【面向对象】第一单元总结
一、基于度量的程序分析
本次作业中第一次了解到对软件复杂度的度量分析,首先先谈一谈自己对将要用到的各个指标的含义的理解。
Dependency Metrics (依赖关系分析)中:
Cyclic:和该类有循环依赖关系的数目。
Dcy:该类直接依赖的类数目。
Dpt:直接依赖该类的类数目。
Complexity Metrics (复杂度分析)中:
methods中:
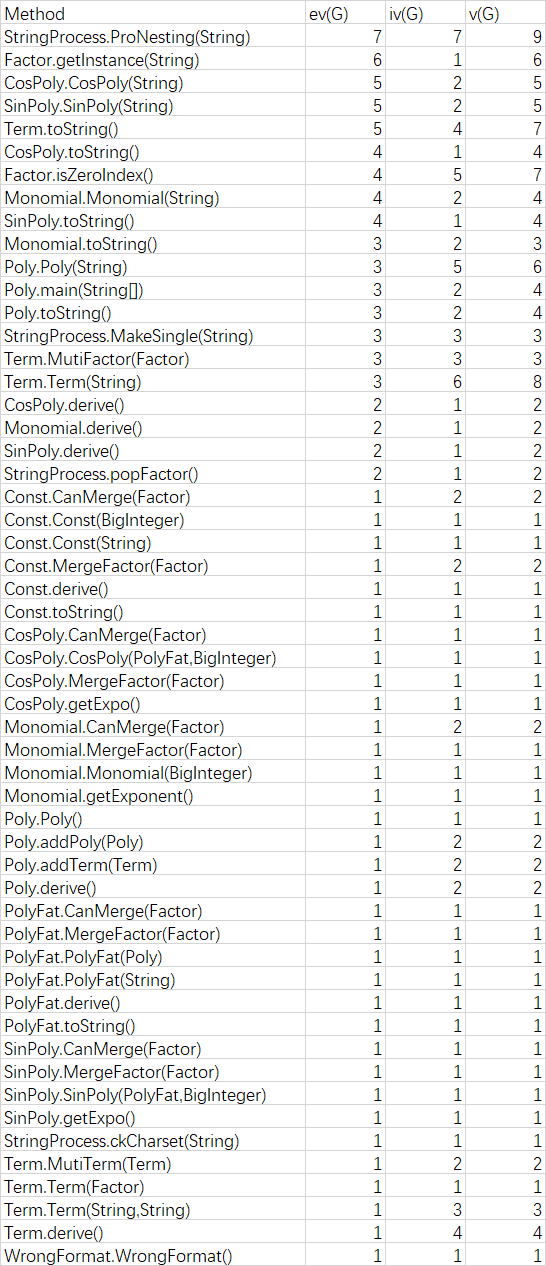
v(G) :即 Cyclomatic complexity。常翻译成圈复杂度或者条件复杂度。计算方法为:讲方法的流程图画出,则 v(G) = 边数 - 节点数 + 2. 反应的是方法中流程控制的复杂度。可以简单理解为,有越多的 if-else,while,for等语句时,该值越大。
ev(G):即 Essentail Complexity。常翻译成基本复杂度。计算方法为:将圈复杂度图中的结构化部分简化成一个点,计算简化以后流程图的圈复杂度就是基本复杂度。可以理解为,“基本复杂度是用来衡量程序非结构化程度的,非结构成分降低了程序的质量,增加了代码的维护难度,使程序难于理解。因此,基本复杂度高意味着非结构化程度高,难以模块化和维护。”
iv(G) :即 Module Design Complexity 。 表示和其他模块的之间相互作用的复杂度。计算方法为:模块设计复杂度是从模块流程图中移去那些不包含调用子模块的判定和循环结构后得出的圈复杂度。可以理解为,“软件模块设计复杂度高意味模块耦合度高,这将导致模块难于隔离、维护和复用。”
class中:
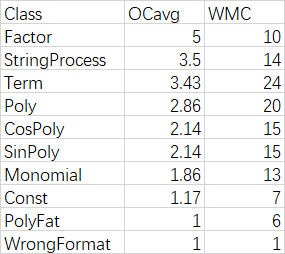
OCavg :类方法的平均圈复杂度。
WMC : 总圈复杂度。
第一次作业
思路
Term类用来管理单项式,给Poly类提供服务:如从字符串构建Term对象,Term对象的求导。Poly类负责输入处理,格式判断,并用Term类提供的服务来构建表达式,对表达式求导。
除此之外,Term类还提供一些获取对象属性的方法,用以Poly在输出时优化表达式。但此部分可能会造成类结构的不清晰。
UML图

Dependency metrics Analysis

Complexity metrics Analysis


分析
可以看出Term的构造器,toString方法的ev,iv,v值都较高(虽然都低于建议的10),其中有大概率产生bug。分析代码可以发现:
Term的构造器中行数很多:将格式检查,表达式解析,对象构建等工作都集合在此构造器方法中。事实上,可以将各个功能分别实现在不同函数中。
而toString方法因为需要处理 常数 和 幂函数 以及 常数乘以幂函数 三种情况,所以条件分支较多。事实上,这也是一个警钟:Term管理的事务,负责的细节也太多了,应该把不同的工作交给另外不同的类做。
同理,我们可以看到 Poly 的构造器 和 toString 方法也存在同样的问题。尤其是构造器。
第二次作业
思路
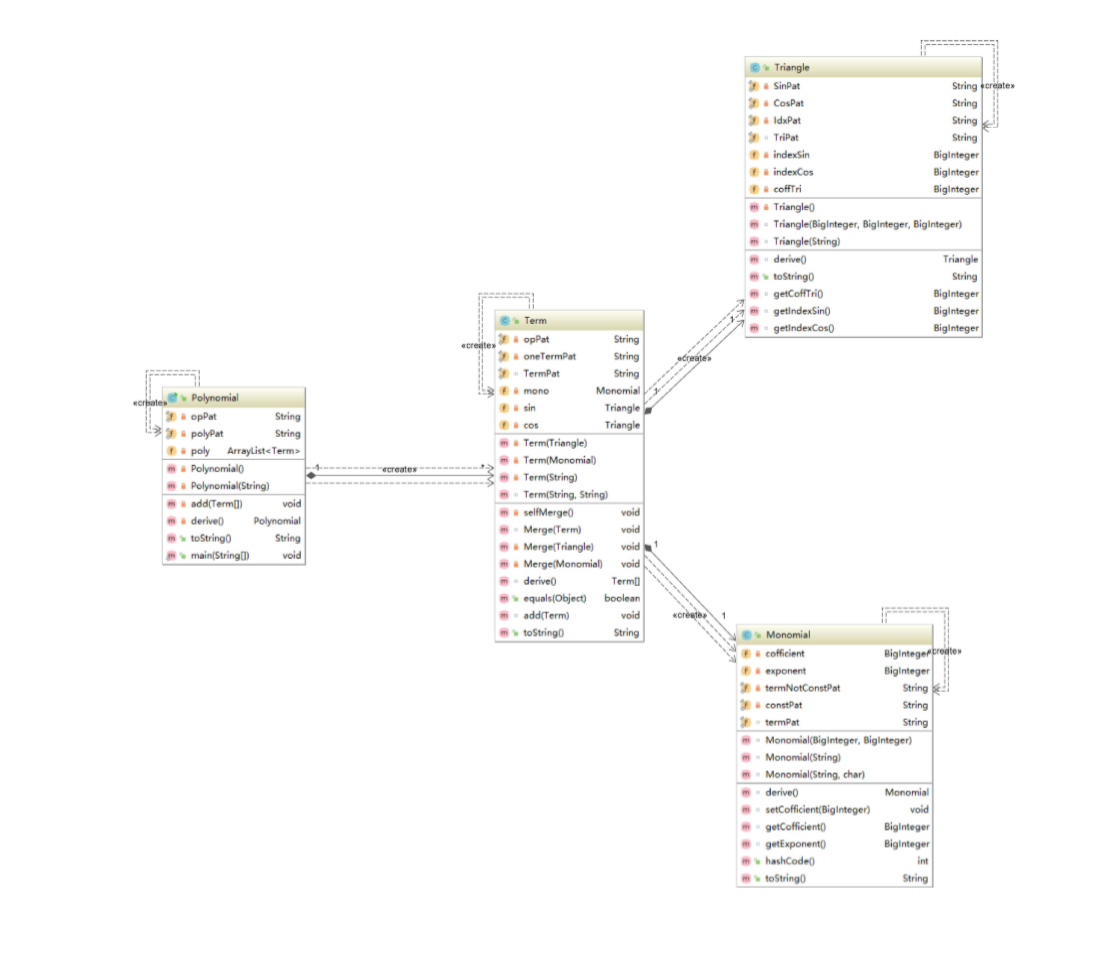
在第一次作业基础上增加了三角函数。于是思路和第一次大体相同:Poly负责多项式的管理。Term类负责项的管理,且只为poly提供服务。而Mono类和Triangle类分别管理单项式和三角函数项,为Term提供服务。
除此之外:Term,Mono,Triangle类还提供其他获得相关属性的方法。用以表达式输出结果的优化。但此部分可能会造成类结构的不清晰。
UML图
Dependency metrics Analysis

Complexity metrics Analysis

分析
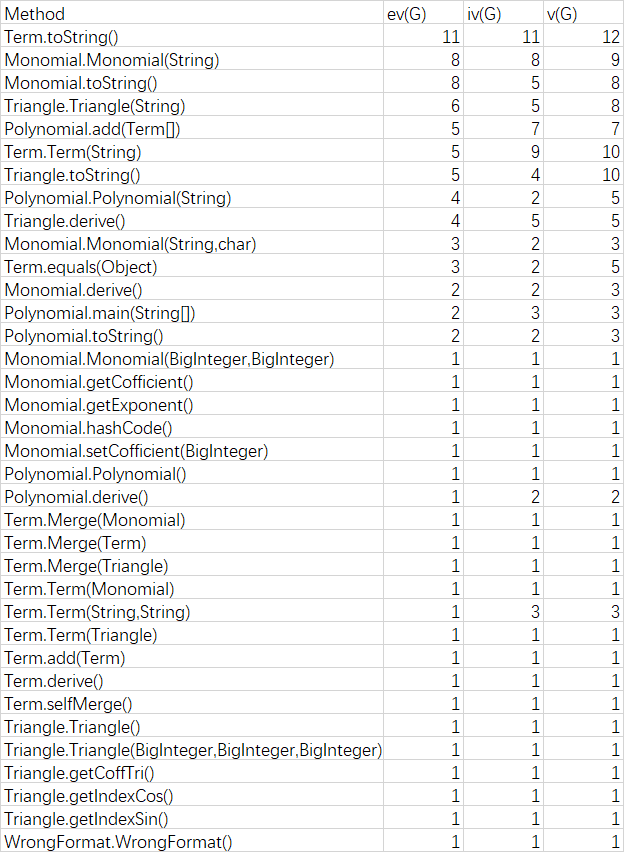
和第一次实验分析相似。各个类的构造器,toString方法的圈复杂度都较高。其中Mono类和第一次作业中的Term类是相同的,同时管理常量,单项式,幂函数。而Triangle类同时负责sin和cos。且以上两个类都没有更底层的提供服务的类。导致复杂度过大。属于bug的高发地段。 同时构造器依旧没有将各个功能分开。导致其十分复杂。
第三次作业
思路
Poly管理多项式,Term管理项,Factor管理因子。而const,Mono(幂函数类),Sin,Cos,PolyFat分别是因子,实现了Factor这一接口。而因子类们中间也有依赖关系:因为可以表达式嵌套,所以sin,cos,mono又都会接受Factor提供的服务。而PolyFat是表达式因子类,会使用Poly提供的服务。值得注意的是,StringProcess类负责表达式的预处理——将多项式因子预处理,所以在又可能出现多项式因子的地方,都需要此类提供服务。(虽然听起来不错,但这个设计为程序带来了致命的问题。。。)
除此之外:各个类有其他获得相应属性的方法,为了在表达式输出时做相应的优化。但此部分可能会造成类结构的不清晰。
UML图
在写代码前脑子里所构建的UML图:
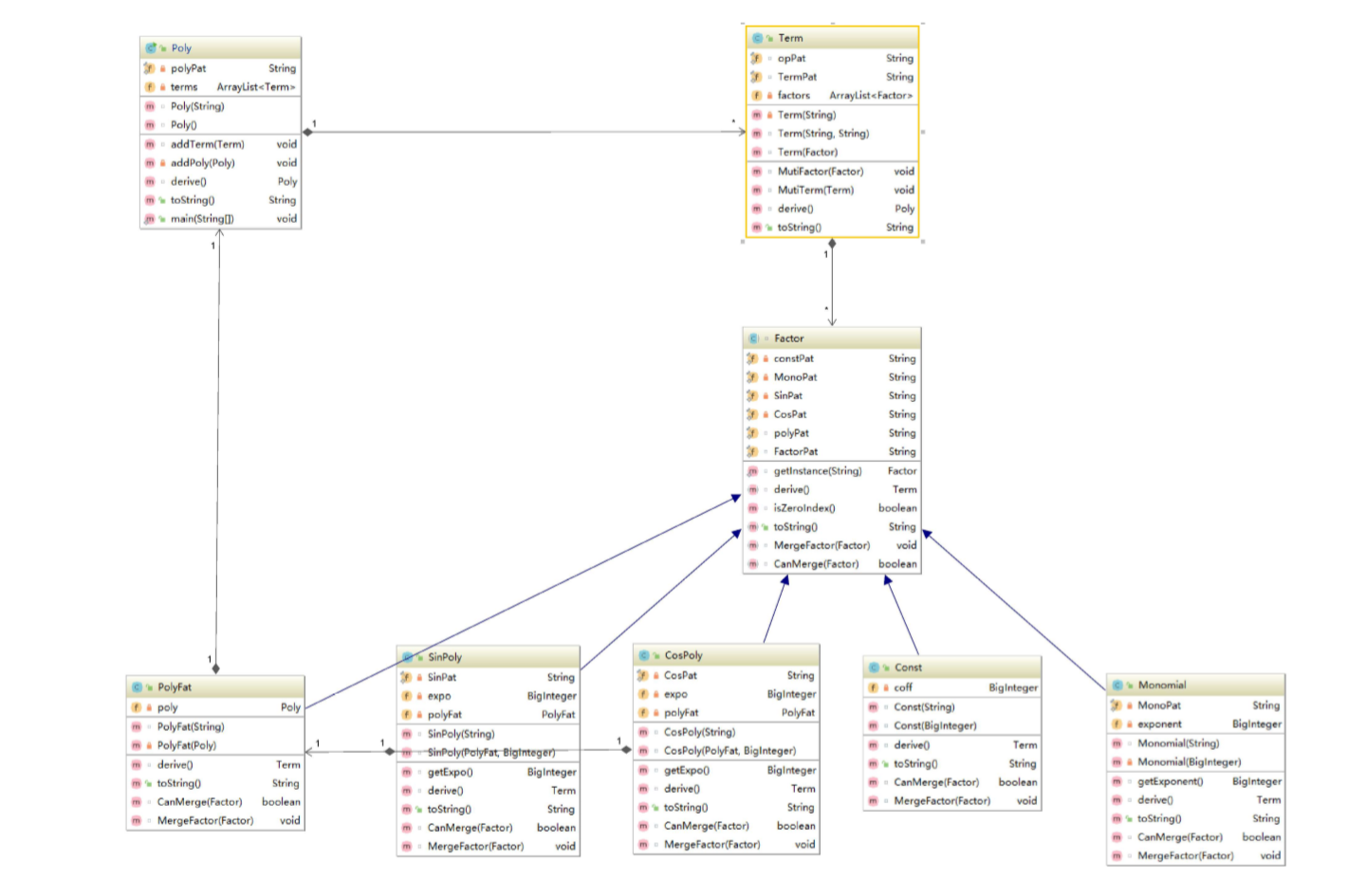
写完代码后IDE分析得到的UML图:

Dependency metrics Analysis
Complexity metrics Analysis
分析
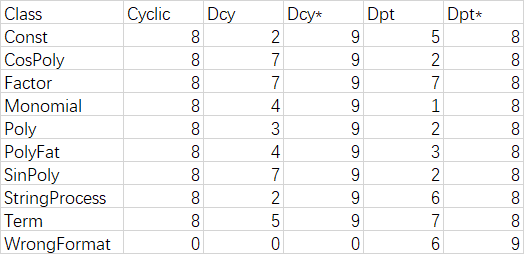
不同于上两次作业,第三次的作业循环依赖(cyclic)非常的高。这也是史料未及的,原因有如下几个方面:
1. 程序划分层次有多种划分方法。但这种 多项式,项,因子的划分方式事实上是按照运算符的优先级进行划分。有两方面问题:
(1)因子求导会产生项,项求导会产生多项式。即底层提供服务的类,需要用到返回顶层对象,由此会产生循环依赖。事实上可以使用返回因子或项的数组来减少这一依赖,但同时却隐含了 因子数组中各因子关系为相乘,项数组中各项关系是相加这一条件。 也为程序带来隐藏的bug,让程序难以理解。(2)按运算符优先级来划分会引入很多不必要的操作。如输入为(sin(cos(sin(cos((x^2)))))) 次表达式交给Poly处理,再呈递给Term处理,再交给Factor处理,发现只是一个PolyFat,但其中每次都需要调用StringProcess对字符串进行处理,而结果只是去除了一个括号。除此之外,当符号优先级增多时,构建表达式树的深度将急剧增加,而其中很多部分都是不必要的过程。所以我们可以猜到,编译器中对表达式的处理一定不是像这样划分的层次关系。
2. 优化所导致的类结构混乱。三次作业中对优化的处理都不是很好,让很多不应该暴露的方法都暴露出来。
但可以发现的是:虽然第三次的功能更多,但相对第二次的method的复杂度ev,iv,v却有下降:这得益于对因子类更细致的划分。但下降幅度并不是很大,而且复杂度高的依旧是构造方法和toString方法。说明这些方法依旧聚合度太高,里面塞进去的细节太多。
二、程序BUG分析
第一次BUGS:1.对除space和制表符外的其他空白字符没有特殊识别。2.底层提供给上层的服务中不支持制表符,只支持space,但是顶层却将包含制表符的串交给底层。
第二次BUGS:1.依旧是 空白字符 在底层和顶层之间没有统一标准。
第三次BUGS:1.依旧是 空白字符 在底层和顶层之间没有统一标准。匹配符号时使用了[+-]\\t*的正则,但在判断正负号时却使用了equals(“-”)这样的语句,忽略了空格。
2.设计上的不足,写出了时间复杂度超过O(n!)级别的代码,导致超时。具体原因在于表达式构建中类层次关系划分和StringProcess类的使用问题。在多次嵌套时,会执行大量无意义的代码。具体参见第三次作业分析。
三次BUG出现的地点有其十分明显的共性:构造器和toString方法中。基本上是由于这两个方法中代码职责不清晰,所管理的事物,关心的细节过多。而此时一点点粗心,放松,疏忽都会导致bug的出现。例如在表达式解析时,不但需要做格式检查,对象构建,还要关注空白字符等等的细节问题。而人毕竟是注意力,精力有限的生物。复杂的分支和循环也是bug潜藏的好地方。最好的做法就是将不同的简单的功能,交给不同的方法来实现。虽然这并不会让问题本身的复杂度有所降低,但会让精神在一个时间只集中在一件事情上,这是很有必要的。“Once your software is a certain size, you’ll be completely dominated by complexity.”
同时,三次BUG出现的一个原因也在于在构建底层类时,没有充分理解底层类(服务提供者)的角色地位:底层类应该是要像写库一样来提供尽可能广泛的服务呢;还是应该面向题目的要求,哪怕会和顶层类做重复的事情(就像顶层类已经做过格式检查了,调用底层类时,底层类是否还要再做一次格式检查);还是尽可能实现得简单些,拥有自己的格式化,由调用者来适应底层类的格式要求???这样,在没有清晰的划分出顶层类和底层类的职责时,就会产生一些隐藏的bug。
三、发现别人BUG时所采用的策略
逐行读代码法。好处:基本不会提交同质bug;在阅读别人代码时会学到很多东西;构造的测试数据针对性强。坏处:慢,很慢,特别慢,基本干不过手写评测机的;找bug没有用测试集撞来的容易。
学习大佬们的手写脚本评测机,和同学一起构建测试集。好处:在做OO作业的时候,解锁了其他神奇的能力;节省了时间。
四、Applying Creational Pattern
在第三次作业中,Factor是一个抽象类,同时又还有一个静态工厂函数Factor getInstance(String s),来提高Factor类对因子的封装程度。该工厂方法通过识别s的格式,来决定具体到底生成哪一种因子类。函数主主体为 if(s.matches(constPat))return new Const(s); if(s.matches(monoPat))return new Mono(s); ......等等。而为了提高可扩展性,同时还违反开闭原则,可以使用“注册表”,类的反射机制,在类内部定义静态匿名方法向工厂函数的注册表中注册。代码样例为 static { Factory.instance().registerProduct("ID1",OneProduct.class); } 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号