COMP9313 week4a MapReduce
https://www.cse.unsw.edu.au/~cs9313/20T2/slides/L4.pdf
https://drive.google.com/drive/folders/13_vsxSIEU9TDg1TCjYEwOidh0x3dU6es
MapReduce
总结:
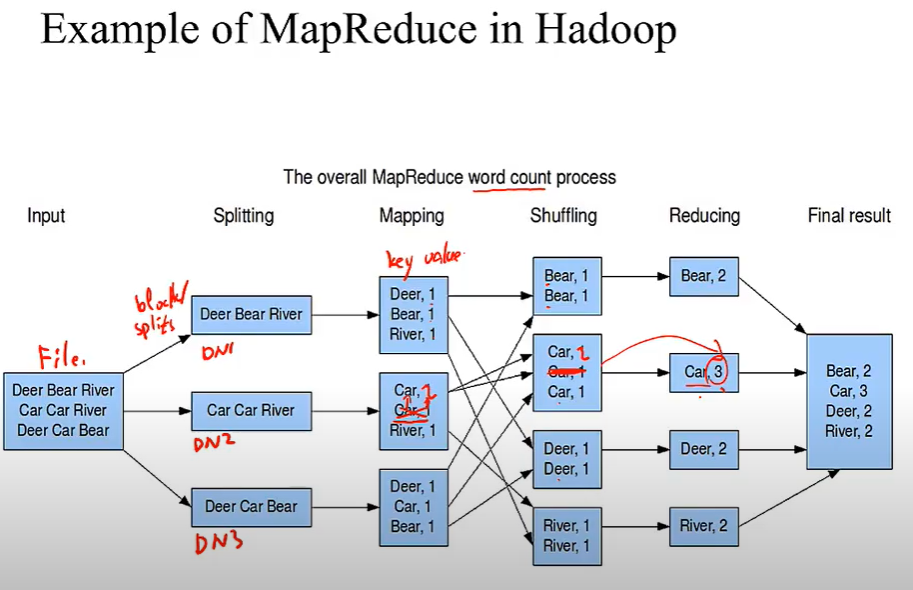
1. MapReduce in Hadoop:
1) input splits
1) input被分成splits,Hadoop 给每个split创建一个map task, map task运行定义好的map function
2)每个split的大小与HDFS里block的大小相同(128MB),这是为了保证files都在一个Node中,超过一个block大小则不能保证多个blocks在同一个Node.
2)Map Reduce outputs
(1)Map output一般是中间output,不被写入HDFS(不被nameNode记录),一般写入worknodes,datanodes,计算结束后丢掉
(2)Reduce task的output被写入HDFS
3)partition
(1) 当有多个reducers的时候,map tasks partition the output 分成number of reducers那么多份,然后再merge
(2)partition是根据key来partition的,例如<k1,v1> <k1,v2> <k2,v3> 前两个要分在一起
2. Shuffle in Hadoop
1) shuffle即图中的copy部分,shuffle is the process from mapper to reduce. Shuffle是为了保证reducers接收到全部的有着相同key的values.

2)Use Shuffle and Sort mechanism (下图中没有显示出来 比如sortKey, combiner)
(1)•Results of each Mapper are sorted by the key
(2)•Starts as soon as each mapper finishes
(3)•Use combiner to reduce the amount of data shuffled
3. Shuffle in Spark
1) shuffle in Hadoop/Spark 的差别
(1)shuffle in Hadoop is triggered by reducer
(2)shuffle in Spark is triggered by operations, like Distinct, join, repartition, all *By, *ByKey ,Happens between stages
2)Hash Shuffle
(1) 在Hadoop,使用sort and shuffle:将'3 1 2 3 2'排序成'1 2 2 3 3',O(nlogn)
(2)在Hash Shuffle 我们使用 Hash and shuffle,只需要将相同Key存在一起就好,不需要排序 将'3 1 2 3 2'sort成'3 3 1 2 2',O(N)

3)sort Shuffle
(1)partitions大的时候,sort比hash站空间小,但是慢
(2)partitions小的时候,由于可用hash,更快

4. MapReduce Functions in Spark

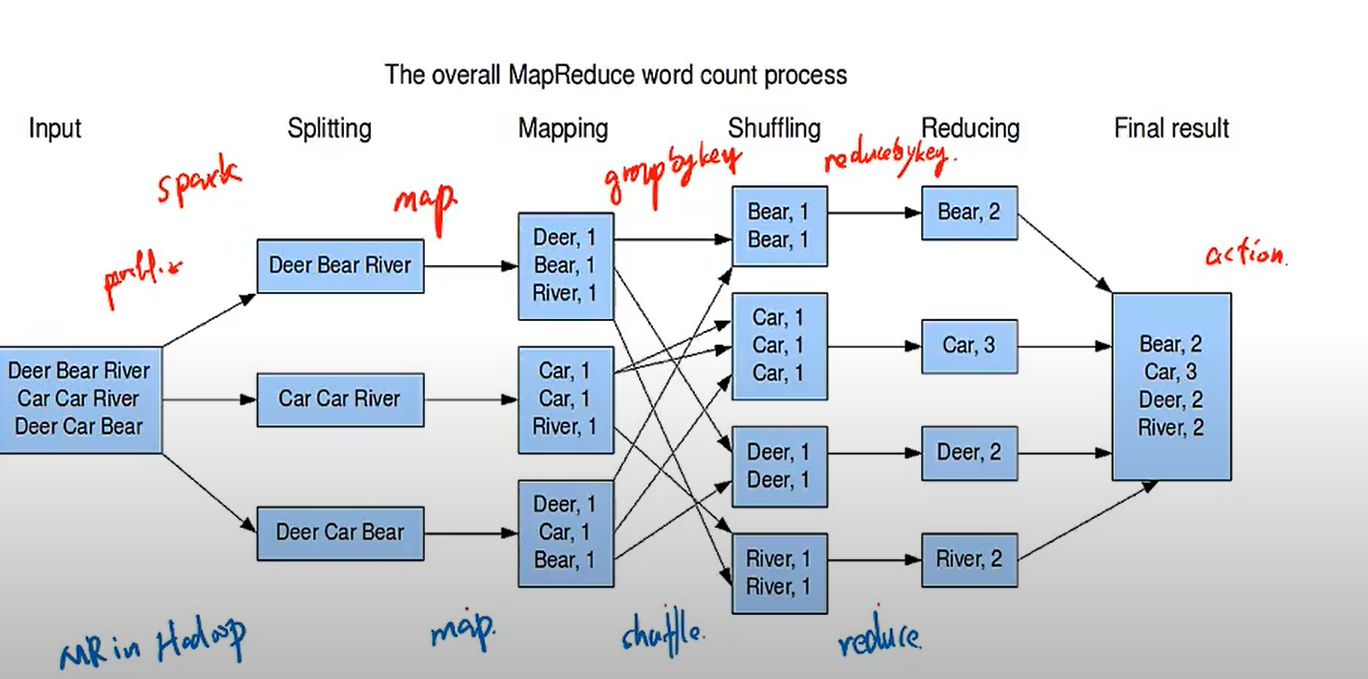
1) combineByKey
2) reduceByKey
3) groupByKey
5.The Efficiency of MapReduce in Spark
1)Number of transformations
例题: sum,max

2)•Size of transformations
count不同字母开头的数量

3)Shuffles
统计第二个字母的count


 浙公网安备 33010602011771号
浙公网安备 33010602011771号