
Map
Hashtable、HashMap、TreeMap有何不同
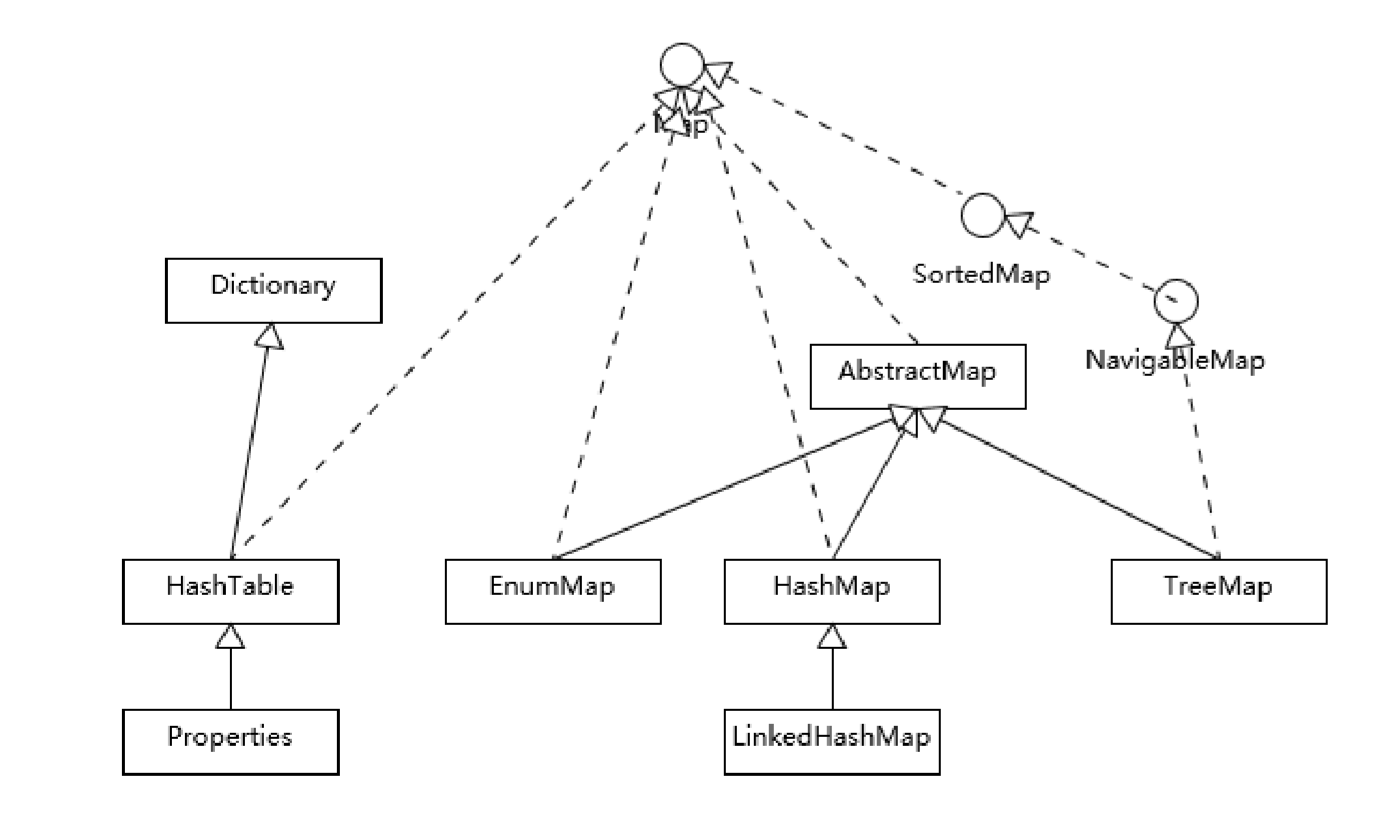
HashTable是一个早期的集合类型,所以在继承扩展上是有区别的。
大部分使用Map的场景,通常就是放入、访问或者删除,而对顺序没有特别要求,HashMap在这种情况下基本是最好的选择。HashMap的性能表现非常依赖于哈希码的有效性,请务必 掌握hashCode和equals的一些基本约定,比如:
1.equals相等的对象,hashCode也一定相等。因为我们是我们是通过hash得到对象所在的“链表节点”,然后再进行equals对比的,所以相同的hashCode不一定equals相等,但是反之必然。实际上来讲,单纯的hash不满足很多业务需求,因此扩展出了一种一致性哈希,这个在外文翻译里有一篇。
https://medium.com/ably-realtime/how-to-implement-consistent-hashing-efficiently-fe038d59fff2
2.重写了hashCode也一定要重写equals,实际上不建议自己重写,因为并非比较简单的事情。
3.hashCode需要保持一致性,状态改变返回的哈希值仍然要一致。
4.equals的一些对称反射传递特性
TreeMap和LinkedHashMap保证存放顺序是不同的
public class LinkedHashMapTest { public static void main(String[] args) { Map<String, String> map = new LinkedHashMap<>() { @Override protected boolean removeEldestEntry(Map.Entry<String, String> eldest) { return size() > 3; } }; map.put("a", "1"); map.put("b", "2"); map.put("c", "3"); map.put("d", "4"); map.forEach((k, v) -> { System.out.println(k + " : " + v); }); } }
输出
b : 2 c : 3 d : 4
这适合一种空间敏感的场合。
对于TreeMap来讲,它的整体的顺序就是由键的顺序决定的,实际上就是通过Comparator或Comparable(自然顺序)来决定。
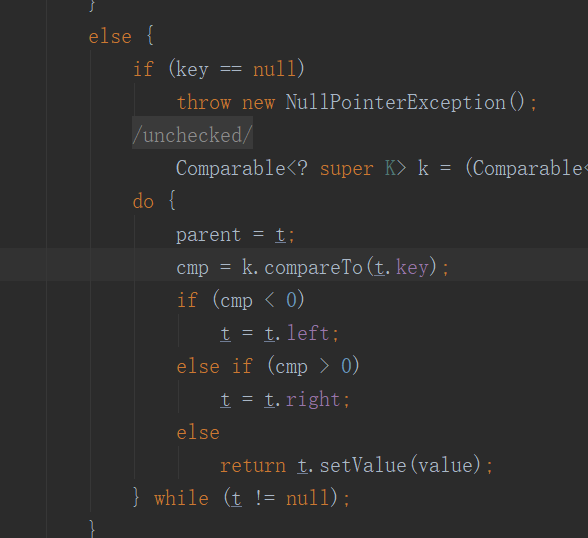
可以看出就是典型的树结构,但是要注意compareTo的返回值要保证和equals一致。
当我不遵守约定时,两个不符合唯一性(equals)要求的对象被当作是同一个(因为,compareTo返回0),这会导致歧义的行为表现。
HashMap分析
1.内部实现
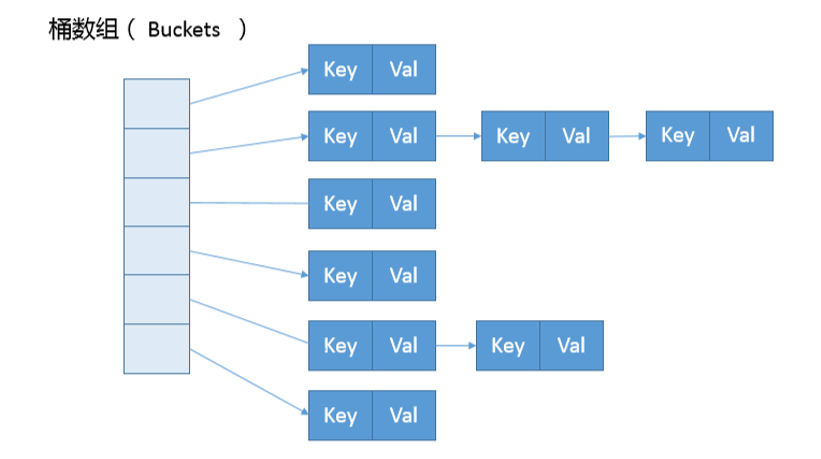
看HashMap内部的结构,它可以看作是数组(Node[] table)和链表结合组成的复合结构,数组被分为一个个桶(bucket),通过哈希值决定了键值对在这个 数组的寻址;哈希值相同的键值对,则以链表形式存储,你可以参考下面的示意图。这里需要注意的是,如果链表大小超过阈值(TREEIFY_THRESHOLD, 8),图中的链表就会被 改造为树形结构。
public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; this.threshold = tableSizeFor(initialCapacity); }
构造函数的实现来看,这个表格(数组)似乎并没有在最初就初始化好,仅仅设置了一些初始值而已。这么明显肯定是懒加载模式了。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) // 确定节点的桶位置,采用位运算提高效率 tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) // 放置新值扩容的条件 resize(); afterNodeInsertion(evict); return null; }
可以确定了是懒加载机制。分析:
1.如果表格是null,resize方法会负责初始化它,这从tab = resize()可以看出。
2.resize方法兼顾两个职责,创建初始存储表格,或者在容量不满足需求的时候,进行扩容(resize)。
key并不是hashCode
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
将高位数据移位到低位进行异或运 算呢?这是因为有些数据计算出的哈希值差异主要在高位,而HashMap里的哈希寻址是忽略容量以上的高位的,那么这种处理就可以有效避免类似情况下的哈希碰撞。
resize分析
jdk代码太长不展示
依据resize源码,不考虑极端情况(容量理论最大极限由MAXIMUM_CAPACITY指定,数值为 1<<30,也就是2的30次方),我们可以归纳为:
1.门限值等于(负载因子)x(容量),如果构建HashMap的时候没有指定它们,那么就是依据相应的默认常量值。
2.门限通常是以倍数进行调整 (newThr = oldThr << 1),我前面提到,根据putVal中的逻辑,当元素个数超过门限大小时,则调整Map大小。
3.扩容后,需要将老的数组中的元素重新放置到新的数组,这是扩容的一个主要开销来源。
负载因子和容量的设值是很重要的,这里复杂点牵扯到一些数学问题,当然也有一个通用标准
1.负载因子 * 容量 > 元素数量
2.负载因子是不建议改动,不得不改动也应< 0.75,否则会增加冲突,为什么,因为你的桶依然是那些,但是可存放的阈值却高了很多,面临的风险肯定也会更大,对于现在的计算机发展来讲,我们更倾向于空间换风险。
我们前面提到了树化改造,对应逻辑主要在putVal和treeifyBin中。
final void treeifyBin(Node<K,V>[] tab, int hash) { int n, index; Node<K,V> e; if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) resize(); else if ((e = tab[index = (n - 1) & hash]) != null) { TreeNode<K,V> hd = null, tl = null; do { TreeNode<K,V> p = replacementTreeNode(e, null); if (tl == null) hd = p; else { p.prev = tl; tl.next = p; } tl = p; } while ((e = e.next) != null); if ((tab[index] = hd) != null) hd.treeify(tab); } }
这段代码就两个意思:
1.如果容量小于MIN_TREEIFY_CAPACITY,只会进行简单的扩容。
2.如果容量大于MIN_TREEIFY_CAPACITY ,则会进行树化改造。
为什么HashMap要树化呢?
本质上这是个安全问题。因为在元素放置过程中,如果一个对象哈希冲突,都被放置到同一个桶里,则会形成一个链表,我们知道链表查询是线性的,会严重影响存取的性能。
而在现实世界,构造哈希冲突的数据并不是非常复杂的事情,恶意代码就可以利用这些数据大量与服务器端交互,导致服务器端CPU大量占用,这就构成了哈希碰撞拒绝服务攻击。
扫盲end
杂谈:做什么事需要考虑意义吗?这个意义谁定义的?吃饭算不算的上是最有意义的,不吃就会饿死,但事实上没什么人认为它是有意义的,因此意义这个标准和概念就是一个完全不成立的东西。
