GAN手写体生成(MINIST)
参考教材:人工智能导论(第4版) 王万良 高等教育出版社
实验环境:Python3.7 + Tensor flow 2.1
人工智能导论实验导航
实验一:斑马问题 https://blog.csdn.net/weixin_46291251/article/details/122246347
实验二:图像恢复 https://blog.csdn.net/weixin_46291251/article/details/122561220
实验三:花卉识别 https://blog.csdn.net/weixin_46291251/article/details/122561505
实验四:手写体生成 https://blog.csdn.net/weixin_46291251/article/details/122576478
实验源码: xxx
4.1实验介绍
4.1.1实验背景
深度学习为人工智能核心技术,本章主要围绕深度学习涉及的全连接神经网络、卷积神经网络和对抗神经网络而开设的实验。
生成对抗网络是一种训练生成网络的框架,比如生成图片的深度卷积神经网络。构建一个用来生成图片的GAN模型需要同时具备判别模型和生成模型,判别模型,用来分析一张图片是真实的还是仿造的;生成模型使用反转的卷积层将输入转换为对应像素值的完整二维图像。本实验通过GAN模型的搭建,主要介绍TensorFlow2.0计算的基本流程,以及构建网络的基本要素。
4.1.2实验目的
本章实验的主要目的是掌握深度学习相关基础知识点,了解深度学习相关基础知识,经典全连接神经网络、卷积神经网络和对抗神经网络。掌握不同神经网络架构的设计原理,熟悉使用Tensorflow 2.1深度学习框架实现深度学习实验的一般流程。同时对ModelArts自动学习模块、AI市场有初步认识,对Atlas200DK开发板模型部署相关内容有初步了解。
学习怎么定义和训练一个单独的判别模型,用来学习真假图片之间的不同点
学习怎么定义单独的生成模型,并训练同时具备生成和判别的复合模型
学习怎么评估GAN模型的表现,并使用最终得到的单独的生成模型生成图片
4.1.3实验简介
利用MINIST数据集对构建的GAN网络进行训练,最终使得该网络能够脱离数据集自动生成以假乱真的手写体图像。
4.2概要设计
GAN主要包括了两个部分,即生成器generator与判别器discriminator。生成器主要用来学习真实图像分布从而让自身生成的图像更加真实,以骗过判别器。判别器则需要对接收的图片进行真假判别。在整个过程中,生成器努力地让生成的图像更加真实,而判别器则努力地去识别出图像的真假,这个过程相当于一个二人博弈,随着时间的推移,生成器和判别器在不断地进行对抗,最终两个网络达到了一个动态均衡:生成器生成的图像接近于真实图像分布,而判别器识别不出真假图像,对于给定图像的预测为真的概率基本接近0.5(相当于随机猜测类别)。所以:
对于给定的真实图片(real image),判别器要为其打上标签1;
对于给定的生成图片(fake image),判别器要为其打上标签0;
对于生成器传给辨别器的生成图片,生成器希望辨别器打上标签1。
4.3详细设计
4.3.1 实验数据准备
数据集简介:
1). MNIST数据集来自美国国家标准与技术研究所(National Institute of Standards and
Technology ,简称NIST);
2). 该数据集由来自250个不同人手写的数字构成,其中50%是高中学生,50%来自人口普查局
的工组人员;
3). 数据集可在http://yann.lecun.com/exdb/mnist/ 获取, 它包含了四个部分:
- Training set images: train-images-idx3-ubyte.gz (9.9 MB, 解压后 47 MB, 包含 60,000 个样本)
- Training set labels: train-labels-idx1-ubyte.gz (29 KB, 解压后 60 KB, 包含 60,000 个标签)
- Test set images: t10k-images-idx3-ubyte.gz (1.6 MB, 解压后 7.8 MB, 包含 10,000 个样本)
- Test set labels: t10k-labels-idx1-ubyte.gz (5KB, 解压后 10 KB, 包含 10,000 个标签)
4). mnist是一个入门级的计算机视觉数据集,它包含各种手写数字图片,下图展示了mnist中的一些图片:
数据集加载:
import numpy as np
# ''中为放置mnist.npz的相对路径,改为自己数据集存放的路径
path = r'.\datasets\mnist.npz
f = np.load(path) #加载数据集
trainX = f['x_train'] #训练集数据获取
trainy = f['y_train'] #训练集数据标签获取
testX = f['x_test'] #测试集数据获取
testy = f['y_test'] #测试集数据标签获取
print("Train", trainX.shape, trainy.shape) #查看训练集数据形状及标签形状
print("Test", testX.shape, testy.shape) #查看验证集数据形状及标签形状
输出结果:
Train (60000, 28, 28) (60000,)
Test (10000, 28, 28) (10000,)
可视化训练集前30张图片:
from matplotlib import pyplot #从matplotlib数据库导入pyplot模块
for i in range(30): # 使用range()函数产生0到29这30个数,建立for循环
#使用subplot()构建子图,第一个参数5表示每列有5张图,
第二个参数表示每行有6张图,1+i表示第(1+i张图)
pyplot.subplot(5, 6, 1 + i)
pyplot.axis('off') # 关闭坐标轴("on"为显示坐标轴)
#使用imshow()函数画出训练集相应图片原始像素数据,参数cmap = gray表示黑底白字图像,这边使用"gray_r"表示白底黑字图
pyplot.imshow(trainX[i], cmap='gray_r')
pyplot.show() # 固定写法,展示图片
输出结果:

4.3.2 GAN模型的框架
伪代码如下:
4.3.3导入相关的包
导入所需的包
import numpy as np
from numpy import expand_dims #从numpy库导入expand_dims函数,用于数组增加维度
from numpy import zeros #从numpy库导入zeros函数,用于生成元素都为0的数组
from numpy import ones #从numpy库导入ones函数,用于生成元素都为1的数组
from numpy import vstack #从numpy库导入vstack函数,用于在垂直方向(y轴)堆叠数组
from numpy.random import randn #从numpy.random模块导入randn函数,numpy.random.randn(d0, d1, …, dn)是从标准正态分布中返回一个或多个样本值
from numpy.random import randint #从numpy.random模块导入randint函数,用于生成整数,如np.random.randint(1, 5)是随机生成1,2,3,4这四个整数,注意前闭后开
from keras.datasets.mnist import load_data #从keras.datasets.mnist加载load_data函数,此次实验我们直接从本地加载图片,故不使用这个函数
from tensorflow.keras.optimizers import Adam #从keras.optimizers模块加载Adam优化器,用于训练模型
from tensorflow.keras.models import Sequential #从keras.models库加载Sequentil序贯模型,用于线性堆叠多个网络层
from tensorflow.keras.layers import Dense #从keras.layers库加载Dense层,用于全连接操作
from tensorflow.keras.layers import Reshape #从keras.layers库加载reshape函数,用于将指定的矩阵变换成特定维数矩阵一种函数,且矩阵中元素个数不变,函数可以重新调整矩阵的行数、列数、维数。
from tensorflow.keras.layers import Flatten #从keras.layers库加载Flaten函数,用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flaten不影响batch的大小
from tensorflow.keras.layers import Conv2D #从keras.layers库加载Conv2D函数,用于卷积层操作
from tensorflow.keras.layers import Conv2DTranspose #从keras.layers库加载Conv2DTranspore函数,此函数的操作可以看作Conv2D函数的逆操作
from tensorflow.keras.layers import LeakyReLU #从keras.layers库加载LeakyReLU激活函数
from tensorflow.keras.layers import Dropout #从keras.layers库加载Dropout函数
from matplotlib import pyplot #从matplotlib库加载pyplot函数,用于显示图像
4.3.4 定义判别模型
模型必须从我们的数据集中获取样本图像作为输入,并输出关于样本是真实还是假的分类预测。
这是一个二进制分类问题:输入:一个通道的图像,尺寸为28×28像素。 输出:二进制分类,样本是真实的(或假的)。
def define_discriminator(in_shape=(28,28,1)): #定义判别模型,输入大小为(28,28,1)
model = Sequential() #构造序列模型Sequential()
model.add(Conv2D(64, (3,3), strides=(2, 2), padding='same', input_shape=in_shape)) # 使用add()函数添加卷积层,Conv2D()添加卷积层,这里我们使用64个卷积核,卷积核大小3*3,步长为2,padding="same"保持输出图像不变
model.add(LeakyReLU(alpha=0.2)) #添加LeakyReLU()函数,在自变量小于0的部分,使用斜率0.2
model.add(Dropout(0.4)) #添加Dropout()函数,当前dropout比率为0.4,即如果某一层有1000个神经元,那经过dropout后,大约有400个值被置为0
model.add(Conv2D(64, (3,3), strides=(2, 2), padding='same')) #添加第二层卷积层,同第一层
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.4))
model.add(Flatten()) #添加Flaten层,将卷积层的多维数据一维化,卷积层到全连接层的过渡。
model.add(Dense(1, activation='sigmoid')) #添加Dense层,即全连接层,输出节点数为1,这里使用sidmoid()激活函数
# 编译模型
opt = Adam(lr=0.0002, beta_1=0.5) #使用Adam激活函数,lr为学习率,值越大则表示权值调整动作越大,这里为0.0002;beta_1: (有偏)一阶矩估计的指数衰减因子,这里为0.5,用于动态调整每个参数的学习率
model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['accuracy']) #使用compile()函数定义损失函数,这里使用'binary_crossentropy'二元交叉熵损失函数;定义优化器及评价指标
return model
4.3.5定义生成模型
生成器模型负责创建手写数字的新的,假的但合理的图像。它通过从潜在空间中获取一个点作为输入并输出正方形灰度图像来实现此目的。
潜在空间是高斯分布值(例如100维)的任意定义的向量空间。它没有任何意义,但是通过在训练过程中从该空间中随机抽取点并将其提供给生成器模型,生成器模型将为潜点以及潜在空间分配含义,直到训练结束,潜矢量空间表示输出空间的MNIST图像的压缩表示,只有生成器才知道如何转换为看似可行的MNIST图像。
输入:潜在空间中的点,例如随机的一个服从高斯分布的100维向量。 输出:28×28像素的二维正方形灰度图像,像素值范围[0,1]。 注意:我们不必非要使用100元素向量作为输入;它是一个整数并且被广泛使用,但是我们也同样可以去尝试10、50或500维的空间。
开发生成器模型要求我们将向量从具有100个维度的潜在空间转换为具有28×28或784个值的2D数组。
def define_generator(latent_dim):
model = Sequential()
#定义网络所需节点数,输出图像的低分辨率图像大小7*7,
128可以理解为用这么多低分辨率图片代表输出图片
n_nodes = 128 * 7 * 7
model.add(Dense(n_nodes, input_dim=latent_dim)) #添加潜在空间到节点的全连接层
model.add(LeakyReLU(alpha=0.2))
#使用reshape()函数改变向量维度,使数据能像图像那样作为卷积层的输入
model.add(Reshape((7, 7, 128)))
#添加反卷积层,卷积核大小4*4,步长为2,使用padding使得最终结果为14*14的featuremap
model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding='same'))
model.add(LeakyReLU(alpha=0.2))
#同上一层反卷积层,将特征图从14*14转化为28*28
model.add(Conv2DTranspose(128, (4,4), strides=(2,2), padding='same'))
model.add(LeakyReLU(alpha=0.2))
model.add(Conv2D(1, (7,7), activation='sigmoid', padding='same')) #使用普通卷积层最终得到一张特征图,使用sigmoid激活函数,使用"same"保持图片大小不变,28*28
return model
4.3.6 定义GAN网络
生成器模型中的权重将根据区分器模型的性能进行更新。当鉴别器善于检测假样本时,生成器会更新得更多;而当鉴别器模型相对较差或在检测假样本时会混淆时,生成器模型的更新会更少。这定义了这两个模型之间的零和或对抗关系。
我们采用一种较为简单的方法创建一个结合生成器模型和鉴别器模型的新模型。确切地说,我们不是在谈论或是创建新的第三个模型,而是一个新的逻辑模型(GAN模型),该模型使用独立生成器和鉴别器模型中已经定义的层和权重。
生成器模型仅与鉴别器在假示例中的表现有关。因此,当鉴别器中的所有层是GAN模型的一部分时,我们都将其标记为不可训练,这样就不会在伪造的示例上对它们进行更新和过度训练。
通过此逻辑GAN模型训练生成器时,还有一个更重要的变化。我们希望判别器认为生成器输出的样本是真实的,而不是假的。因此,当将生成器训练为GAN模型的一部分时,我们会将生成的样本标记为真实。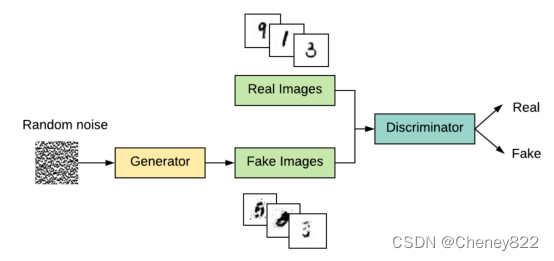
def define_gan(g_model, d_model): # 定义gan模型,使用g_model和d_model作为参数
d_model.trainable = False # 设置使判别模型的参数不发生改变
model = Sequential() #定义 Sequential()模型
model.add(g_model) # 添加生成器
model.add(d_model) # 添加判别器
opt = Adam(lr=0.0002, beta_1=0.5) # Adam优化器
model.compile(loss='binary_crossentropy', optimizer=opt) #定义损失函数,优化器
return model
4.3.7 生成真实样本
从MINIST数据集加载图片数据,并赋予标签
#定义函数,dataset:数据集,n_samples:每个batch的样本数
def generate_real_samples(dataset, n_samples):
# 使用randint()函数从[0,dataset.shape[0]]选择任意n_samples个整数作为索引
ix = randint(0, dataset.shape[0], n_samples)
X = dataset[ix] # 根据索引从dataset中获取相应的图片
# 使用ones()函数生成n_samples个真实标签(一维向量),真实样本标签数值为1
y = ones((n_samples, 1))
return X, y
从潜在空间生成点作为生成模型的输入
#定义函数,参数latent_dim:潜在空间的维度;n_samples:生成的样本数
def generate_latent_points(latent_dim, n_samples):
x_input = randn(latent_dim * n_samples) #在潜在空间生成样本点
x_input = x_input.reshape(n_samples, latent_dim) #使用reshape()方法转化为网络的输入
return x_input
使用生成模型生成虚假样本
#参数g_model:生成模型; latent_dim:潜在空间维度; n_samples:样本数
def generate_fake_samples(g_model, latent_dim, n_samples):
x_input = generate_latent_points(latent_dim, n_samples) # 在潜在空间生成样本点
X = g_model.predict(x_input) # 将生成模型的预测结果作为生成的虚假样本
y = zeros((n_samples, 1)) # 生成虚假样本的标签(一维向量),虚假样本标签数值为0
return X, y
保存生成的图片
#参数examples:生成的样本;epoch:一个epoch就是将所有训练样本训练一次的过程;
n:子图列或宽的数量
def save_plot(examples, epoch, n=10):
for i in range(n * n):
pyplot.subplot(n, n, 1 + i) #定义子图,子图每列n张图片,每行n张图片,当前为第(1+n)张图片
pyplot.axis('off') # 关闭坐标
# 画出原始像素值,examples[i, :, :, 0]获取第i张图片的像素点
pyplot.imshow(examples[i, :, :, 0], cmap='gray_r')
filename = 'generated_plot_e%03d.png' % (epoch+1) # 设置文件名,跟epoch相关
pyplot.savefig(filename) # 使用pyplot.savefig()函数将图像保存至文件夹
pyplot.close()
4.3.8 训练模型
在GAN模型中,生成器模型和判别器模型会被同时训练,在同一步训练过程中,分为两个过程,首先,我们会使用一半批次数量的真实样本+一般批次数量的生成样本(由生成模型生成,标签为0)训练判别模型;然后会生成一个批次的生成模型(由生成模型生成,标签为1)训练GAN模型。
GAN的训练分为如下几个步骤:
- 1、随机选取batch_size个真实的图片。
- 2、随机生成batch_size个N维向量,传入到Generator中生成batch_size个虚假图片。
- 3、将真实图片和虚假图片当作训练集传入到Discriminator中进行训练(真实图片的label为1,虚假图片的label为0)。
- 4、将虚假图片的Discriminator预测结果与1的对比作为loss对Generator进行训练(与1对比的意思是,如果Discriminator将虚假图片判断为1,说明这个生成的图片很“真实”)。
实验中:总的样本集训练过程n_epochs=100,每个step参与训练的样本数n_batch=256。每隔10个epoch评估判别模型表现,保存生成的图片及相应的生成模型
4.4运行测试
第一次迭代后

第三次迭代后

第六次迭代后

最终第十次迭代后

从以上生成的手写图片可知,随着训练的不断迭代,生成的效果也越来越好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号