中文字符编码
Unicode是支持最广的,这就意味着我们可以作为一个中间体来转换。多种字符集都是可互相转的,很简单。
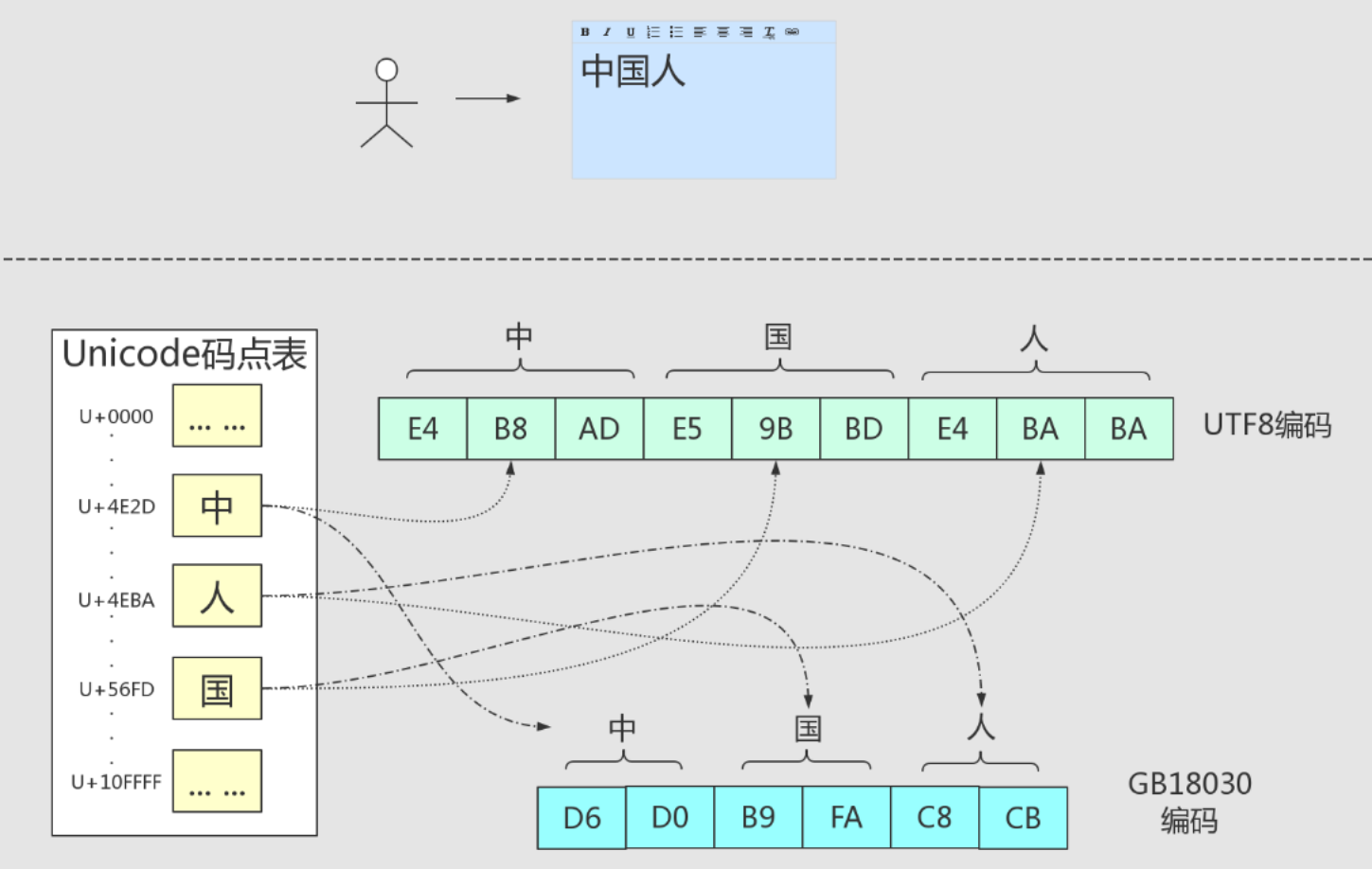
https://tonybai.com/2019/11/07/non-ascii-character-encoding-illustrated/
func main() { var s = "中国人" // rune == 码点 == Unicode中的序号 == Unicode字符 // 中 => 码点:4E2D // 国 => 码点:56FD // 人 => 码点:4EBA // 结合图一目了然 for _, v := range s { fmt.Printf("%s ===> 码点 : %X\n", string(v), v) } println() // 汉字是以UTF-8编码存储的 // 直接可以转换看到字节 // E4B8AD ===> 可以看到是3个字节,符合UTF-8对于汉字的编码规则 for _, v := range []byte(s) { fmt.Printf("%X", v) } }
对于转换等,开源的很多。
一个没有高级趣味的人。
email:hushui502@gmail.com
