
CV 第十课 RNN 上
http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture10.pdf
1. 分类
one - many: one 可能是Image,输出的many可能是sequence of words
many - one: 可以是情感分析 sequence of words -> sentiment ; frames of a video -> actions 识别video中的动作
many to many : 机器翻译 seq of words -> seq of words ; Video classification on frame level
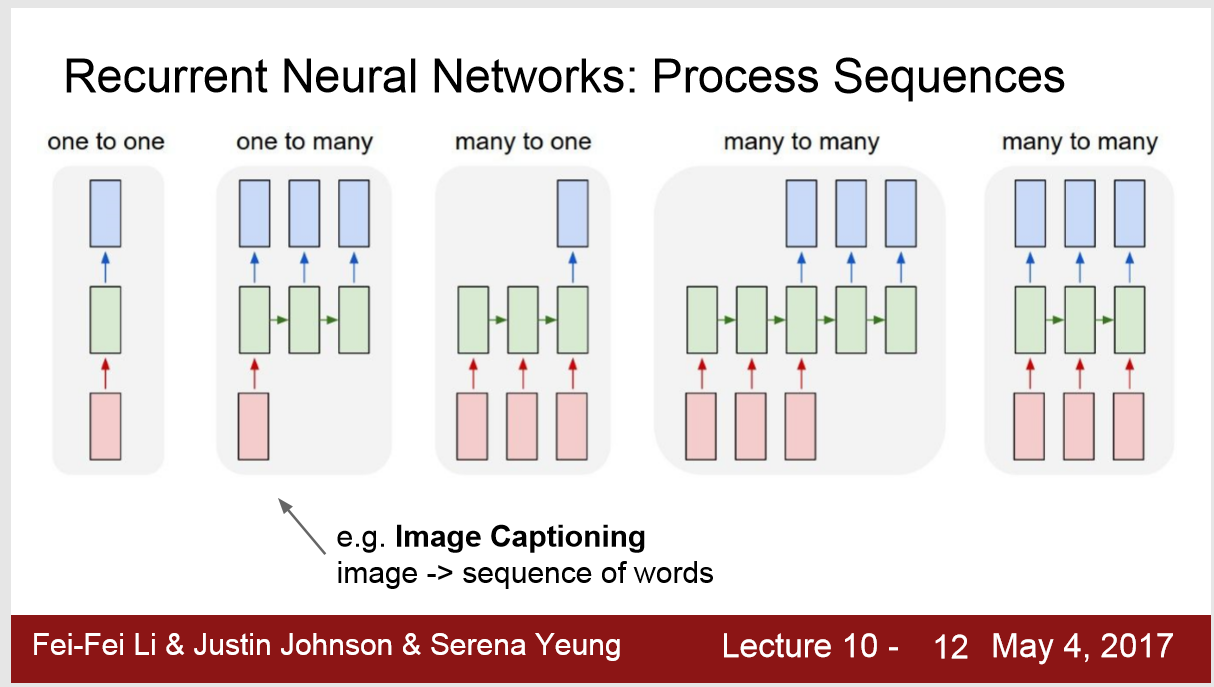
2. RNN也能处理这种情况: fixed input size and fixed output size

3. RNN 的更新: 每一步更新hidden state
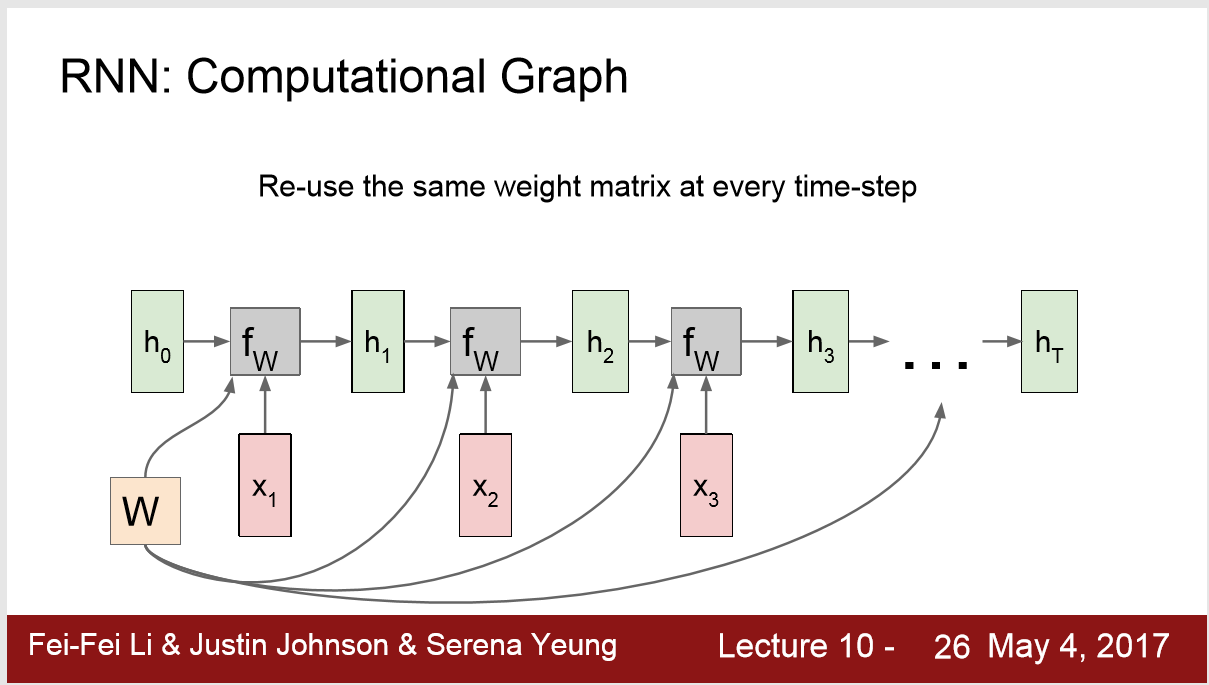
1) 每一步使用的函数 fW,权重W 是相同的

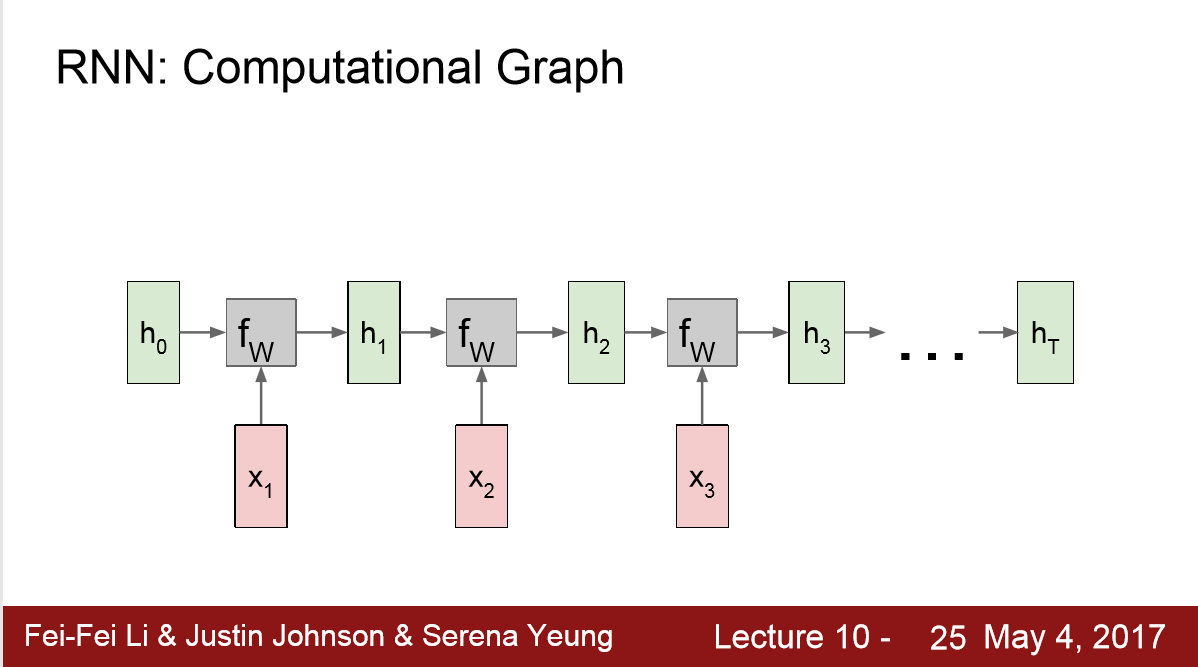
4. Vanilla
1) 计算图如下 :
一般的 h0 = 0,每一步将 ht-1 x带入 fW ht = tanh( Whh ht-1 + Whx Xt)
其中,在一次RNN运行中,W都是相同的
2) W的更新
运行完一次后,进行backpropagation,利用梯度对W进行更新
3) loss
运行单次RNN时,我们会得到 t 次 y,每一步都会得到一个loss,like softmax loss ,最后将这些Loss加在一起得到 L
然后Loss在每一步都计算 local gradient
loss.backward()



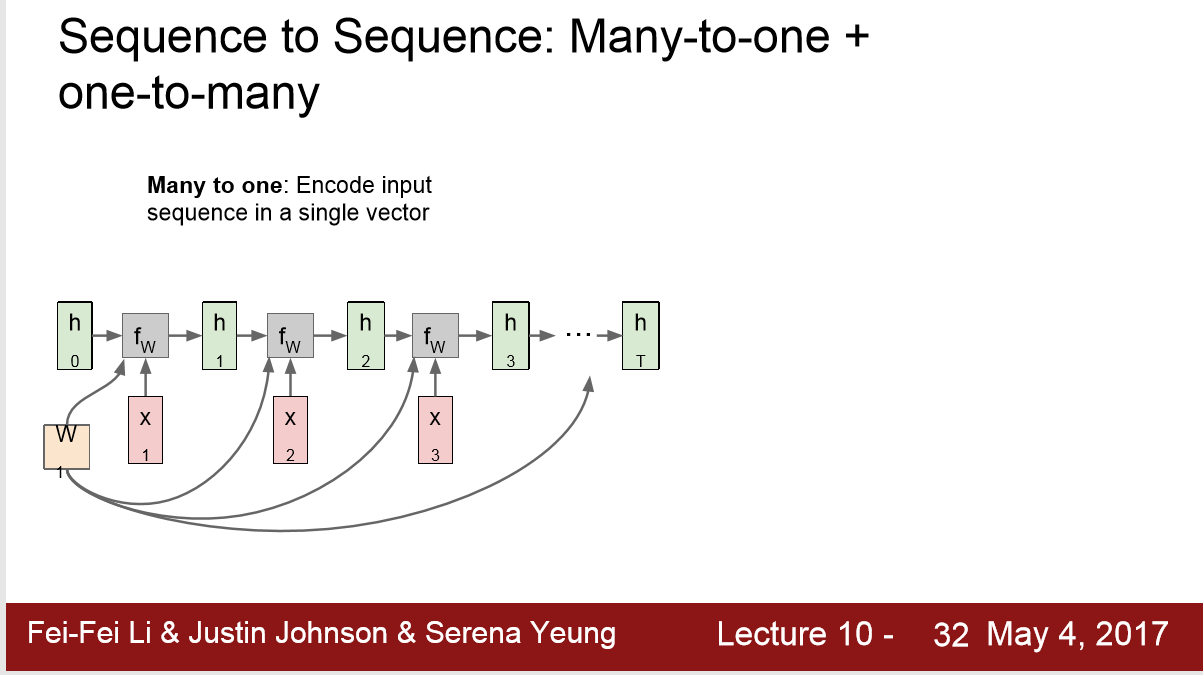
5. 翻译
1) 可以当时 one to many + many to one
2) 将一连串的input encode 成单个 vector many to one
3) 单个输入,输出 output sequence

6. language modelling
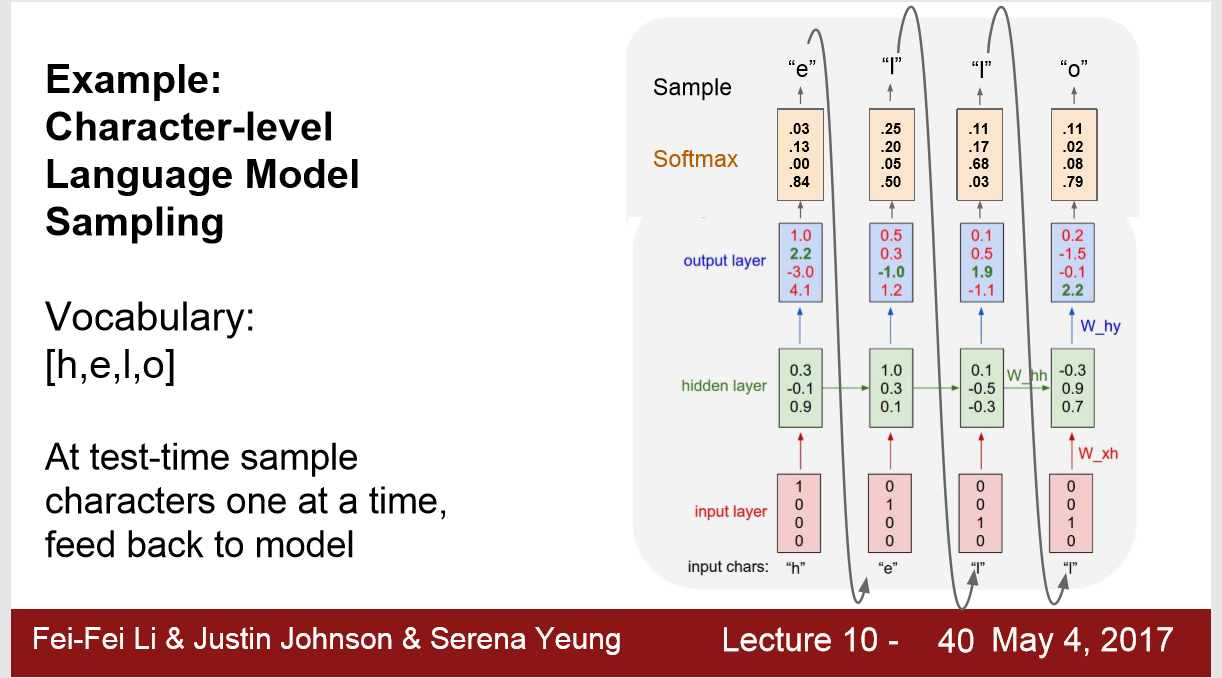
1) 例如characters-level 的model ,预测下一个输入的character
输入: one-hot的编码的h
预测输出: e (2.2)
实际最大: o (4.4)
措施: 这个时候应该用 softmax loss 来度量我们对预测结果的不满意程度

2)
test time ,选取输出时,可以选取softmax中第一大或者第二大的值。
在输入为 'h' 向量这里,我们选择softmax中值第二大的作为输出。 因为有时单词都有相同的前缀,图片也是。选取第二大的输出,可以产生大量不同的合理输出序列。
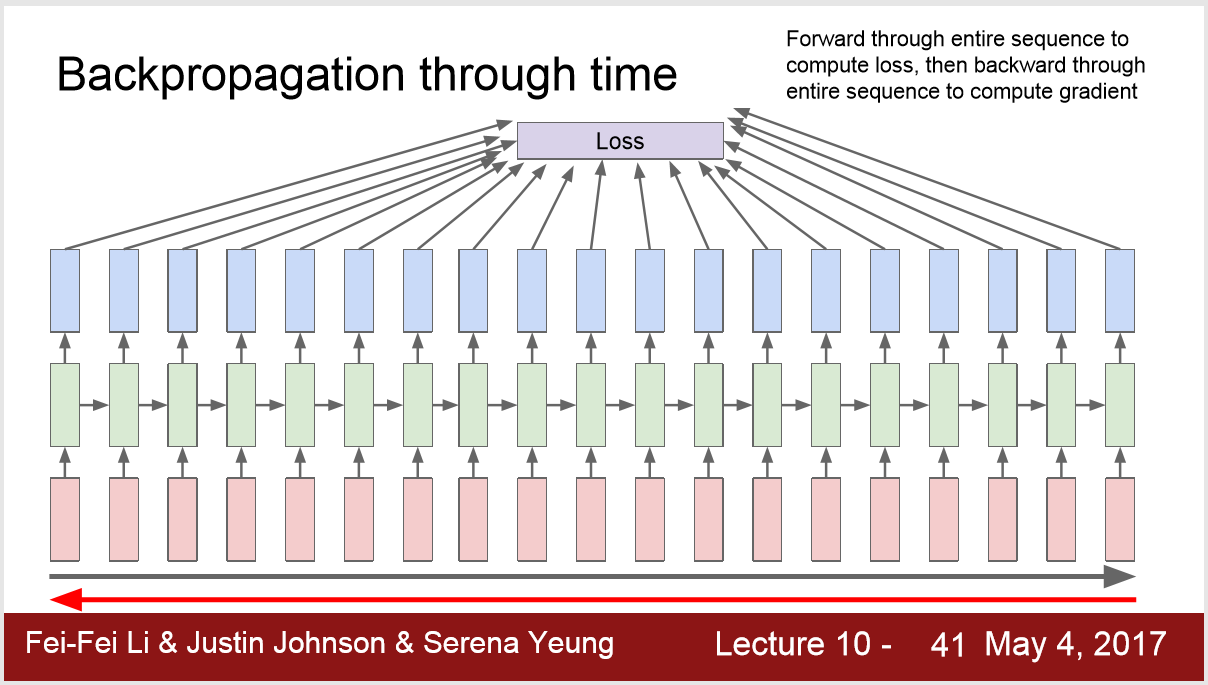
3) 梯度更新的问题:
问题 : 在做一些大样本的模型,如wikipedia的单词时,forward所有的单词计算loss,backward所有的单词计算梯度,才能前进一个learning rate,这样做太缓慢了,模型也不会收敛。
 4
4
4) 梯度更新的方法:
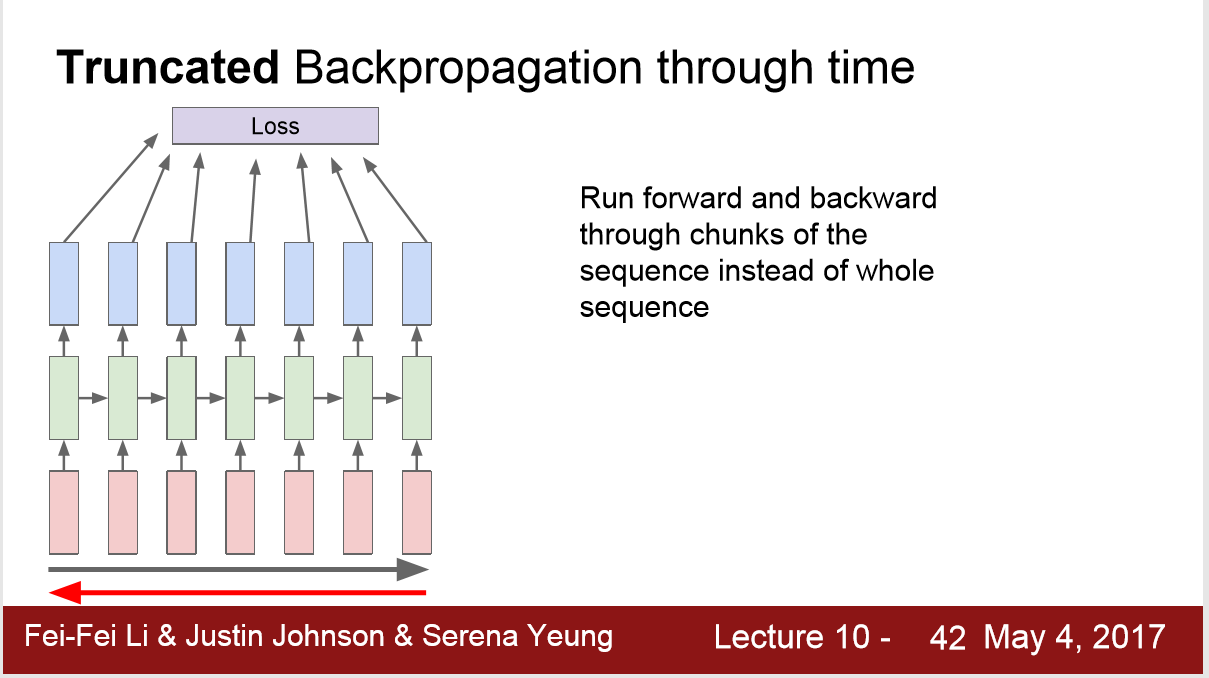
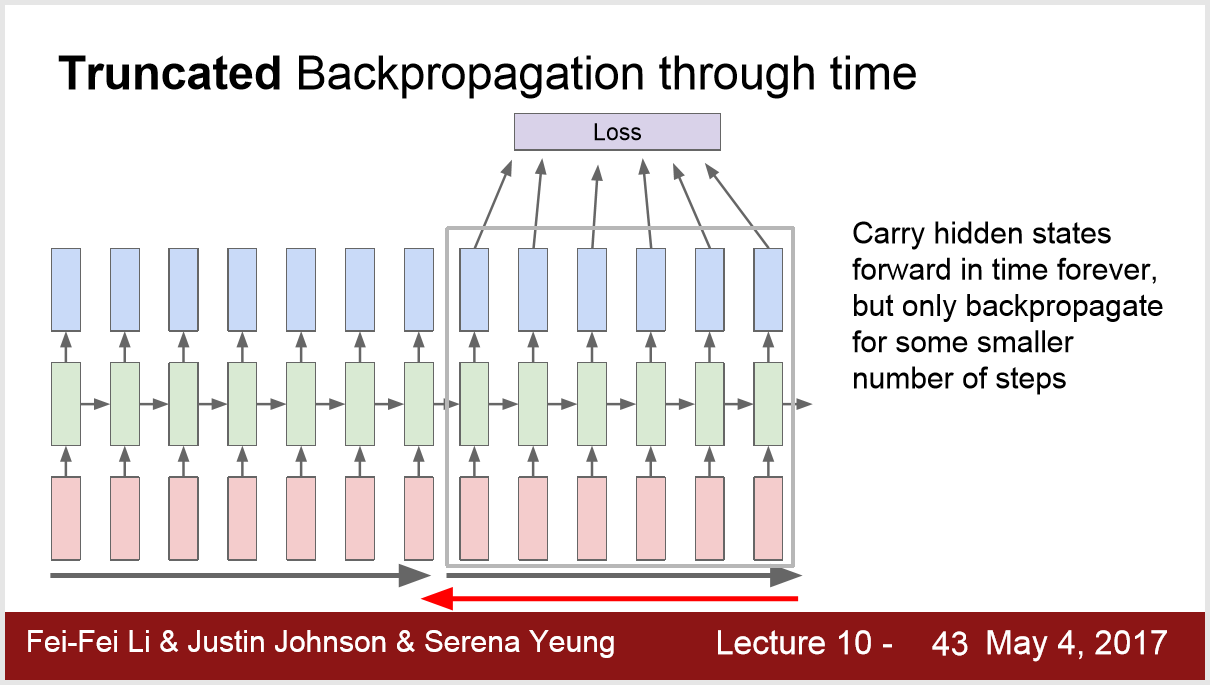
7. 模型结果~
用该模型读取一些文本,之后的输出效果非常好,比如莎士比亚形的文章,数学教科书,甚至还有code
https://gist.github.com/karpathy/d4dee 566867f8291f086


