MySQL学习笔记
1. 操作数据库
1.1 操作数据库:
-- 使用数据库test
use test;
-- 展示所有的数据库
show databases;
-- 建立数据库test
create database test;
-- 如果gmt数据库不存在,就建立数据库test
create database if not exists test;
-- 删除test数据库
drop database test;
-- 展示test数据库中所有的表
show tables;
1.2 数据库的列类型
- 数值
| 类型名 | 描述 | 大小 |
|---|---|---|
| tinyint | 十分小的数据 | 1个字节 |
| smallint | 较小的数据 | 2个字节 |
| mediumint | 中等大小的数据 | 3个字节 |
| int | 标准的整数 | 4个字节 |
| bigint | 较大的数据 | 8个字节 |
| float | 浮点数 | 4个字节 |
| double | 浮点数 | 8个字节 |
| decimal | 字符串形式的浮点数 |
double 精度问题。
decimal 金融计算的时候一般使用decimal。
int(x) 表示有x位整数,这个是配合zerofill使用的,如果int(4) ,存储的数字是11,那么就会变成0011。无关数的大小,int(2)也可以存下100000。
- 字符串
| 类型 | 大小 | 描述 |
|---|---|---|
| char | 0-255 bytes | 定长字符串 |
| varchar | 0-65535 bytes | 变长字符串 |
| tinyblob | 0-255 bytes | 不超过 255 个字符的二进制字符串 |
| tinytext | 0-255 bytes | 短文本字符串 |
| blob | 0-65 535 bytes | 二进制形式的长文本数据 |
| text | 0-65 535 bytes | 长文本数据 |
| mediumblob | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| mediumtext | 0-16 777 215 bytes | 中等长度文本数据 |
| longblob | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| longtext | 0-4 294 967 295 bytes | 极大文本数据 |
char(n) 和 varchar(n) 中括号中 n 代表字符的个数,并不代表字节个数,不同的字符集下,一个字符所占字节不同。
- 时间日期
| 类型 | 大小 ( bytes) | 格式 | 用途 |
|---|---|---|---|
| date | 3 | YYYY-MM-DD | 日期值 |
| time | 3 | HH:MM:SS | 时间值或持续时间 |
| year | 1 | YYYY | 年份值 |
| datetime | 8 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| timestamp | 4 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳,从1970.1.1到现在的毫秒数 |
1.3 数据库的字段属性(重点)
Unsigned:
- 无符号的整数
- 该列不能声明为负数
zerofill:
- 0填充的
- 不足的位数,使用0来填充
- 例如:int(5), 11 - 00011
自增:auto_increment
- 自动在上一条记录的基础上+1(默认)
- 通常用来设计唯一的主键,必须是整数类型
- 可以自定义主键自增的起始值和步长
空/非空:null / not null
- 如果设置为not null,那么不给它赋值就会报错
- null,如果不赋值,默认为null
备注: comment
1.4 创建数据库表
create table if not exists student ( -- if not exists 如果不存在就建立这个表
`id` int(5) not null auto_increment comment '学号', -- auto_increment 自增 ,comment 备注
`name` varchar(30) not null default '匿名' comment '姓名', -- default 默认值
`pwd` varchar(30) not null default '123456' comment '密码',
`sex` varchar(10) not null default '男' comment '性别',
`birthday` datetime null comment '生日',
`address` varchar(50) null comment '家庭地址',
primary key (`id`) -- primary key 主键
)engine = INNODB default charset = utf8;
常用命令:
show create database test; -- 展示创建数据库的语句
show create table student; -- 展示创建表的语句
desc student; -- 展示表的结构
1.5 修改删除表
-- 修改表名 alter table 旧表名 rename as 新表名;
alter table student rename as student1;
-- 增加表的字段 alter table 表名 add 字段名 列属性;
alter table student1 add age int(5);
-- 修改表的字段(重命名,修改约束)
-- alter table 表名 modify 字段名 新列属性
alter table student1 modify age varchar(11) -- 可以修改约束,不能重命名
-- alter table 表名 change 旧表名 新表名 新列属性
alter table student1 change age age1 int(4) -- 可以修改约束,也可以重命名
-- 删除表的字段
alter table student1 drop age1
2. MySQL数据管理
2.1 外键
- 建表时添加外键
create table if not exists `grade`
(
`gradeid` int(11) not null auto_increment comment '年级id',
`gradename` varchar(11) not null comment '年级名',
primary key (`gradeid`)
) engine = innodb default charset = utf8;
create table if not exists student
( -- if not exists 如果不存在就建立这个表
`id` int(5) not null auto_increment comment '学号', -- auto_increment 自增 ,comment 备注
`name` varchar(30) not null default '匿名' comment '姓名', -- default 默认值
`pwd` varchar(30) not null default '123456' comment '密码',
`sex` varchar(10) not null default '男' comment '性别',
`gradeid` int(11) not null comment '年级',
`birthday` datetime null comment '生日',
`address` varchar(50) null comment '家庭地址',
primary key (`id`), -- primary key 主键
key `FK_gradeid` (`gradeid`), -- foreign key 外键
constraint `FK_gradeid` foreign key (`gradeid`) references `grade` (`gradeid`)
) engine = INNODB default charset = utf8;
- 创建表的时候没有外键关系
alter table student
add constraint `FK_graded` foreign key (`gradeid`) references `grade` (`gradeid`)
- 删除外键
alter table 表名
drop foreign key 外键名
2.2 DML语言(数据库操作语言)
数据库的意义:数据存储,数据管理
DML语言:
- insert
- update
- delete
2.3 添加insert
-- 插入单条字段
insert into `student` (`id`,`name`,`gradeid`)
values (1992,'张三',1)
-- 插入多条字段
insert into `student` (`id`,`name`,`gradeid`)
values (1994,'李四',2),(1322,'df',4)
2.4 删除
- delete 命令
语法:delete from 表名 [where 条件]
-- 删除数据(避免这么写,会将表中所有数据都删除)
delete form `student`
-- 删除指定数据
delete from `student` where id = 1
- truncate命令
作用:完全清空一个数据库表,但是表的结构和索引不变
-- 清空student表
truncate `student`
- truncate和delete的区别
- truncate 重新设置自增列,计数器会归零
- truncate 不会影响事务
delete删除的问题,重启数据库,现象:
- InnoDB:自增列会从1开始(存在内存中,断电即失)
- MyISAM:继续从上一个自增量开始(存在文件中,不会丢失)
2.3 修改update
update `student` set name = 'gmt' where id = 1992
-- 修改多个属性,逗号隔开
update `student` set name = 'gmt',pwd = '222222',sex = '女' where id = 1992
-- 不指定条件的情况下,会改动所有的字段值,会将表中所有的name值改为gmt
update `student` set name = 'gmt' -- 禁止这么做
操作符
| 符号 | 描述 | 备注 |
|---|---|---|
| = | 等于 | |
| <>, != | 不等于 | |
| > | 大于 | |
| < | 小于 | |
| <= | 小于等于 | |
| >= | 大于等于 | |
| between...and... | 在两值之间 | >=min&&<=max 例如 [2,5] |
| not between...and... | 不在两值之间 | |
| and | && | |
| or | || | |
| in | 在集合中 | |
| not in | 不在集合中 | |
| <=> | 严格比较两个NULL值是否相等 | 两个操作码均为NULL时,其所得值为1;而当一个操作码为NULL时,其所得值为0 |
| like | 模糊匹配 | |
| regexp 或 rlike | 正则式匹配 | |
| is null | 为空 | |
| is not null | 不为空 |
3. DQL查询数据库
select语法
select [ALL | distinct] -- distinct 去重
{* | table.* | [ table.field1 [ as alias1 ] [ ,table.field2 [ as alias2 ] ] [ ... ] ] } -- 不同的字段写法
from table_name [as table_alias] -- as 别名
[left | right | inner join table_name2] --联合查询
[where ...] -- 指定结果需满足的条件
[group by ...] -- 指定结果按照哪几个字段来分组
[having ...] -- 过滤分组的记录必须满足的次要条件
[order by ...] -- 指定查询记录按一个或多个条件排序
[limit {[offset,]row_count | row_countOFFSET offset}] -- 指定记录从哪条到哪条
3.1 查询字段
-- 查询所有字段select * from 表名-- 查询制定字段select 字段名,字段名 from 表名-- 可以给字段起别名 旧名 as 新名,也可以给表起别名 旧表名 as 新表名select `id` as '学号' ,`name` as '姓名' from student as s-- 函数 concat(a,b) 将a添加在b的前面select `id` as '学号' ,concat('姓名:',name) as '姓名' from student
3.2 去重 distinct
select distinct 字段名 from 表名
3.3 模糊查询
| 运算符 | 语法 | 描述 |
|---|---|---|
| like | a like b | sql匹配,如果a匹配b,则结果为真 |
| in | a in (a1,a2,a3...) | 假设a在a1,或者a2...其中的某一个值,则结果为真 |
| is null | a is null | a为空时为真 |
| is not null | a is not null | a不为空时为真 |
- like
%匹配任意数量的字符,甚至零个字符。_完全匹配一个字符。
-- 查询名字中有'王'字的同学-- 这样可以查询出例如'王x'、'x王'、'x王x'等名字select `name`,`id` from `student`where `name` like '%王%'
- in
select `name`,`id` from `student`where `address` in ('北京','上海')
- is null / is not null
-- 查询地址为空的学生select `id`,`name` from `student`where `address` = null or `address` is null-- 查询地址不为空的学生select `id`,`name` from `student`where `address` is not null
3.4 连表查询
| 操作 | 描述 |
|---|---|
| Inner join | 如果表中至少有一个匹配,就返回行 |
| left join | 会从左表中返回所有的值,即是右表中没有匹配 |
| right join | 会从右表中返回所有的值,即是左表中没有匹配 |
在使用left join时,on和where条件的区别如下:
-
on条件是在生成临时表时使用的条件,它不管on中的条件是否为真,都会返回左边表中的记录,还会返回on条件为真的记录
-
where条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有left join的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉。
3.5 自连接
自连接:自己的表和自己的表连接
核心:一张表拆为两张一样的表
父科(parentid为1的科目):
| categoryid | categoryname |
|---|---|
| 2 | 信息技术 |
| 3 | 软件开发 |
| 5 | 美术设计 |
子科:
| parentid | categoryid | categoryname |
|---|---|---|
| 3 | 4 | 数据库 |
| 3 | 6 | web开发 |
| 5 | 7 | ps技术 |
| 2 | 8 | 办公信息 |
总:
| 父类 | 子类 |
|---|---|
| 信息技术 | 办公信息 |
| 软件开发 | 数据库 |
| 软件开发 | web开发 |
| 美术设计 | ps技术 |
-- 建表语言create table `category`( `categoryid` int(10) unsigned not null auto_increment comment '主题', `parentid` int(10) not null comment '父id', `categoryname` varchar(50) not null comment '主题名字', primary key (categoryid)) engine = innodb auto_increment = 9 default charset = utf8-- 插入数据insert into `category` (categoryid, parentid, categoryname)values (2,1,'信息技术'), (3,1,'软件开发'), (4,3,'数据库'), (5,1,'美术设计'), (6,3,'web开发'), (7,5,'ps技术'), (8,2,'办公信息')-- 查询语句select a.categoryname as '父科',b.categoryname as '子科'from category as a,category as bwhere a.categoryid = b.parentid
3.6 分页和排序
- 排序
-- 排序:升序 ASC,降序 DESCselect * from resultorder by grade ASC
- 分页
select * from resultlimit 起始行(0代表第一行数据,1代表第二行数据...),一页多少行数据
4. MySQL函数
4.1 常用函数
-- 数学函数select abs(-9) -- 绝对值select ceiling(9.4) -- 向上取整 10select floor(9.4) -- 向下取整 9select rand() -- 返回一个0~1之间的随机数select sign(-9) -- 判断一个数的符号:0返回0,正数返回1,负数返回-1-- 字符串函数select char_length('函数') -- 2 计算字符串的长度:1个汉字或者1个数字或者1个字母都算作长度1select length('函数') -- 6 计算字符串的长度:但是1个汉字会算作长度3,1个数字或者字母算作长度1select concat('我','爱','编程') -- 拼接字符串 : 我爱编程select insert('我爱编程helloworld',2,1,'超级热爱') -- 查询,从某个位置开始替换某个长度的字符串。即将'爱'替换为'超级热爱',结果为:我超级热爱编程helloworldselect instr('gmt is handsome!','an') -- 9 返回第一次出现的子串的索引select replace('坚持就能成功坚持就能成功','坚持','努力') -- 努力就能成功努力就能成功 替换出现的指定字符串-- 返回指定的子字符串select substr('xxx说坚持就能成功',5) -- 坚持就能成功 从第5个字符开始,一直截取到末尾select substr('xxx说坚持就能成功',5,2) -- 坚持 从第5个字符开始,截取长度为2的字符串select reverse('吃葡萄不吐葡萄皮') -- 皮萄葡吐不萄葡吃 反转select current_date() -- 获取当前时间(只有年月日)select curdate() -- 获取当前时间(只有年月日)select now() -- 获取当前时间(年月日+时分秒)-- 系统select system_user()select user()select version()
4.2 聚合函数
| 函数名称 | 描述 |
|---|---|
| count() | 计数 |
| sum() | 求和 |
| avg() | 求平均值 |
| max() | 最大值 |
| min() | 最小值 |
select count(1) from result -- 不会忽略字段为Null值的记录select count(*) from result -- 不会忽略字段为Null值的记录select count(`gradename`) from grade -- count(字段) 会忽略所有的字段为null值的记录select name as 姓名,max(grade) as 最高分 from result -- 查最高分select name as 姓名,min(grade) as 最低分 from result -- 查最低分select avg(grade) as 平均分 from result -- 查平均分-- 查询不同课程的平均分,最高分,最低分,并且输出平均分大于80分的课程信息select subjectid as 学科, max(grade) as 最高分,min(grade) as 最低分,avg(grade) as 平均分from resultgroup by subjectidhaving avg(grade) >= 80
where 不能使用聚合函数当做条件
having 可以使用聚合函数当做条件
ps:
- having放在group by 的后面
- group by 后面只能放非聚合函数的列
- where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,条件中不能包含聚组函数,使用where条件显示特定的行。
- having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件显示特定的组,也可以使用多个分组标准进行分组。
4.3 MD5加密(扩展)
MD5信息摘要算法:(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码散列函数,可以产生出一个128位(16字节)的散列值(hash value),用于确保信息传输完整一致。
应用:
- 用于密码管理
- 电子签名
- 垃圾邮件筛选
-- ============测试MD5加密=============create table testmd5 ( id int(4) not null , name varchar(30) not null, pwd varchar(50) not null , primary key (id))engine = innodb default charset = utf8-- 明文密码insert into testmd5values(1,'aaa','123456'),(2,'bbb','123456'),(3,'ccc','123456')-- 加密update testmd5 set pwd = md5(pwd) where id = 1update testmd5 set pwd = md5(pwd) -- 加密全部的密码-- 输入时加密insert into testmd5values(4,'ddd',md5('123456'))-- 如何校验:当用户传递进来的密码,进行md5加密,然后对比加密后的值select * from testmd5 where name = 'ddd' and pwd = md5('123456')
5. 事务
5.1 什么是事务(重点)
-
定义:
事务是访问数据库的一个操作序列,数据库应用系统通过事务集来完成对数据库的存取。
-
ACID原则
-
原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
-
一致性(Consistency)
事务前后数据的完整性必须保持一致。
-
隔离性(Isolation)
事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
-
持久性(Durability)
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响
-
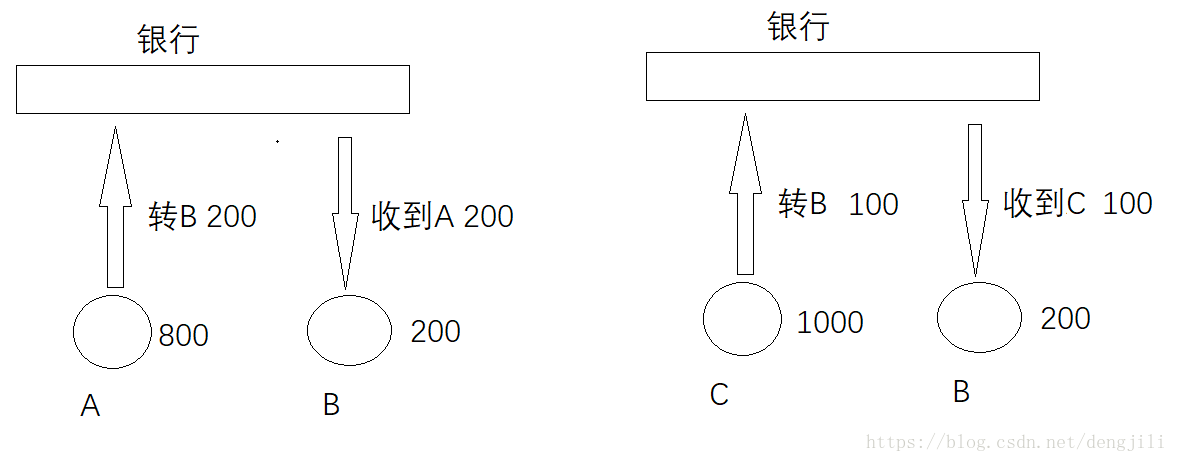
5.1.1 原子性
针对同一个事务
A有800,转给B 200
B有200,收到A 200
A:800 - 200=600
B:200 + 200=400
原子性表示,这两个步骤要么一起成功,要么一起失败,不能只发生其中一个动作。
5.1.2 一致性
针对一个事务操作前与操作后的状态一致
操作前:A:800,B:200
操作后:A:600,B:400
一致性表示事务完成后,符合逻辑运算。
5.1.3 持久性
表示事务结束后的数据不随外界原因导致数据丢失。
操作前:A:800,B:200
操作后:A:600,B:400
如果在操作前(事务还没有提交)服务器宕机或者断电,那么重启数据库以后,数据状态应该为A:800,B:200
如果在操作后(事务已经提交)服务器宕机或者断电,那么重启数据库以后,数据状态应该为A:600,B:400
5.1.4 隔离性
针对多个用户同时操作,主要是排除其他事务对本次事务的影响。
两个事务同时进行,其中一个事务读取到另外一个事务还没有提交的数据

5.1.5 事务的隔离级别
-
脏读:
A事务读取B事务尚未提交的数据并在此基础上操作,而B事务执行回滚,那么A读取到的数据就是脏数据。
时间 转账事务A 取款事务B T1 开始事务 T2 开始事务 T3 查询余额为1000元 T4 取出500元,余额修改为500元 T5 查询账户余额为 500 元(脏读) T6 撤销事务余额恢复为 1000 元 T7 汇入 100 元把余额修改为 600元 T8 提交事务 -
不可重复读
事务A重新读取前面读取过的数据,发现该数据已经被另一个已提交的事务B修改过了。
| 时间 | 转账事务A | 取款事务B |
|---|---|---|
| T1 | 开始事务 | |
| T2 | 开始事务 | |
| T3 | 查询余额为1000元 | |
| T4 | 查询余额为1000元 | |
| T5 | 取出100元,余额修改为900元 | |
| T6 | 提交事务 | |
| T7 | 查询余额为900元(不可重复读) |
- 幻读(虚读)
事务A重新执行一个查询,返回一系列符合查询条件的行,发现其中插入了被事务B提交的行。
是指在一个事务内读取到了别的事务插入的数据,导致前后读取不一致。(一般是行影响,多了一行)
| 时间 | 统计金额事务A | 转账事务B |
|---|---|---|
| T1 | 开始事务 | |
| T2 | 开始事务 | |
| T3 | 查询余额为1000元 | |
| T4 | 新增一个存款账户,并存入100元 | |
| T5 | 提交事务 | |
| T6 | 再次统计总存款为1100元,多了一个账户(幻读) |
- 第一类丢失更新
事务A撤销时,把已经提交的事务B的更新数据覆盖了
| 时间 | 转账事务A | 取款事务B |
|---|---|---|
| T1 | 开始事务 | |
| T2 | 开始事务 | |
| T3 | 查询余额为1000元 | |
| T4 | 查询余额为1000元 | |
| T5 | 汇入100元修改余额为1100元 | |
| T6 | 提交事务 | |
| T7 | 取出 100 元把余额修改为 900元 | |
| T8 | 撤销事务 | |
| T9 | 余额恢复为1000元(丢失更新) |
- 第二类丢失更新
事务A覆盖事务B已经提交的数据,造成事务B所做的操作丢失。
| 时间 | 转账事务A | 取款事务B |
|---|---|---|
| T1 | 开始事务 | |
| T2 | 开始事务 | |
| T3 | 查询余额为1000元 | |
| T4 | 查询余额为1000元 | |
| T5 | 汇入100元修改余额为1100元 | |
| T6 | 提交事务 | |
| T7 | 汇入 100 元把余额修改为 1100元 | |
| T8 | 提交事务 | |
| T9 | 查询余额为1100元(丢失更新) |
5.2 事务
-- ============== 事务 ==============-- mysql是默认开启事务自动提交的set autocommit = 0 -- 关闭自动提交set autocommit = 1 -- 开启自动提交-- 手动处理事务的流程-- 事务开启start transaction -- 标记一个事务的开始,从这个之后的sql语句都在同一个事务内-- sql语句-- 事务结束set autocommit = 1-- 扩展savepoint 保存点名 -- 设置一个事务的保存点rollback to savepoint 保存点名 -- 回滚到保存点release savepoint 保存点名 -- 撤销保存点
5.3 测试事务
-- ============= 测试事务 =================create database bankcreate table `account`( `id` int(3) not null auto_increment, `name` varchar(30) not null, `money` decimal(6, 2) not null, -- decimal(a,b) a表示一共多少位数字,b表示最后两位数是小数 -- 比如decimal(6,2) ,那么数字最大就是9999.99 primary key (`id`))engine = innodb default charset = utf8insert into account(`name`,`money`)values ('AAA',1000.00),('BBB',500.00)-- 模拟转账,事务set autocommit = 0 -- 关闭自动提交start transaction -- 开始一个事务update account set money = money - 500 where name = 'AAA' -- A 减500update account set money = money + 500 where name = 'BBB' -- B 加500commit ; -- 提交事务rollback; -- 回滚set autocommit = 1 -- 开启自动提交
6. 索引
6.1 什么是索引?
索引:是数据库中专门用于帮助用户快速查询数据的一种数据结构。类似于字典中的目录,查找字典内容时可以根据目录查找到数据的存放位置,然后直接获取即可。
6.2 索引分类
- 普通索引(key/index):仅加速查询
- 唯一索引(unique key):加速查询 + 列值唯一(可以有null)
- 主键索引(primary key):加速查询 + 列值唯一 +表中只有一个(不可以有null)
- 组合索引:多列值组成一个索引,
专门用于组合搜索,其效率大于索引合并 - 全文索引(fulltext):对文本的内容进行分词,进行搜索
索引合并,使用多个单列索引组合搜索
覆盖索引,select的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖
6.3 设计索引的原则(重点)
-
搜索的索引列,不一定是所要选择的列。换句话说,最适合索引的列是出现在where子句中的列,或连接子句中指定的列,而不是出现在select关键字后的选择列表的列。
-
使用唯一索引。考虑某列中值的分布,索引的列的基数越大,索引的效果越好。例如存放出生日期的列具有不同值,很容易区分各行。而用来记录性别的列,只含有“M”和“F”,则对此列进行索引没有多大用处,因为不管搜索哪个值,都会得出大约一半的行。
-
使用短索引。如果对字符串列进行索引,应该指定一个前缀长度,只要有可能就应该这样做。例如,有一个CHAR(200)列,如果在前10或20个字符内,多数值是唯一的,那么就不要对整个列进行索引。对前10个或者前20字符进行索引能够节省大量索引空间,也可能会使查询更快。较小的索引涉及的磁盘IO较少,较短的值比较起来更快。更为重要的是,对于较短的键值,索引高速缓存中的块能容纳更多的键值,因此,MySQL也可以在内存中容纳更多的值。这样就增加了找到行而不用读取索引中较多块的可能性。
-
使用最左索引。在创建一个n列的索引时,实际是穿件了MySQL可利用的n个索引。多列索引可起几个索引的作用,因为可利用索引中最左边的列集来匹配行。这样的列集成为最左列集。
-
不要过度索引。每个索引都要占用额外的磁盘空间,并降低写操作的性能。在修改表的内容时,索引必须进行更新,有时可能需要重构,因此,索引越多,所花的时间越长。如果有一个索引很少利用或从不使用,那么会不必要的减缓表的修改速度。此外,MySQL在生成一个执行计划时,要考虑各个索引,这也要花费时间。创建多余的索引给查询优化带来了更多的工作。索引太多,也可能使MySQL选择不到所要使用的最好的索引。只保持所需的索引有利于查询优化。
-
对于InnoDB存储引擎的表,记录默认会按照一定的顺序保存。
- 如果有明确定义的主键,则按照主键顺序保存。
- 如果没有主键,但是有唯一索引,呢么就是按照唯一索引的顺序保存。
- 如果没有主键也没有唯一索引,那么表中会自动生成一个内部列,按照这个列的顺序保存。
按照主键或者内部列进行的访问是最快的,所以InnoDB表尽量自己指定主键,当表中同时有几个列都是唯一的,都可以作为主键的时候,要选择最常作为访问条件的列作为主键,提高查询的效率。另外,还需注意,InnoDB表的普通索引都会保存主键的键值,所以主键要尽可能选择较短的数据类型,可以有效减少索引的磁盘占用,提高索引的缓存效果。
7. 权限管理和备份
7.1 权限管理
-- =========== 权限 =============-- 修改密码(修改当前用户密码)set password = password ('123456')-- 修改密码(修改指定用户密码)set password for gmt = password ('123456')-- 重命名rename user gmt to gmt1-- 用户授权 all privileges 全部的权限-- all privileges 除了给别人授权,其他都能干grant all privileges on *.* to gmt-- 查询权限show grants for GMT -- 查看指定用户的权限show grants for root@localhost
7.2 备份
# 使用mysqldump# mysqldump -h 主机 -u 用户名 -p 密码 数据库 表名 > 物理磁盘位置/文件名mysqldump -hlocalhost -uroot -p123456 school student1 student2 > D:/a.sql
8 规范数据库设计
8.1 三大范式
8.1.1 第一范式(1NF)
第一范式(1NF):要求数据库表中的每一列都是不可分割的原子数据项。
举例说明:

在上面的表中,”家庭信息“和”学校信息“列均不满足原子性的要求,故不满足第一范式,调整如下:

可见,调整后的每一列都是不可再分的,因此满足第一范式(1NF);
8.1.2 第二范式(2NF)
第二范式(2NF):在1NF的基础上,非码属性必须完全依赖于候选码(在1NF基础上消除非主属性对主码的部分函数依赖)第二范式需要确保数据库表中的每一列都与主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)
举例说明:

在上图所示的情况中,同一个订单中可能包含不同的产品,因此主键必须是“订单号”和“产品号”联合组成,
但可以发现,产品数量、产品折扣、产品价格与“订单号”和“产品号”都相关,但是订单金额和订单时间仅与“订单号”相关,与“产品号”无关,
这样就不满足第二范式的要求,调整如下,需分成两个表:


8.1.3 第三范式(3NF)
第三范式(3NF):在2NF的基础上,任何非主属性不依赖于其他非主属性(在2NF基础上消除了传递依赖)第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
举例说明:

上表中,所有属性都完全依赖于学号,所以满足第二范式,但是“班主任性别”和“班主任年龄”直接依赖的是“班主任姓名”,
而不是主键“学号”,所以需做如下调整:

这样以来,就满足了第三范式的要求。
9. JDBC
9.1 测试JDBC
public class jdbc { public static void main(String[] args) throws SQLException, ClassNotFoundException { // 加载驱动 Class.forName("com.mysql.jdbc.Driver"); // 固定写法,加载驱动 // 用户信息和url // useUnicode=true 支持中文编码 // characterEncoding=utf8 设定字符集为utf-8 // useSSL=true 使用安全的链接 String url = "jdbc:mysql://121.196.100.240:3306/testjdbc?useUnicode=true&characterEncoding=utf8&useSSL=true"; String username = "testjdbc"; String password = "123456"; //3. 连接成功,数据库对象 Connection connection = DriverManager.getConnection(url, username, password); //4. 执行SQL的对象 Statement statement = connection.createStatement(); //5. 执行SQL的对象去执行SQL,可能会存在结果,查看返回结果 String sql = "select * from users"; ResultSet resultSet = statement.executeQuery(sql); // 返回的结果集封装了全部的查询出来的结果 while(resultSet.next()){ System.out.println("id="+resultSet.getObject("id")); System.out.println("name="+resultSet.getObject("name")); System.out.println("pwd="+resultSet.getObject("pwd")); } //6. 释放连接 resultSet.close(); statement.close(); connection.close(); }}
9.2 statement对象
jdbc中的statement对象用于向数据库发送sql语句,想完成对数据库的增删改查,只需要通过这个对象向数据库发送增删改查语句即可。
Statement对象的executeUpdate方法,用于向数据库发送增、删、改的sql语句,executeUpdate执行完后,将会返回一个整数(即增删改语句导致了数据库几行数据发生了变化)。
Statement.executeQuery方法用于向数据库发送查询语句,executeQuery方法返回代表查询结果的ResultSet对象。
- 添加操作
Statement statement = connection.createStatement();String sql = "insert into users(...) values (...)";int num = statement.executeUpdate(sql);if(num>0){ System.out.println("插入成功");}
- 删除操作
Statement statement = connection.createStatement();String sql = "delete from users where id = 1";int num = statement.executeUpdate(sql);if(num>0){ System.out.println("删除成功");}
- 修改操作
Statement statement = connection.createStatement();String sql = "update users set name = '...' where name = '...'";int num = statement.executeUpdate(sql);if(num>0){ System.out.println("修改成功");}
- 查询操作
Statement statement = connection.createStatement();String sql = "select * from users";ResultSet resultSet = statement.executeQuery(sql);while(resultSet.next()){ // 根据获取列的数据类型,分别调用rs的相应方法映射到java对象中}
9.3 PreparedStatement对象
package com.gmt;import com.gmt.utils.JdbcUtils;import java.sql.Connection;import java.sql.PreparedStatement;import java.sql.SQLException;public class TestPreparedStatement { public static void main(String[] args) { Connection conn = null ; PreparedStatement st = null; try { conn = JdbcUtils.getConnection(); // PreparedStatement和Statement的区别 // PreparedStatement使用?占位符代替参数 String sql = "insert into users(id,name,pwd) values (?,?,?)"; st = conn.prepareStatement(sql); // 预编译sql,先写sql,然后不执行 // 手动给参数赋值 st.setInt(1,555); st.setString(2,"dfsdf"); st.setString(3,"999999"); int i = st.executeUpdate(); if(i>0){ System.out.println("插入成功"); } } catch (SQLException throwables) { throwables.printStackTrace(); } }}
9.4 PrepareStatement和Statement的区别
-
概念上
PrepareStatement会先初始化SQL,先把这个SQL提交到数据库中进行预处理,多次使用可提高效率。
CreateStatement不会初始化,没有预处理,每次都是从0开始执行SQL。
-
变量上
PrepareStatement可以在sql中用?当做占位符代替变量
CreateStatement不支持用? 代替变量,只能在sql中拼接参数
-
功能上
如果想要删除三条数据
对于createStatement,需要写三条语句
String sql = "delete from category where id = 2" ; String sql = "delete from category where id = 3" ; String sql = "delete from category where id = 7" ;而prepareStatement,通过set不同数据只需要生成一次执行计划,可以重复使用
String sql = "delete from category where id = ?" ;-
PreparedStatement是预编译的,对于批量处理可以大大提高效率,也叫JDBC存储过程。
-
使用CreateStatement 对象。在对数据库只执行一次性存取的时侯,用 CreateStatement对象进行处理。PreparedStatement对象的开销比CreateStatement大,对于一次性操作并不会带来额外的好处。
-
createStatement每次执行sql语句,相关数据库都要执行sql语句的编译,preparedstatement是预编译得,preparedstatement支持批处理
-
-
可重复性
对于上面的两段代码而言:CreateStatement必须给定一个值
而PreparedStatement,对象的key,value都可以自己定义,而且大多数情况下这个语句已经被预编译过,因而当其执行时,只需DBMS运行SQL语句,而不必先编译。这种转换实现不必重复SQL语句的句法,而只需更改其中变量的值,便可重新执行SQL语句。
选择PreparedStatement对象与否,在于相同句法的SQL语句是否执行了多次,而且两次之间的差别仅仅是变量的不同。如果仅仅执行了一次的话,它应该和普通的对象毫无差异,体现不出它预编译的优越性。
-
安全性
使用PrepareStatement可以杜绝SQL注入的风险。
简述SQL注入的原理:

那么,使用PreparedStatement为什么可以防止SQL注入呢?
原理,SQL语句在程序运行前已经进行了预编译,在程序运行时第一次操作数据库之前,SQL语句已经被数据库分析和编译,对应的执行计划也会缓存下来,之后数据库就会以参数化的形式进行查询。
其实就是用值代替了?的位置,并且在值的两边加上了单引号,然后再把值当中的所有单引号替换成了斜杠单引号,说白了就是把值当中的所有单引号给转义了!这就达到了防止sql注入的目的。
从根本上讲,其实就是data VS. code的问题,确保data永远是data,不会是可执行的code,就永远的杜绝了SQL注入这种问题。
9.5 事务
package com.gmt;import com.gmt.utils.JdbcUtils;import java.sql.Connection;import java.sql.PreparedStatement;import java.sql.ResultSet;import java.sql.SQLException;public class TestTransaction { public static void main(String[] args) { Connection conn = null; PreparedStatement st = null; ResultSet rs = null; try { conn = JdbcUtils.getConnection(); // 关闭数据库的自动提交功能,自动开启事务 conn.setAutoCommit(false); //A原本1000,减少200块钱,变成800块钱 String sql1 = "update account set money = money-200 where name ='A'"; st = conn.prepareStatement(sql1); st.executeUpdate(); // 模拟失败 // int x = 1/0; //B原本500,增加200块钱,变成700块钱 String sql2 = "update account set money = money+200 where name ='B'"; st = conn.prepareStatement(sql2); st.executeUpdate(); // 业务完毕,提交事务 conn.commit(); System.out.println("成功"); } catch (SQLException throwables) { try { conn.rollback(); // 如果失败则回滚事务 } catch (SQLException e) { e.printStackTrace(); } throwables.printStackTrace(); } finally { JdbcUtils.release(conn,st,rs); } }}

