
CV第十课 RNN 中 Image Captioning + Attention
http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture10.pdf
Image Captioning
1. 图片生成文字中CNN,RNN的混合使用
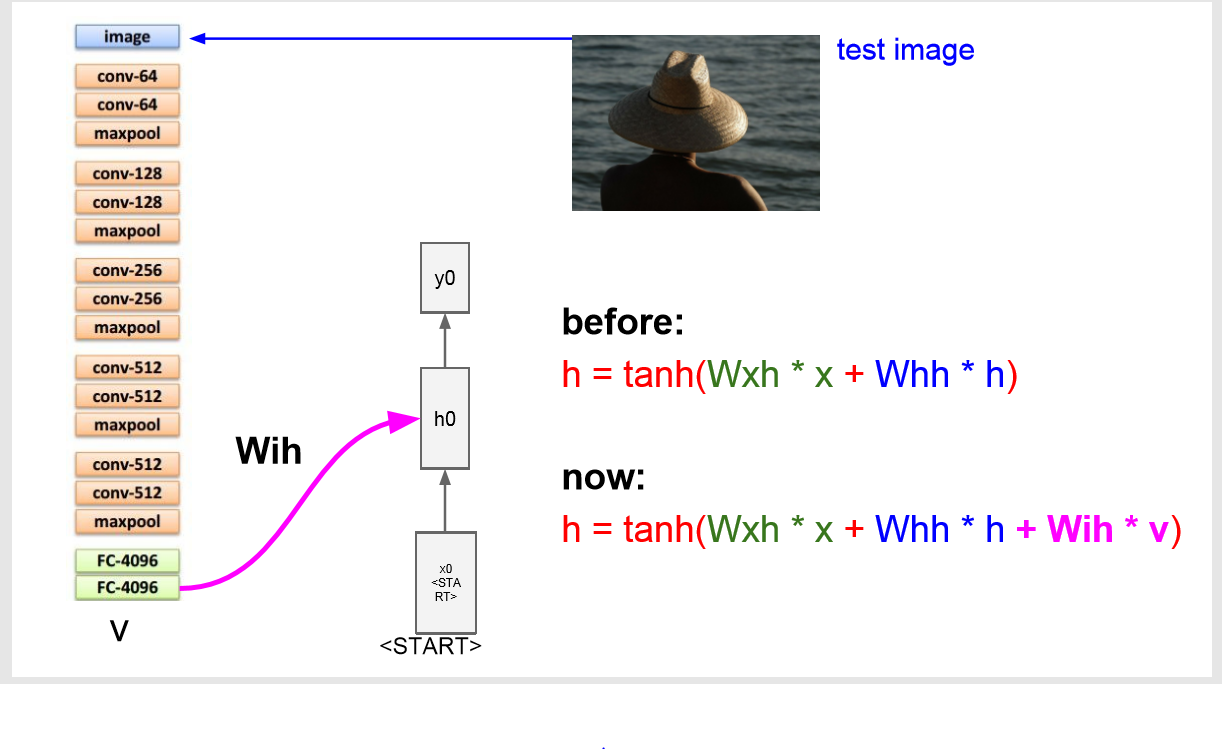
1) CNNs接收images,生成图片的特征向量(a summary vector of the image) 传入RNN语言模型的第一个timestep 然后一次一个的产生标题的单词。

2) 网络图
RNN: 不接受 softmax 而是接受 4096维的向量 作为图片的特征描述
在RNN模型中加入了矩阵 Wih
RNN的输出y 作为下一个timestep的输入
最后得到一个完整的句子来描述图片
Microsoft COCO 可能是这方面最大的训练集



2. Image Captioning with Attention
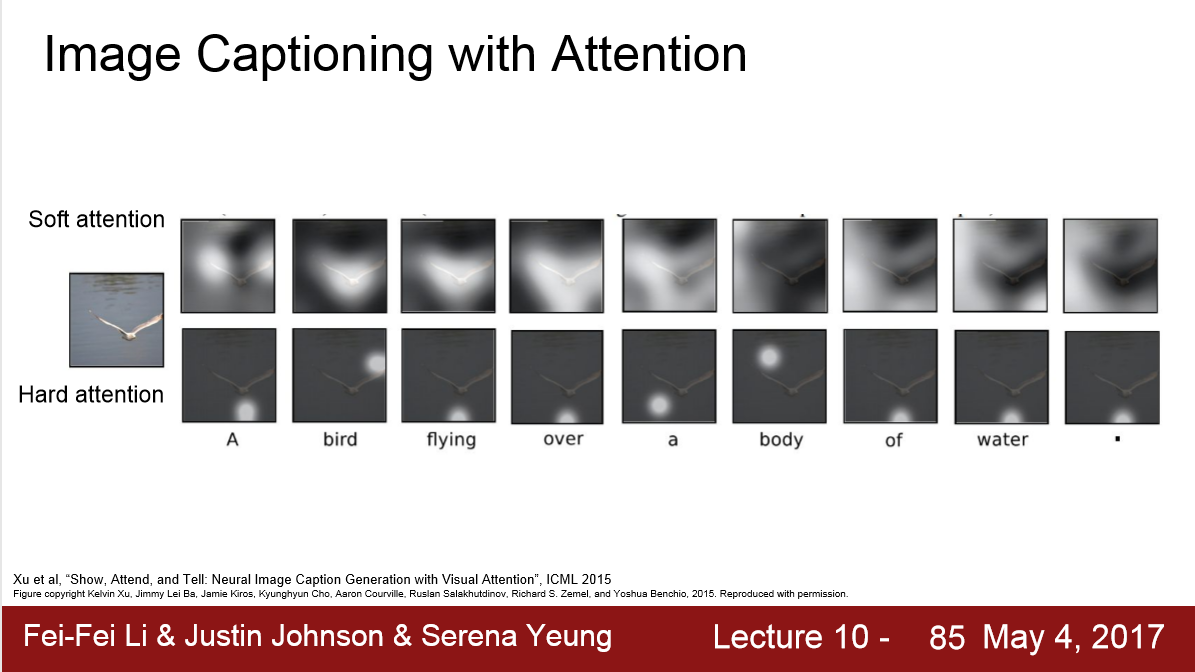
1) 我们的CNN 不输出一个 single vector, 而是生成一个 grid of vectors,可以让每个vector对应一个图片中的特殊地方
2) RNN的每一步timestep中,除了在每一步中采样,它也产生了一个分布(distribution)对应于图片中它想注意的位置 a1,a2,.....
3) 对于 soft attention 采用的是加权组合 of 所有图像中的所有特征 / hard attention 限制模型每步只选择一个位置 来观察图片




2) soft attention/ hard attention
3. Visual Question Answering (视觉问答)
1) 如何将编码的图像向量,与编码的问题向量结合在一起?
concatenate 两个向量 然后传入全连接层


 浙公网安备 33010602011771号
浙公网安备 33010602011771号