

论文解读《ImageNet Classification with Deep Convolutional Neural Networks》
这篇论文提出了AlexNet,奠定了深度学习在CV领域中的地位。
1. ReLu激活函数
2. Dropout
3. 数据增强
网络的架构如图所示
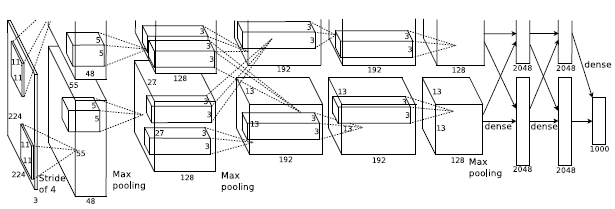
包含八个学习层:五个卷积神经网络和三个全连接网络,并且使用了最大池化。
RELU非线性层
传统的神经网络的输出包括$tanh$ 和 $ y = (1+e^{-x})^{-1}$,namely sigmoid。 在训练阶段的梯度下降的过程中, 饱和的非线性层比非饱和的非线性层下降得更慢。
-- RELU 可以加快训练的速度,与饱和非线性函数相比达到相同的训练损失率,可以经过更少的迭代时间;
-- 同时指出了 如果使用传统的饱和型的神经元模型,并不能够使这个比较大的神经网络模型很好的工作;
-- 在ImageNet 数据集主要关注的使避免过拟合;
多个GPU进行训练(Traning on Multiple GPUs)
单个GPU的memory 是有限的,对于网络和数据集来说,训练十分困难;
利用两个GPU进行并行训练;
GPU只在某些层进行通信。这意味着,例如,第3层的内核从第2层中的所有内核映射中获取输入。但是,第4层中的内核仅从第3层中驻留在第3层的内核映射中获取输入。 相同的GPU。 选择连通模式是交叉验证的一个问题,但这使我们能够精确调整通信量,直到它是计算量的可接受部分。
Local Response Normalization
尽管RELU激活函数的使用,可以在加快训练速度的同时,取得比饱和非线性映射更好的效果,但是作者在采用了局部归一化技术后,泛化性得到了提高。
在RELU后使用这些技术;
减小过拟合(Reducing Overfitting)
动机:由于整个网络拥有6000万个参数;尽管ILSVRC的1000个类使得每个训练示例对从图像到标签的映射施加10位约束,十分有必要去考虑过拟合的问题。
数据扩充(Data Augmentation)
图像数据扩充,即人工的扩大数据集, 是减小过拟合现象最简单和常用的方法,作者使用两者不同的数据扩充方法:
--第一种形式是包括生成图像平移(image translations)和水平反射(horizontal reflection,镜像)具体的,他们从256*256的图像种随机抽取了224*224的图像patch用于训练,这将我们的训练集的大小增加了2048倍,尽管由此产生的训练示例当然是高度相互依赖的。在测试阶段,取每一个测试样本四个角以及中间区域,一共5个patch然后再镜像后得到10个样本输入到网络中,最后将10个softmax输出平均后作为最后的输出(测试阶段的处理有意思)。
--第二种形式是使用PCA对于训练数据进行增强:对于每一个RGB图像进行一个PCA的变换,完成去噪功能,同时为了保证图像的多样性,在特征值上加了一个随机的尺度因子,每一轮重新生成一个尺度因子,这样保证了同一副图像中在显著特征上有一定范围的变换,降低了过拟合的概率,作者指出这种方法近似的捕获了自然图像的主要属性,即对象标识不受光照强度和颜色变化的影响;
Dropout
将每个隐藏层的神经元以50%的概率进行随机置零;这些被随机置零的神经元并不在前向传播中产生作用,也不参与反向传播。使得每次的输入,神经网络都会对不同的体系结构进行采样,但是这些结构是分享权重的;减小了神经元之间复杂的协同适应能力。
所以dropout 强迫网络学习与其他神经元的许多不同的子集一起使用的更加健壮的特征。作者在前连个全连接层使用了dropout , 指出 付出了两倍的收敛时间‘
Overlapping Pooling
CNNs中的池化层总结了同一核映射中相邻神经元群的输出。传统的池化都是不重叠的,也就是说池化操作的步长是等于filter的尺寸的;而作者采用了重叠池化的操作,即步长小于filter的尺寸,减小了损失。

