



(Review cs231n) CNN in Practice
Make the most of your data
Data augmentation

加载图像后,对图像做一些变化,这些变换不改变图像的标签。
通过各种变换人为的增大数据集,可以避免过拟合提高模型的性能,最简单的数据增强就是横向翻转。
1. horizontal flips

2. random crops and scales
对图像进行随机的尺度和位置上选择图像截图;缩放到CNN需要的图像大小最为新的数据集。

使用随机裁剪和缩放来训练模型的时候,用整幅图像来测试算法并不合理,因此在测试阶段,要准备一些
固定的截图,并用这些数据来测试算法,非常常见的作法是选取图像的10个截图(左上角、右上角、下面两个角和中间部分的截图,并把这五个图进行翻转)。
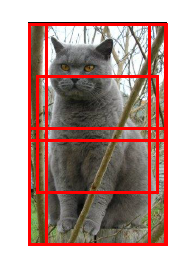
Resnet在测试阶段进行多尺度的变换
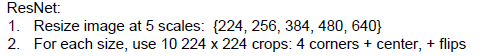
3.color jitter
一种简单的方法就是改变对比度

复杂的方法就是:对训练集所有像素做主成分分析(PCA),每个像素是一个长度为3的向量(RGB),当我们遍历所有像素后,得到主要颜色有哪些,然后PCA给出颜色空间中3个主要的颜色方向,表明数据集中颜色在哪个方向上变换最为剧烈,做数据增强,根据这些颜色的主成分来决定新产生的颜色。
4.add extra noise
增加随机噪声扰乱网络,包括BN、Minibatch,dropout弱化了噪声的影响,在BN中保留了均值。
在前向传播时随机增加噪声,在测试的时候弱化噪声影响。
Transfer learning
对于数据量较小,只能把手头的网络当作一个特征提取器,imagenet最后一层是softmax,用一个满足自己需求的线性分类器来代替这个softmax, 其他层不变,只训练这个顶层,类似于只训练一个线性分类器。
类似于:你只要把训练集产生的所有特征存在硬盘上。
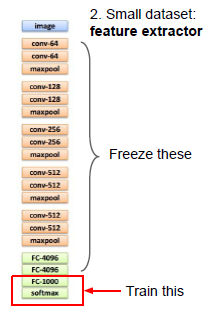
数据量较多的话:可以训练更复杂的网络,在最后几层去训练,得到feature map,最后的几层重新初始化,前面的freeze部分不变初始化。

微调finetuning的建议:
第一种是学习率为0的固定层。
第二种是从头开始初始化的层,一般学习率高一些,1/10吧。
第三种是预训练网络中的中间层,要在优化和finetuning中学习,这些中间层的学习率很小,1/100.
微调的muti-stages 建议:
第一步是把网络固定,只训练最后几层,当最后几层快要收敛后,再对这些(包括要训练的中间层进行fineturing)。
由于刚刚初始化,所以梯度会很大,可以先开始固定中间层,等着最后层收敛;或者两个阶段使用不同的学习率。
微调这种迁移学习,当原来网络是类似类型的数据训练出来的时候,微调效果高。
迁移学习的建议

对于MRI数据集,高阶特征可能是针对某种图像的分类,低阶特征是边缘一类的特征,这些低阶特征很容易迁移到非图像数据上面去,
All about convolutions
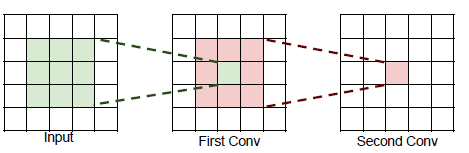
堆叠两个3*3的卷积,得到一个神经元等于一个5*5的卷积;
堆叠三个3*3的卷积,得到一个神经元等于一个7*7的卷积;
一个7*7的卷积和堆叠三个3*3的卷积在参数规模上的区别:

3*3的三个卷积更好。

3*3的三个卷积比大卷积更少的计算。

比较神奇的结构,1*1的卷积减小了深度上的体积,在空间上有相同的尺寸,要做一个3*3的降维卷积
再做一个1*1的卷积回到原来的深度。
作用:
1*1的卷积减小深度上的维度叫做“bottleneck”,就像将一个多层的全连接层遍历每个数据通道

使用这种结构,可以获得更小的参数规模,参数的个数和计算量直接相关,多层瓶颈结构计算起来快得多,并且有更好的非线性。
卷积的计算
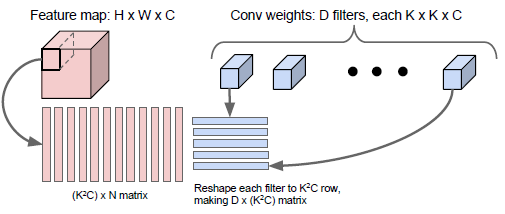
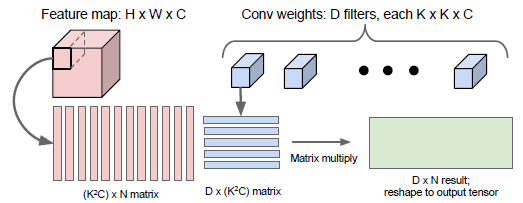
How to arrange them
How to compute them fast
Implementation details

