编译原理复习总结(精华版)
本文创作过程中参考了网上多篇文章,如有侵权,请联系作者删除
笔记分两部分:
——第一部分是一些小知识点
——第二部分对应了几个大题的解题模板
第一部分
这部分没什么体系,比较零碎,只记录了我感觉比较重要的部分知识点,大部分是一些容易混淆知识点的辨析
- 二义文法:对一部文法,如果至少存在一个句子,有两棵不同语法树,称该句子是二义性的,包含二义性的句子的文法称为二义文法。上下文无关文法是否具有二义性是不可判定的。但有些特殊的2型文法[例如LL(1)、LR(0)、LR(1)等文法]是先天无二义性的
- NFA和DFA的主要区别在于:1)DFA没有输入空串之上的转换动作。2)对于DFA,一个特定的符号输入,有且只能得到一个状态,而NFA就有可能得到一个状态集。DFA:只有唯一初态。NFA:有初态集。DFA是NFA的特例。
- 分析方法分两大类:自上而下分析法和自下而上分析法 即推导与归约,最右推导是规范推导,逆过程为规范规约
自上而下语法分析是从G的开始符号S出发,通过反复使用产生式句型中的非终结符进行替换,逐步推导出源程序串,是一种产生的方法,面向目标的方法
自下而上语法分析从输入串开始不断寻找子串与文法G中某个产生式P的候选式进行匹配,并用P的左部代替之,逐步归约到S,是一种辨认的方法,基于目标的方法 - 短语,直接短语,句柄,素短语,最左素短语:(这里给出在语法树上的直观区别方法)
—短语:在语法树中表示所有分支结点对应子树,短语即子树叶子对应的符号。注: 子树包括语法树本身,及句型本身也可以称为短语
—直接短语:在语法树中表示为该短语只有上下相邻父子两代
—句柄:最左直接短语
—素短语:指一个短语至少包含一个终结符,并且除它自身之外不再包含其他素短语
—最左素短语:最左素短语就是句型最左边的素短语,是算符优先分析法的规约对象
例如:G[T]:
T → TF|F
F → F↑P|P
P → (T)|i
求给定句型:TP↑(T*F)的短语,直接短语,句柄,素短语,最左素短语
步骤:
1.根据产生式做推导
2.根据推导画出语法树
3.根据语法树和以上规则得答案—短语 5 个 P,T* F,(T* F),P↑(T* F),TP↑(T F)
—直接短语 2 个 P,T* F
—句柄 P
—素短语 T* F
—最左素短语 T* F
-
关于:LR(0)、SLR、LR、LALR
—区别:
—判断方法: -
翻译程序、编译程序、解释程序
翻译程序:将用某种语言编写的程序转换成另一种语言形式的程序的程序
编译程序:用高级语言编写的源程序转换(加工)成与之等价的另一种用低级语言编写的目标程序的翻译程序。
解释程序:解释程序是高级语言翻译程序的一种,他将输入的源程序作为输入,解释一句后就提交给计算机执行一句,源程序命令被逐个直接解释执行 -
算符文法与算符优先文法:
算符文法:任一产生式的右部都不含两个连续非终结符的文法
算符优先文法:是不含空字符且对任一对终结符都有确定的><=关系的算符文法 -
字母表:元素的非空有穷集合
符号:字母表中的元素
符号串:字母表中符号组成的有穷序列 -
句子、句型、语言
句型是由识别符Z推导而得的符号串
句子是没有非终结符号的句型
语言是句子的集合 -
中间代码形式:常见的有逆波兰记号、三元式、四元式和树
1.逆波兰(也称后缀表示):没有括号,易于计算机处理
2.三元式(运算符,对象1,对象2):不便于优化但间接三元式,可以克服这个缺点
3.树形表示 三元式表示也可用相应的树形表示
4.四元式:(运算符; 对象1,对象2, 结果):有利于代码优化
第二部分
这部分对应几个大题的内容,每个部分也都可以通过编程来实现
一:根据正则表达式写出对应的最小化的DFA
1.正则表达式转NFA:(语法制导)
2.NFA确定化(转DFA):(子集法)
首先了解两种运算:
- ε-closure(I):定义为一个状态集,是状态集I中的任何状态S经任意条 ε弧能够到达的状态的集合。
- move(I,a):定义为状态集合J,其中J是所有那些可以从I中某一状态经过一条a弧到达的状态的全体。
子集法步骤:
1.做一张表:
3.DFA最小化(化简):(分割法)
第一步:消除无用状态:
无用状态:
- 不可达,孤立的点 即任何输入都不可到达。
- 无法到达终态的状态
对于无用状态,可以非常简单的消去。
第二步:合并等价状态(分割法):
等价状态:
- 来源一致:必须同时为可接受或者不可接受状态
- 去向一致:对所有的输入必须转换到等价的状态里面
分割法步骤
- 1.首先将M的状态分为两个子集:一个由终态(可接受态)组成,另一个由非终态(包含初态)组成。
- 2.观察每个子集中的状态读取不同符号后,会不会转换到不同子集中的状态(去向不一致说明不等价)若能则将该子集分割成新的小的子集(按照去向的不同)
- 3.重复2,直至所有子集中的状态接收任何符号都无法再做分割为止,此时每个集合内部的状态都是等价的,将其合并并改写DFA即可。
下面是一个例题
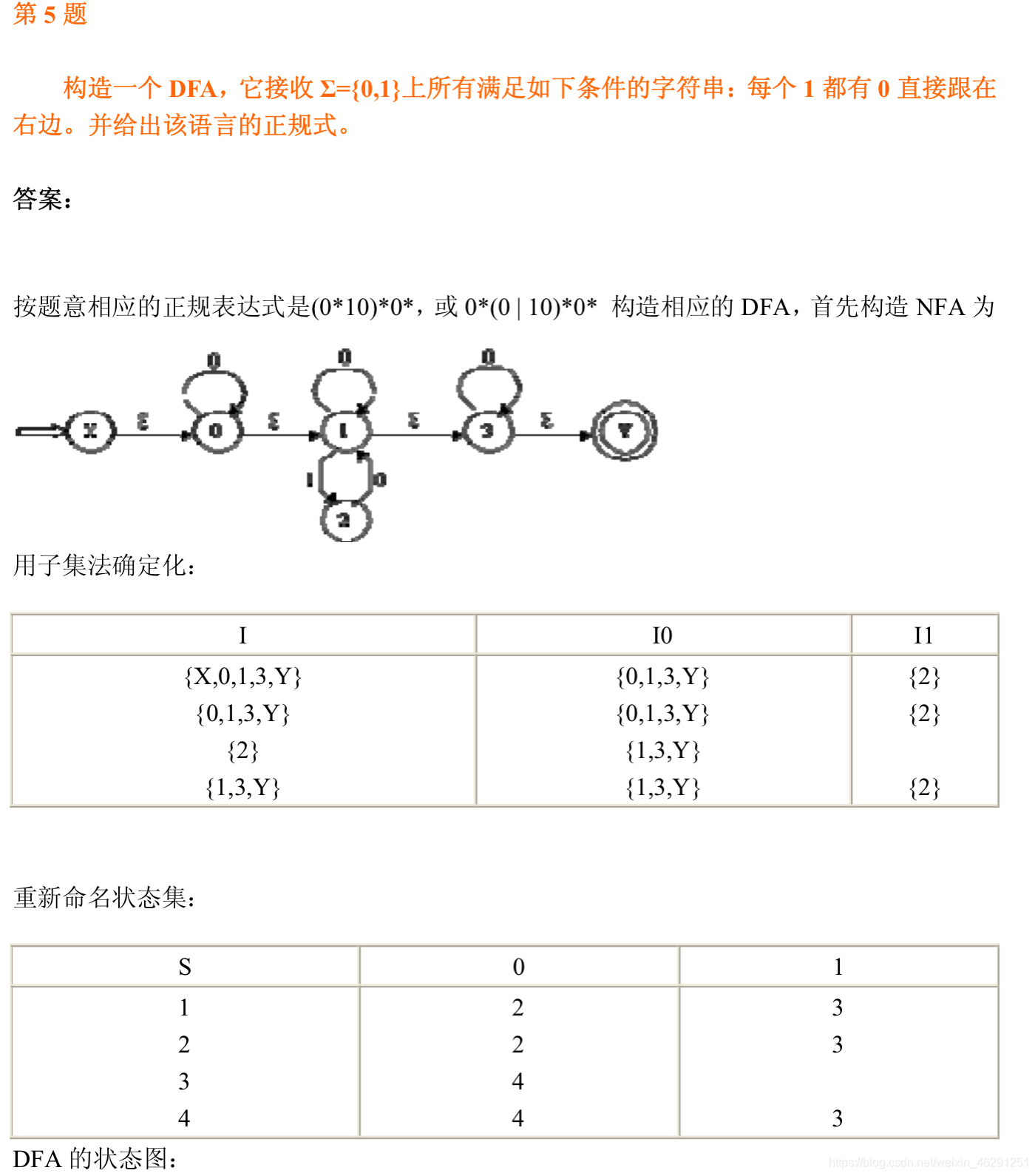
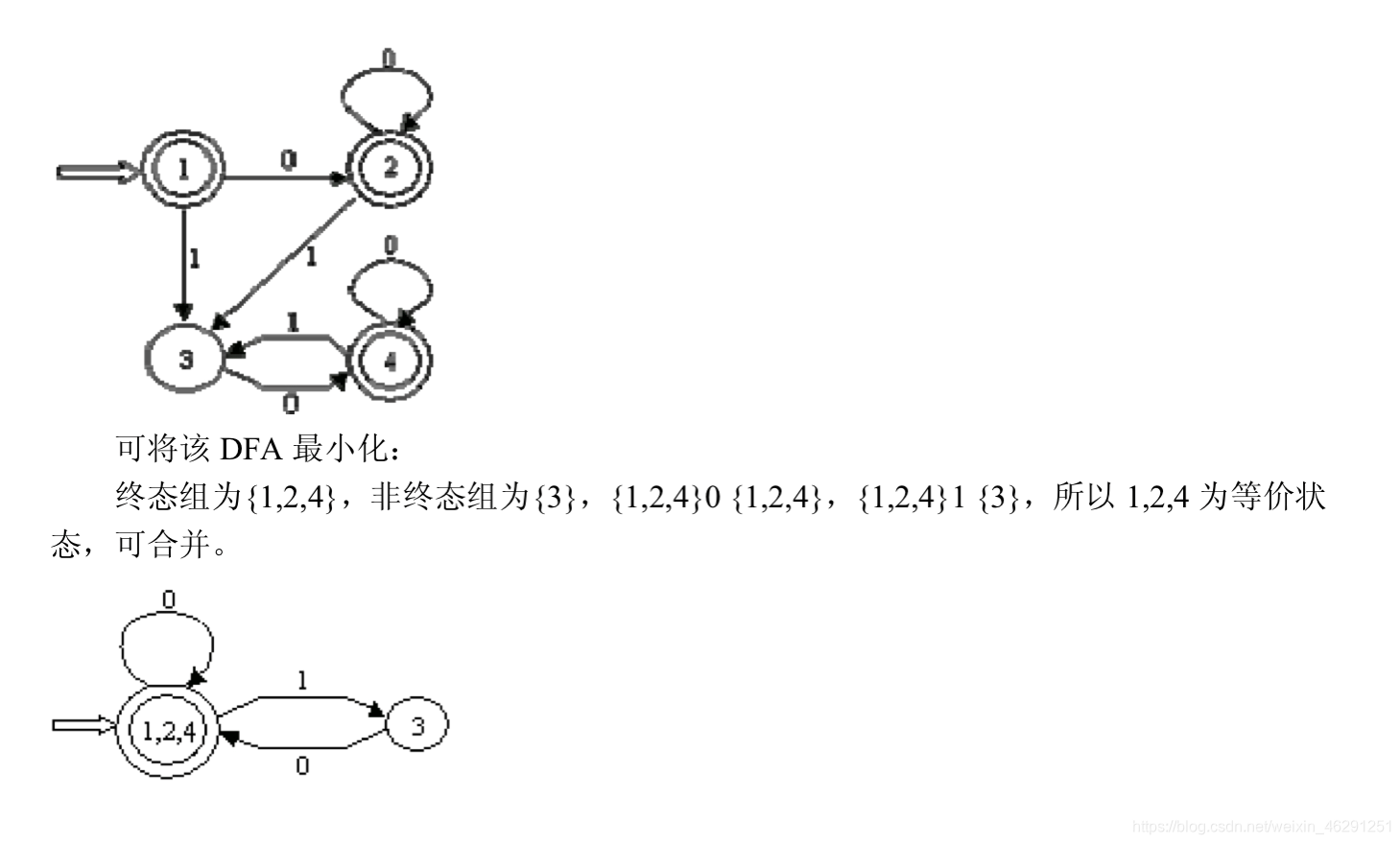
二:判断给定文法是不是LL(1)的,若是,则给出预测分析表并给出识别输入串的过程。
1.消除左递归
- 第一步:将间接左递归变为直接左递归
方法:类似中学用过的带入消元法,即通过产生式非终结符的替换,将将间接左递归变为直接左递归。 - 注意实际操作时需要指定一定的替换顺序
- 第二步:消除直接左递归
方法:直接左递归的形式为:A→A α1 |A α 2 |…|A α m |β 1 |β 2 |…|β n
消除左递归后改写为:
A→β 1 A’|β 2 A’|…| β n A’
A’→ α 1 A’| α 2 A’ | … | α m A’ | ε - 例如:

2.求出SELECT(需先求FIRST、FOLLOW)
First(A)的含义指每个候选式的终结首符集;Follow(A)的含义指在文法G的一切句型中能够紧跟着A之后的一切终结符或#
求非终结符表
求FIRST
- 求非终结符A的FIRST集:检查每一个可以由A推出的产生式
- 若产生式由终结符m开头(例如A ->m),则直接将此非终结符m加入FIRST(A)集
- 若由非终结符B开头(例如A ->BC),则再判断此非终结符B能推出空字符 ε
– 若不能:将此终结符B的FIRST(B)集合整体加入FIRST(A)集
– 若能:则将B的FIRST(B)集合整体除去 ε 加入FIRST(A)集,然后再次向处理B一样处理B之后的符号(这里是C)(相当于A吸收B中的空字符到达下一个符号)。
求FOLLOW
- 求非终结符A的FOLLOW集:检查每一个可以推出A的产生式
- 若A为文法的开始符号:将 # 加入FOLLOW(A)
- 若A为当前产生式的最后一个字符(例如B ->CA):将FOLLOW(B)加入FOLLOW(A)
- 若A后面还有其它字符例如(例如B->AD):
– 如果D不能推出空字符 ε:将FIRST(D)加入FOLLOW(A)
– 如果D能够推出空字符 ε:将FIRST(D)减去 ε 加入FOLLOW(A)并且将FOLLOW(B)加入FOLLOW(A)
求SELECT
- SELECT ( A→α) =FIRST ( α ),其中α !⇒ ε
若α ⇒ε ,则SELECT ( A→α) = (FIRST(α ) - {ε ) ∪FOLLOW(A) - 注意α在这里的是一个产生式,而不是一个符号
3.判断是否是LL(1)
- 对每个非终结符A的两个不同产生式,A→α ,A→β ,
- 满足SELECTC(A→α )∩SELECT(A→β )= ϕ
- 其中α、β不能同时⇒ ε
- 则称该文法是LL(1)的
4.构造预测分析表
预测分析表M 如下矩阵形式:矩阵M
•行标题用文法的非终结符表示。
•列标题用文法的终结符号和#表示。
•矩阵元素M[A, a]的内容是产生式A→α \alphaα(或→α \alphaα)表明当对A进行推导,面临输入符号a时,应采用候选α \alphaα进行推导。
出错处理标志(即表中空白项)表明A不该面临输入符号a。
5.识别输入串的过程
- 总控程序:分析栈【存放分析过程中的文法符号】,分析表
总是按栈顶符号x和当前输入符号行事。 - 对于任何(x,a),总控程序每次都执行下述三种可能动作之一:
(a)若x=a=‘#’,则宣布分析成功。
(b)若x=a≠ ‘#’,则把x从栈顶逐出,指针指向下一输入符号。
(c)若x是一个非终结符,则查看分析表M。
①如果M[A, a]中存放关于X的一个产生式,那么,首先把X顶出栈,然后把产生式右部符号串按反序一一推进栈。
②如果M[A, a]中存放“出错标志”,则调用出错处理程序ERROR。
下面是一个例题
消除左递归

求FIRST、FOLLOW、SELECT并判断

构造预测分析表

识别输入串

三:构造给定文法的拓广文法的LR(0)项目集规范族,并给出识别活前缀的DFA,判断文法是LR(0),SLR(1),LALR(1)还是LR(1)的,构造相应的分析表。
构造拓广文法
加个S’的规则就行。
S’->E
E->aA | bB
A->cA | d
B->cB | d
构造LR(0)项目集规范族
求文法的所有项目
给每个规则加一个点以后然后挪位置,挪一个位置就得到一个项目
1.S’->·E 2.S’->E· 3.E->·aA 4.E->a·A 5.E->aA· 6.A->·cA 7.A->c·A 8.A->cA· 9.A->·d
10.A->d· 11.E->·bB 12.E->b·B 13.E->bB· 14.B->·cB 15.B->c·B 16.B->cB· 17.B->·d 18.B->d·
项目集规范族
把有S’的项目而且点在最左边的项目作为状态I0的核,放在开头。
S’->·E
E->·aA
E->·bB
然后看这个点后面的非终结符,是个E,接下来就去项目中找左部是E的而且点在最左边开头位置的项目,列在核的下面,这就是状态I0了,你可以画个框框然后标记一下。
接下来还是先看核里面点后的这个非终结符E,输入E(你可以理解为在箭弧上标了个E),把点向后移一位,得到S’->E·,这其实是得到了一个新的状态的核。当然另外两个也一样,输入点后面的符号,比如输入a得到E->a·A为核的新状态,输入b得到E->b·B为核的新状态。得到新状态的核了,就顺便把这个状态剩下的项目也列出来吧,就是看核的点后面的非终结符,找以这个非终结符为左部的点在最左边的项目。当然要是点后面没有东西就不用找了,新的状态记得标号哦。
是重复上面的工作,从每一个新状态出发,逐个输入每个项目点后面的符号,就是后移一位,又分别作为新的状态的核然后根据核找下面的同状态里的项目。找到找不动为止

给出识别活前缀的DFA
把文法的所有产生式的项目都列出来,并使每个项目都作为NFA的一个状态。
判断文法类型
- 如果文法对应的自动机中不存在移进-归约冲突和归约-归约冲突则为 LR(0)文法
构造分析表:LR(0)
1、找项目集规范族有S’->A·这种形状的那个状态Ik,就是第k个状态,则把分析表第k行的#列标上acc
2、按顺序(我一般是按状态序号顺序)分析状态的项目和GOTO函数,主要就是看每个项目的点后面的符号。
(1)要是是个终结符,看输入这个终结符后去的哪个状态,比如当前是状态I0,对于第二个项目E->·aA,输入a以后去了状态I2,那就在分析表中第0行的a列写上S2,意思就是状态Ik输入Vt后去了Ij状态。
(2)要是是个非终结符,这个更好理解,比如从状态Ik输入这个非终结符以后去了状态Ij,那就在GOTO表的第k行第Vn列写j。
3、你会发现有的项目的点是在最后,这就是分析表里面那些小r的来历了。先看这个项目所在的状态,再看点前面的规则是文法里面的第几个规则,比如说状态I10的A->d·里面的A->d就是文法的第4条规则,那就在分析表的第10行所有的终结符列包括#列写上r4,就是ACTION列的一行写满。即状态Ik的项目来自于文法的第j条规则,则分析表的第k行都是rj。
四:计算给定文法的FIRETVT和LASTVT,构造算符优先分析表并说明文法是否是算符优先文法。
计算FIRETVT和LASTVT
- FIRSTVT(B) = {b| B=>b… 或 B=>Cb…}
规则:
若B->b… 或 B->Cb… 则b加入FIRSTVT(B)
若B->A… 则FIRSTVT(A) 加入FIRSTVT(B)
- LASTVT(B) = {a| B=>…a 或 B=>…aC}
规则:
若B=>…a 或 B=>…aC 则a加入LASTVT(B)
若B->…A 则LASTVT(A) 加入LASTVT(B)
构造算符优先分析表
-
算符优先分析表M 如下矩阵形式:
•行标题用文法的终结符和#表示。
•列标题用文法的终结符和#表示。
•表中的元素为><=或空四者之一。 -
首先填写表中的=项:
若文法中产生式有满足P->…ab…或P->…aQb…的那么就直接填写=,注意顺序是左边等于右边,对应表是横着的等于竖着的,这里是(=),#号直接填写等于就好了。 -
然后是>和<
找类似于P->QaR这种有用的文法,终结符和非终结符在一起的那种。找到后根据以下两条:
1.a小于FIRSTVT(R)中元素,横着写
2.LASTVT(Q)中元素大于a,竖着写
判断文法是否算符优先文法
判断标准:文法任一产生式右部都不含两个相继的非终结符为算符文法。
方法:利用上述得到的分析表,若两个终结符之间至多满足=,<,>,三种关系之一(一个表格内部只填写一个符号),可以判断该文法为算符优先文法,反之不是。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号