



CGANs
Introducation
1. intruduce the conditional version of GANs, which can be constructed by simply feeding the data , y.
2. the CGANs can be used to learn a multi-modal model.
3.GANs in order to sidestep the difficulty of approximating many intractable probabilistic computations.(为了避免许多难以处理的概率计算的近似困难)
4. Adversarial nets have the advantages that Markov chains are never needed, only backpropagation is used to obtain gradients, no inference is required during learning,
and a wide variety of factors and interactions can easily be incorporated into the model.(多种因素和相互作用可以很容易地纳入模型)
5.马尔可夫链(Markov Chain),描述了一种状态序列,其每个状态值取决于前面有限个状态。一般来说,其核心是满足条件期望和平稳的分布,保证在计算过程中能够得到想要的概率分布。而我们考虑的生成模型恰好可能有以下两种情况:
-
输入一个随机分布的数据(例如一张黑白像素夹杂的噪音图),输出期望的数据(一张头像)
-
输入含有噪音的数据(在原有的图像上添加噪点或缺损),输出除去噪点或补完后的数据(完整的原始图像),这种情况下的模型也可以叫做任意去噪的自编码器。
无论是哪种情况,我们都希望从模型输出的数据y的概率分布尽可能逼近训练数据集的概率分布。但是让计算机生成一段音乐,或者一张有意义的图片,这个分布是非常复杂,很难求解的;即使通过马尔可夫链取样,得到了一个生成模型,我们最终也很难对这个模型的效果进行评估,因为生成的音乐到底好不好听,不同的人会得到不同的答案。
6. GANs can produce state of the art log-likehood estimate and realistic samples.
7. but
Related Work
1. the challeage of scaling models to accommodate an extremely large number of predicted output categories (调整模型以适应非常多的预测输出类别的挑战), to adress this problem by leveraging additional information such as using natural language corpora.and even a simple linear mapping from image feature-space to word-representation-space can improve.
2. the challage of focusing on learning one-to-one mapping from input to output,but many interesting problems belong to a probabilistic one-to-many mapping.to adress this challege by using a conditional probabilistic generative model , for example, the input is taken to be the conditioning variable and the one-to-many mapping is instantiated(实例化)as a conditional predictive distribution.
Method
1. to specify that the G can capture the data distribution and the D can estimate the probability that a sample came from the training data rather than G.
2. the input is z, G and D are both trained simultaneously. we adjust the parameters for G to minimize $log(1-D(G(z)))$ and adjust the parameters for D to minimize $log(D(X))$
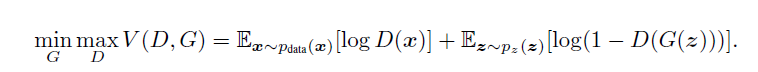
Import Details -----Conditional Adversarial Nets
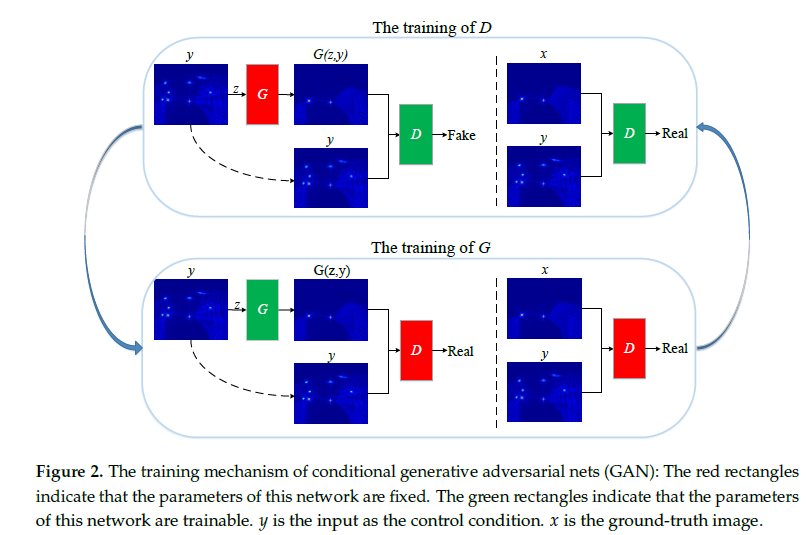
The training mechanism of CGANs.
1. GANs can be extended to a conditional model if both the G and D are conditioned on some extra information y.
2. y can be any kind of auxiliary information such as class label or data from other modalities.
3. feeding y into both discriminator and generator as additional input layer.
4. prior input noise and y are combined into joint hidden representation 对抗性训练框架允许在如何组成这种隐藏的表示方面具有相当大的灵活性。
5. In the discriminator and are presented as inputs and to a discriminative function (embodied x y again by a MLP in this case).
The formula of a objective function :
![]()
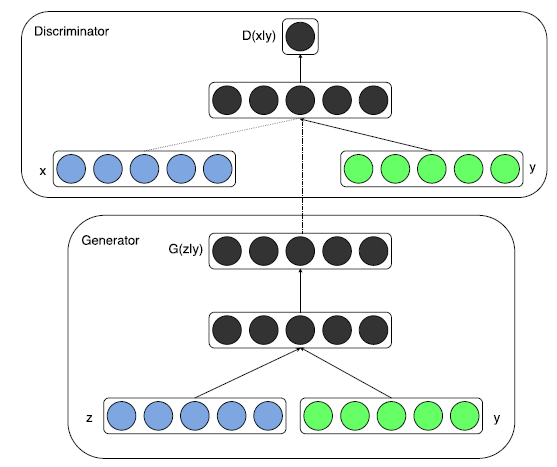
The framework of CGANs:
Experiment
1. this paper trained a CGANs on MNIST images conditioned on their class labels, encoded as one-hot vectors.
For G:
both z and y are mapped to hidden layers with RELU, with layer sizes 200 and 1000 respectively, then combined hidden ReLu layer of dimensionality 1200.
For D:
The discriminator maps to a maxout [6] layer with 240 units and 5 pieces, and to a maxout layer x y with 50 units and 5 pieces. Both of the hidden layers mapped to a joint maxout layer with 240 units and 4 pieces before being fed to the sigmoid layer
For Training:
and best estimate of log-likehood on the validation set was used as stopping point.(并以验证集的对数似然最优估计值作为停止点)。

Summary
CGANs outperforms compared with original GANs, we can combine the class label or data from other modalities into the input of G and D, in order to achieve conditional probabilities distribution and controlling GANs.

