

DTW
DTW主要是应用在孤立词识别的算法,用来识别一些特定的指令比较好用,这个算法是基于DP(动态规划)的算法基础上发展而来的。这里介绍语音识别就先介绍下语音识别的框架,首先我们要有一个比对的模版声音,然后需要去截取其里面包含真正属于语音的部分,这个要采用一个叫做vad(voice activedetection)语音活动检测的算法,而在vad中间我们最常使用双门限端点检测这种方法,如图所示,我们采用vad判断语音的开始和结束,判断方法就是通过音量的大小做一个阈值判定,在时域上很简单就能判定。
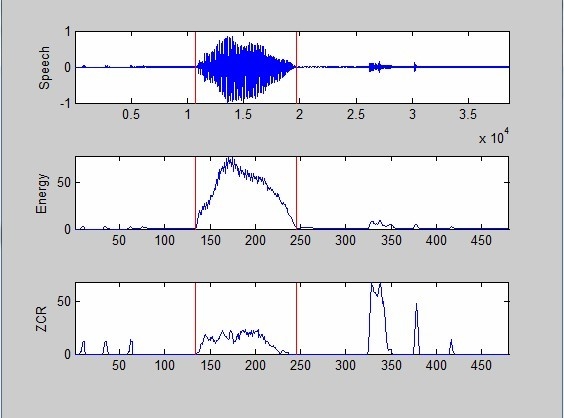
图.speech(语音信号),Energy(短时能量),zcr(短时过零率值)
然后需要寻找一个特征矢量,在语音识别中很多采用MFCC,也就是梅尔倒谱这个参数作为特征矢量。一般的谱分析我们都是采用频谱,或者小波这样与频谱的区别只是不同量度,这些都是解决加性噪声的滤波问题,而还存在倒谱,阶次谱这样是为了特定的需求所构建的另外的谱方法,这些是在NI的探讨会上次说的。倒谱是一种为了滤除乘性噪声的谱方法,简单的说就是对功率谱求log,再反傅里叶变换,公式如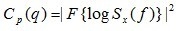 ,这种方法用来做信号分离很有用,下面综合下matlab分析下DTW语音识别。
,这种方法用来做信号分离很有用,下面综合下matlab分析下DTW语音识别。
fname = sprintf('%da.wav',i);
x=fname;
[x,fs]=wavread(x);
[x1 x2] =vad(x);
m = mfcc(x);
m = m(x1-2:x2-2,:);
ref(i).mfcc = m;
首先这里是读取一段语音,通过wavread,然后通过vad函数获取语音的开始于结束部分,这里很多函数都是调用语音应用库voicebox的,获取x1,x2就是语音的两端时候,先对语音信号整体计算mfcc梅尔倒谱,然后截取其中语音部分的作为其函数值。
fname= sprintf('%db.wav',i);
x=fname;
[x,fs]=wavread(x);
[x1 x2] =vad(x);
m = mfcc(x);
m =m(x1-2:x2-2,:);
test(i).mfcc =m;
然后以同样的方法计算需要识别的语音文件其语音段的梅尔倒谱系数,然后对模版与识别文件进行“比对”,这里的比对方法就是DTW算法,我们经常把整个语音识别算法叫做DTW语音识别,但实际上,DTW主要是应用在比对两个梅尔倒谱的比对上,而且这也是一种基于距离的比对,也可以认为是一种基于有导师学习的聚类方法。不过在讲比对之前我们需要讲下匹配,之前图像匹配我们是采用谱分析的方法,而这里属于一维信号的匹配,故解释下相关模板匹配方法。语音识别的匹配需要解决的一个关键问题是说话人对同一个词的两次发音不可能完全相同,这些差异不仅包括音强的大小、频谱的偏移,更重要的是发音时音节的长短不可能完全相同,而且两次发音的音节往往不存在线性对应关系。设参考模板有M帧矢量{R(1),R(2),…R(m),…,R(M)},R(m)为第m帧的语音特征矢量,测试模板有N帧矢量{T(1),T(2),…T(n),…,T(N)},T(n)是第n帧的语音特征矢量。d(T(in),R(im))表示T中第in帧特征与R中im帧特征之间的欧几里得距离。直接匹配是假设测试模板和参考模板长度相等,即in=im;线性时间规整技术假设说话速度是按不同说话单元的发音长度等比例分布的,即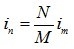 。这两种假设其实都不符合实际语音的发音情况,我们需要一种更加符合实际情况的非线性时间规整技术,也就是DTW算法。
。这两种假设其实都不符合实际语音的发音情况,我们需要一种更加符合实际情况的非线性时间规整技术,也就是DTW算法。
图.三种匹配模式的对比
DTW算法的原理图如图,把测试模板的各个帧号n=1~N在一个二维直角坐标系中的横轴上标出,把参考模板的各帧m=1~M在纵轴上标出,通过这些表示帧号的整数坐标画出一些纵横线即可形成一个网格,网格中的每一个交叉点(ti,rj)表示测试模式中某一帧与训练模式中某一帧的交汇。DTW算法分两步进行,一是计算两个模式各帧之间的距离,即求出帧匹配距离矩阵,二是在帧匹配距离矩阵中找出一条最佳路径。搜索这条路径的过程可以描述如下:搜索从(1,1)点出发,对于局部路径约束如图,点(in,im)可达到的前一个格点只可能是(in-1,im)、(in-1,im-l)和(in-1,im-2)。那么(in,im)一定选择这三个距离中的最小者所对应的点作为其前续格点,这时此路径的累积距离为:
D(in,im)=d(T(in),R(im))+min{D(in-1,im),D(in-1,im-1),D(in-1,im-2)},这样从(l,1)点出发(令D(1,1)=0)搜索,反复递推,直到(N,M)就可以得到最优路径,而且D(N,M)就是最佳匹配路径所对应的匹配距离。在进行语音识别时,将测试模板与所有参考模板进行匹配,得到的最小匹配距离 Dmin(N,M)所对应语音即为识别结果。
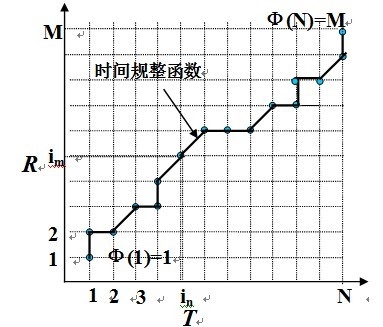
图.DTW算法原理

图.局部约束路径
以下就是matlab对于DTW算法的具体实现:
function dist = dtw(t,r)
n = size(t,1);
m = size(r,1);
%帧匹配距离矩阵
d = zeros(n,m);
for i = 1:n
for j = 1:m
d(i,j) = sum((t(i,:)-r(j,:)).^2);
end
end
%累积距离矩阵
D = ones(n,m) * realmax;
D(1,1) = d(1,1);
%动态规划
for i = 2:n
for j = 1:m
D1 = D(i-1,j);
if j>1
D2 = D(i-1,j-1);
else
D2 = realmax;
end
if j>2
D3 = D(i-1,j-2);
else
D3 = realmax;
end
D(i,j) = d(i,j) + min([D1,D2,D3]);
end
end
dist = D(n,m);

图.DTW语音识别算法测试结果
最终测试结果如图,我们可以完成特定孤立词的识别,其实这种局部优化的想法还有很多地方被使用到,如N皇后的解法上,我们可以采用的比较快速的方法中就有局部搜索法。在语音识别我们除了梅尔倒谱还可以采用LPC(Linear Prediction Coefficient,线性预测系数)推导出的LPCC(LinearPrediction Cepstrum Coefficient,线性预测倒谱系数),但是据说其对辅音结果差,对元音结果好,以上介绍的DTW算法实际上也是在英语的识别率上比较高,实际上英语的识别应该要比汉语简单,在话语识别技术上,我们还需要考虑语音合成技术等一系列如何组成一段语音的方法,才能够方便实现。
