
(cvpr2019 ) Better Version of SRMD
SRMD的内容上篇,已经介绍,本文主要介绍SRMD的升级版,解决SRMD的诸多问题,
并进行模拟实验。
进行双三次差值(bicubic)===>对应matlab imresize()
%% read images im = {}; scale_factor = 6; im_ = dir('E:\A_paper\TEM降噪用GAN\matlab_codes\images\*.jpg'); path = ['E:\A_paper\TEM降噪用GAN\matlab_codes\images\',im_(1).name]; im{1} = imread(path); if size(im{1},3) > 1 im{1} = rgb2gray(im{1}); im{1} = im{1}(:,:,1); end %% bicubic interpolation img_up = imresize(im{1}, scale_factor, 'bicubic'); img_down = imresize(im{1}, 1/scale_factor, 'bicubic'); %% image showing figure,imshow(im{1}); figure,imshow(img_up); figure,imshow(img_down);
对应的图片:

当scale_factor放大图像,图像更为平滑,而缩小图像,则更为模糊。
下采样原理(downsample):对于一幅图像I尺寸为$M*N$,对其进行s倍下采样,即得到$(M/s)*(N/s)$尺寸的得分辨率图像,当然s应该是M和N的公约数才行,如果考虑的是矩阵形式的图像,就是把原始图像s*s窗口内的图像变成一个像素,这个像素点的值就是窗口内所有像素的均值:
上采样原理(upsamle):图像放大几乎都是采用内插值方法,即在原有图像像素的基础上在像素点之间采用合适的插值算法插入新的元素。
插值方法---- 代表Bicubic
双线性插值法具有平滑功能,能有效地克服邻法的不足,但会退化图像的高频部分,使图像细节变模糊。在放大倍数比较高时,高阶插值,如双三次和三次样条插值等比低阶插值效果好。这些插值算法可以使插值生成的像素灰度值延续原图像灰度变化的连续性,从而使放大图像浓淡变化自然平滑。但是在图像中,有些像素与相邻像素间灰度值存在突变,即存在灰度不连续性。这些具有灰度值突变的像素就是图像中描述对象的轮廓或纹理图像的边缘像素。在图像放大中,对这些具有不连续灰度特性的像素,如果采用常规的插值算法生成新增加的像素,势必会使放大图像的轮廓和纹理模糊,降低图像质量。
缺点:
采用了LF的思想,易出现过度平滑,纹理和边缘信息丢失。
基于模型的优化算法
利用图像的先验信息(e.g.非局部相似先验 去噪先验--Learning deep CNN denoiser prior for ....张凯),通过求解目标函数的方式得到SR图像,但是比较耗时,
需要引入预先难受的超参数。
判别学习方法
依赖CNN强大的学习能力,利用大量的图像训练训练集进行训练,学习LR图像和HR图像之间的映射,
从而能够对于输入LR图像进行有效超分辨重构。但是这类模型都假设LR图像是由HR图像双三次插值得到,
当图像的退化方式与其不同时候,模型很难对于多退化的LR图像进行超分辨率。
图像评价指标
MSE和PSNR为考虑图像的感知特性和图像结构特征,基于图像结构特征比较的评价算法---结构相似度SSIM
,利用高斯滑动窗口的方法对图像进行分块,并利用高斯加权计算每个滑动窗口图像像素的均值、方差和协方差。
Discuss
现有的CNN模型,简单输入LR图像进行端到端训练,难对于模型求解,需要处理多退化因子的图像。
充分利用先验的方法
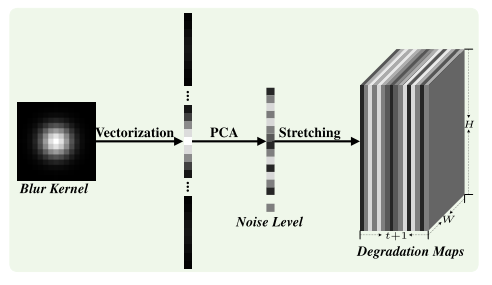
利用LR图像退化参数的先验信息帮助模型对于多退化图像的处理。但是存在几个问题,如何有效的表示退化信息,
并且将退化信息和LR图像维度进行统一(SRMD利用PCA降维以及矩阵平铺、复杂的升维方法,将退化图谱和LR图像
进行拼接,输入网络)。
充分利用全卷积和移除亚像素卷积层
对于处理多尺度超分辨率问题,亚像素卷积层进行上采样需要对输入的$W*H*S^{2}C$大小的张量进行像素重排,从而得到s
$sW*sH*C$大小的输出图像,每个尺度的超分辨率任务需要单独训练。(直接反卷积其实存在一些问题)
直接除去亚像素卷积层,而变为全卷积层,使输入和输出的尺度直接对应于缩放的尺度:直接将LR图像进行插值上采样
得到与目标图像大小相同的尺寸,输入网络。
什么是亚像素卷积层?

在亚像素卷积层前的卷积层,将输出通道变为缩放尺度的平方,在亚像素卷积层得到想要的尺度。
获得LR图像退化方法
SRMD仅仅能够在LR图像退化方法已知的图像超分辨任务中。
训练策略
每个epoch都训练x2、x3、x4的尺度因子,避免选择遗忘。
基于卷积神经网络的退化参数图谱估计模型
将LR图像直接输入估计网络,输入$W*H*3$输出得到$W*H*(t+1)$
在估计到退化图谱后,使用PCA降维和矩阵平铺,复制的升维方法构建处退化图谱作为标签进行构建损失函数
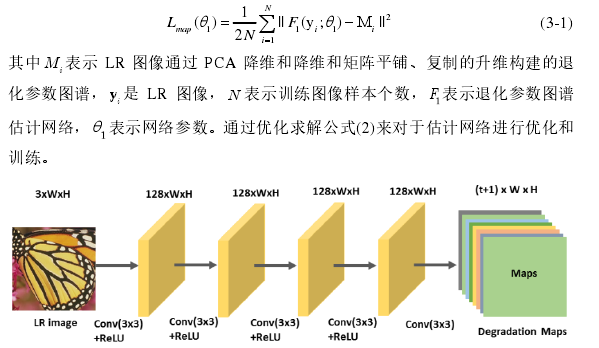
中间卷积可以使用Resnet残差学习思想:

多个网络级联训练

整体损失:
$L(\theta_{1},\theta_{2}) = L_{map}(\theta_{1})+\lambda L_{convnet}(\theta_{1},\theta_{2})$
$L_{convnet}$使训练超分辨率子网络,$\theta_{2}$表示超分辨率子网络参数,$L_{map}$表示退化图谱重构
损失,用来约束训练退化图谱估计子网络。
两个损失都是MSE损失,但是两个网络可以不单独级联,而是作为一个整体网络训练,将两个网络的参数同时
优化,来自超分辨率的梯度也会传递到退化图谱估计网络,线性相加,$\lambda$是平衡两个损失的权值。
该网络更依赖退化图谱网络计算的梯度权值相对于由来自深层超分辨网络的梯度更大一些,$\lambda$为0.1
,增加退化图谱的损失权值,便于更好优化退化图谱估计子网络。
需要学些PCA降维部分的内容

 浙公网安备 33010602011771号
浙公网安备 33010602011771号