
6) Cons: 样本复杂,多类时,使用效果差;不能处理outliers,missing data


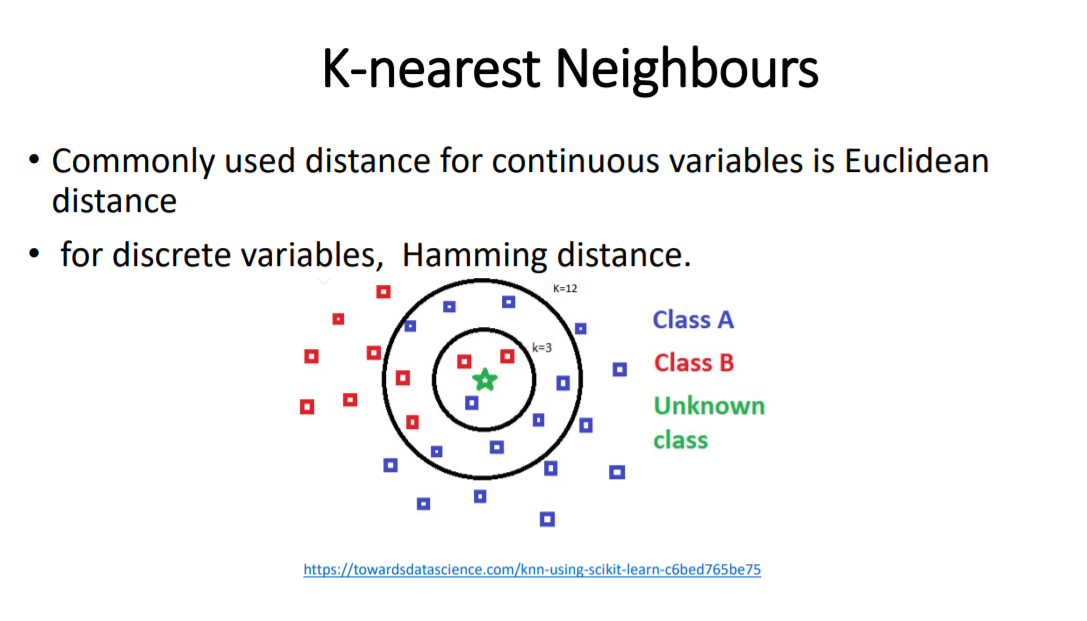
3.K-nearest Neighbours (KNN)
1) sample会被分发label,该label是KNN中的多数类
2) 计算离sample最近的k个邻居时,计算距离的方法一般使用(计算连续various时)Euclidean distance
3) for discrete variables, Hamming distance.
4) Pros:
1.没有 training step
2. Decision surfaces are non-linear
5) Cons:
1. 数据集大的时候非常慢,O(N^2)
2. 当features很多,维度很大的时候,效果不好,解释性差(curese of dimensionality)
4. Bayesian Decision Theory
1) 分类器的分类可能不正确,所以分类结果应该设为概率;Object会被分到概率最大的class
2)


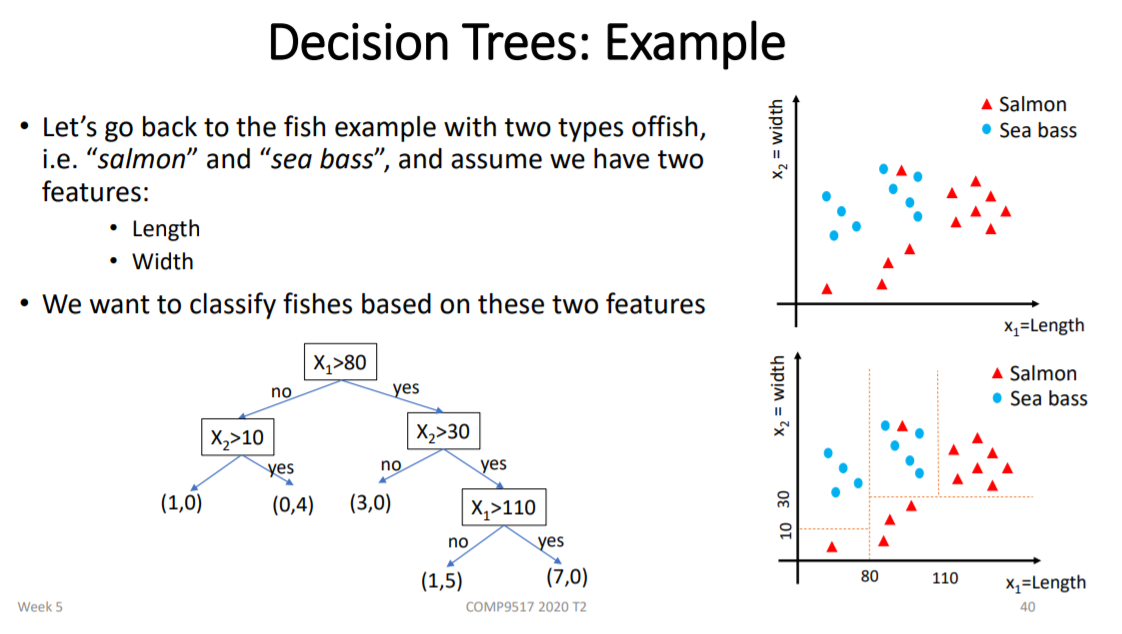
5. Decision Tree
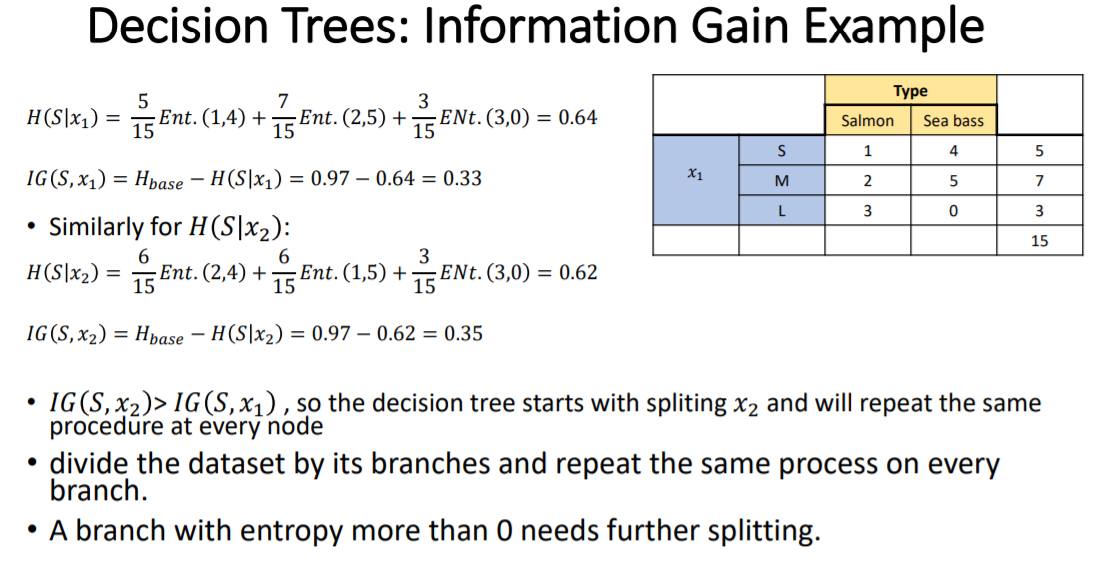
1) 完全分类时,熵是0,没完全分类时,是正数,所以要做的是minimize(entropy)
2) 分类越好,entropy就越小,information gain就越大
3) 从哪个feature分割,information gain大,就用哪个feature做node
4) Pros:
1. 很好解释
2. 能处理numerical与categorical数据
3. 能处理outliers,missingvalue
4. 能区别features的importance
5)Cons: tend to overfit

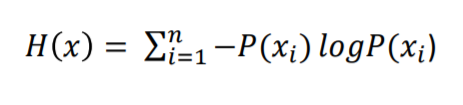

6. 集成学习,RandomForest
1)error rate
1. RF的error rate受forests'correlation以及individual tree's strength
2. corelation越大strength越小,会导致error_rate越大
3. forests'correlation与strength都与每棵树选择的features数量m成正相关关系
4. 所以需要对m进行trade-off
2)pros
• unexcelled in accuracy among current algorithms
• works efficiently on large datasets
• handles thousands of input features without feature selection
• handles missing values effectively
3) Cons:
• less interpretable than an individual decision tree
• More complex and more time-consuming to construct than decision trees
7. SVM

 浙公网安备 33010602011771号
浙公网安备 33010602011771号