大数据 week2 Hadoop and HDFS
https://www.cse.unsw.edu.au/~cs9313/20T2/slides/L2.pdf
https://drive.google.com/drive/folders/13_vsxSIEU9TDg1TCjYEwOidh0x3dU6es
Hadoop:
1.•Stores big data in a distributed manner 分布式存储大数据
2.•Processes big data parallelly 并行处理数据
3.Builds on large clusters of commodity hardware 建立在大型商业硬件集群上
其功能通过以下实现
1.Redundant, Fault-tolerant data storage (HDFS)
2.•Parallel computation framework (MapReduce)
3.Job coordination/scheduling (YARN)
HDFS :Hadoop Distributed File Systems
1. 支持分布式存储,分布式运行,通过增加机器数目增加内存(• horizontal scalability)
2. 数据被存储在多个节点(重复存储)
3.允许多人访问数据
4.结构有三类 NameNode ,Secondary NameNode, DataNode
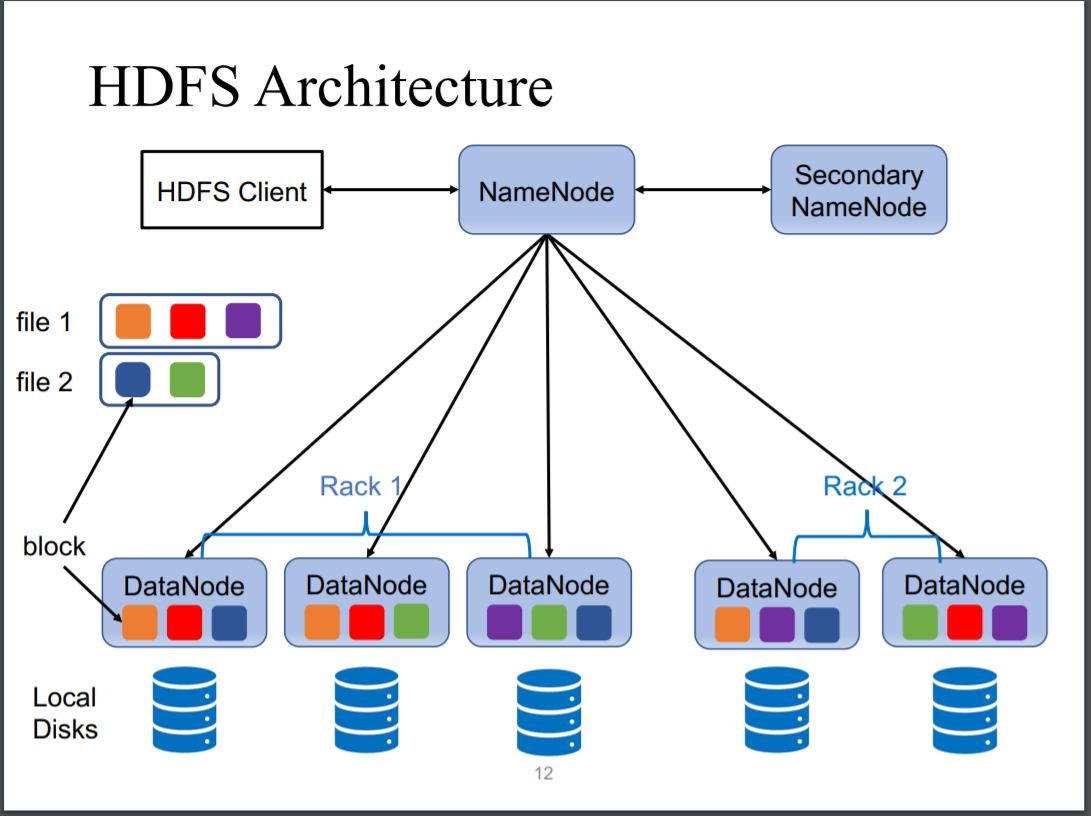
NameNode:
1.主节点,维护管理从节点(DataNodes)
2.记录metadata (元数据(Metadata),又称中介数据、中继数据,为描述数据的数据(data about data),主要是描述数据属性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。)
3.定期检查datanodes的status(DataNodes每几秒会发送信息至NameNode)
4.处理失败Nodes

DataNodes:
1.存储数据
2.响应读写请求
3.reports the health to NameNode(heartbeat)

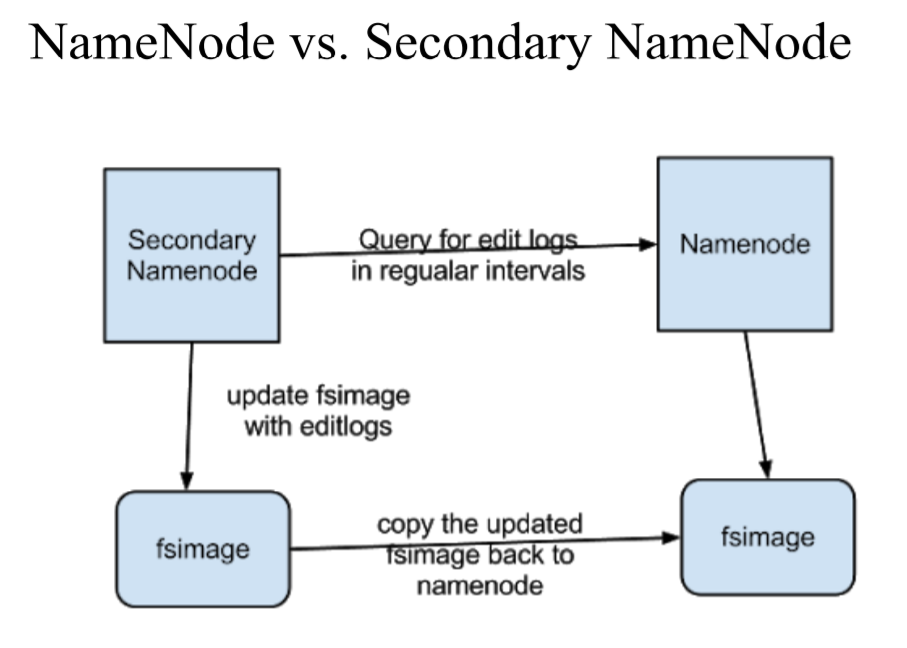
Secondary Node:
1.存储 fsimage editlogs的备份
2.周期性 apply editlogs to fsimage and refresh the editlogs
3.防止NameNode坏掉

Blocks:
1. 存入HDFS中的文件都会以blocks的形式存在,小于等于128M



 浙公网安备 33010602011771号
浙公网安备 33010602011771号