【论文笔记-5~20】多语言命名实体识别
~2011年
1. Weakly Supervised Named Entity Transliteration and Discovery from Multilingual Comparable Corpora
文章核心观点:
这篇文章提出了一种新的跨语言多词命名实体发现算法。通过弱时间对齐的双语语料库,该算法利用实体的时间分布相似性和音译相似性来发现命名实体。文章详细描述了时间序列相似度的计算方法,以及一个基于特征的判别式音译模型。实验结果表明,同时使用时间和音译信息进行命名实体匹配的效果优于单独使用其中一种信息。该算法不需要对目标语言有太多先验知识,适用于低资源语言的命名实体识别。
动机:命名实体识别中许多语言缺乏有监督的数据
方法:提出一种(几乎)无监督的学习算法,通过预先给定的与资源丰富的语言弱时间对齐的双语语料库。

相关工作:
- 已经有其他工作在最小监督的情况下自动发现命名实体,然而,他们关注的是已经分割出的实体的分类阶段,并利用了上下文和形态学的线索,这些线索需要超出我们希望假设的目标语言水平的知识。
- 使用时间分布的相似性进行信息提取,特别是NE提取,并不是新概念。
- 在语言转写模型方面已经有很多先前的工作。大多数是生成性的,并考虑为给定单词产生适当转写的任务,因此需要相当多的语言知识。虽然生成性模型通常很健壮,但它们倾向于做出在数据中不成立的独立性假设。
不足:~
语言:英语->俄语
数据集:comparable English-Russian news corpus(本论文)
任务:多语言命名实体识别
转移资源:Parallel corpora、Universal features(时间分布);语言特征;Bilingual dictionary(用于音译结果增强)
转移范例:标签转移
细节:具体来说,有一个平行语言库,可以根据实体的时间分布特征和音译特征对这些实体进行对齐,对齐后的实体被合并。
算法:共排序(候选项)+离散傅里叶变换(计算相似度)
资源:
双语可比语料库:构建了一个英俄双语可比新闻语料库,其中包含弱时间对齐的文章。这是算法的核心输入数据。
英俄词典:使用了英俄词典来获取单词的翻译候选,并将其整合到多词命名实体的发现过程中。
翻译模型:开发了一个线性判别翻译模型,用于从源语言命名实体中选取目标语言中的最佳翻译候选。
时间序列匹配函数:采用了一种基于离散傅里叶变换(DFT)的时间序列匹配函数,用于计算源语言和目标语言命名实体之间时间分布的相似性。
初始翻译示例:为训练翻译模型,使用了初始的英俄翻译示例对进行种子训练。
非命名实体噪声数据:为训练翻译模型,使用随机英语非命名实体和俄语单词作为负例。
特征生成方法:采用了一种特征生成方法,用于从源语言和目标语言单词中生成子串配对特征。
2. A multilingual Named Entity Recognition system using boosting and C4.5 decision tree learning algorithms
文章核心观点:
这篇文章介绍了一个多语言命名实体识别系统,该系统利用AdaBoostM1和C4.5决策树学习算法来识别和分类匈牙利语和英语中的命名实体。作者构建了尽可能大的特征集,并采用划分和重组技术来充分利用其潜力。该方法训练了基于特征子集的独立决策树分类器,并将它们的决策通过多数投票结合起来。作者使用CoNLL 2003会议的语料库和Szeged语料库的一个片段进行训练和验证。实验结果表明,该系统在匈牙利语上的性能略高于CoNLL 2003会议上的最佳系统,达到了94.77%的F值。该系统与CoNLL模型结合使用时,由于具有不同的理论基础,显示出极大的成功。整体而言,该文通过AdaBoost和C4.5决策树学习算法成功构建了一个竞争性的命名实体识别系统。
动机:无。(在众多自然语言处理应用中,对普通文本中的专有名词进行识别和分类具有至关重要的意义)
方法:手工注释匈牙利语料库,AdaBoostMl和C4.5决策树学习算法进行分类
相关工作:机器学习方法(最大熵模型、隐马尔可夫模型(CoNLL-2003)和支持向量机(JNLPBA2004,[10]))
不足:~
语言:英语->匈牙利语
数据集:CONLL-2003、Szeged Treebank
任务:多语言命名实体识别
转移资源:Universal features
转移范例:标签转移,特征转移
细节:具体来说,人工注释一个匈牙利平行语料库,这个数据集和英语数据集主题相同,从两个数据集中抽取出语言特征和通用特征库,根据特征判断结果.
• 正字法特征:首字母大写、词的长度、关于词形的常见信息(包含数字与否、词内有大写字符等)。
我们从分配给每个NE类别的训练文本中收集了最具特征性的字符级双/三gram,
• 频率信息:标记的频率、标记首字母大写和小写出现的比率、标记首字母大写和句子开头频率的比率,
• 短语信息:块代码和对前面几个词的预测类别(我们使用了在线评估),
• 上下文信息:词性代码(我们对匈牙利语使用了我们自己的POS标注器生成的代码,而不是使用Szeged树库中的现有标签)、句子位置、文档区域(标题或正文)、主题代码、触发词(NEs周围的窗口中最常见且明确的标记)来自训练文本,单词是否在引号之间等等。
算法:AdaBoostMl和C4.5决策树学习算法(分类)
3. Mining wiki resources for multilingual named entity recognition
文章核心观点:
这篇文章介绍了一种利用维基百科多语言特征进行命名实体识别的方法。其主要贡献包括: 1. 提出了一种自动从维基百科中挖掘命名实体的方法,包括识别可能的命名实体,以及使用维基百科的类别结构判断实体的类型。 2. 提出了利用英语维基百科的数据来启动其他语言的命名实体识别过程。 3. 使用生成的语料训练了基于BBN Identifinder的命名实体识别系统,在法语、乌克兰语、西班牙语、波兰语、俄语和葡萄牙语上进行了测试,并取得了与人工标注约1.5-4万词新闻语料相当的性能。 4. 该方法不需要语言专业知识,特别适用于资源较少的语言,随着维基百科的发展,可以覆盖更多语言。 5. 该方法生成的语料可以作为其他命名实体识别系统的补充。
动机:大多数研究都局限于少数几种语言,几乎所有方法都需要相当的语言专业知识,无论是创建特定于一种语言的基于规则的技术,还是手动注释一批文本作为统计引擎或机器学习的训练集。
方法:
- 英语语言分类:
- 提取英语Wikipedia文章的类别信息。
- 手动总结关键词,以帮助判断实体的类型。
- 多语言分类:
- 对于非英语实体,查找对应的英语实体,并根据英语实体的类型进行分类。
- 若无对应的英语实体,则根据非英语实体的类别与英语类别映射,进行分类。
- 使用Wiktionary消除普通名词的歧义。
相关工作:维基百科研究、语言链接 -> 依赖WordNet或其他语言特性
不足:未在非英语环境下消歧,粗粒度分类
语言:英语->法语、乌克兰语、西班牙语、波兰语、俄语、葡萄牙语
数据集:ACE 2007、wikipedia
任务:多语言命名实体识别
转移资源:Parallel corpora(wikipedia)
转移范例:标签转移
细节:根据wikipedia内容对英语条目进行分类,非英语条目通过语言链接找到相应英语条目的分类,没有对应的则根据文章内容中的Category元素进行判断。
算法:略
资源:Wikipedia的多语言链接:通过不同语言Wikipedia之间的链接,将非英语实体与英语实体相关联,从而帮助识别非英语实体的类型。
Wiktionary:利用英语Wiktionary词典,识别一些普通名词,以消除歧义。
英语Wikipedia的分类结构:利用英语Wikipedia的分类结构,手动总结了一些关键词,以帮助判断实体的类型。然后根据这些关键词,对非英语Wikipedia的分类进行映射,从而判断非英语实体的类型。
英语Wikipedia的文章:利用英语Wikipedia的文章内容,帮助识别非英语文章中未明确链接的实体。
英语作为中间语言:将英语作为中间语言,减少了对目标语言的语言知识需求,因为系统主要依赖英语信息来帮助识别非英语实体的类型。
4. Building a multilingual named entity-annotated corpus using annotation projection
文章核心观点:
这篇文章介绍了一种利用平行语料库自动构建多语言命名实体标注语料库的方法。主要步骤包括使用命名实体识别系统对源语言文本进行自动标注,然后使用统计机器翻译系统将源语言命名实体翻译成目标语言,最后通过字符串匹配、辅音签名匹配和编辑距离相似度等方法将源语言命名实体投影到目标语言文本中。实验结果显示,该方法可以显著提高跨语言命名实体标注的召回率,为多语言命名实体识别系统的评估提供了有效支持。
动机:评估资源瓶颈问题:我们需要多种语言的评估数据,注释过程不应过于耗时,且跨语言的评估结果应该是可比较的。
方法:通过自动注释多语言平行语料库的英文版本,并将注释投影到所有其他语言版本来解决这个问题。对于英文实体的翻译,我们使用基于短语的统计机器翻译系统以及从多语言名称数据库中查找已知名称。在投影过程中,我们逐步应用不同的方法:完美的字符串匹配、完美的辅音签名匹配和编辑距离相似性。
相关工作:命名实体识别(依赖注释语料库)
不足:
语言:英语->法语、西班牙语、德语、捷克语、俄语
数据集:self-generated
任务:多语言命名实体识别
转移资源:Parallel corpora、Machine translation、Bilingual dictionary、Language features
转移范例:标签转移
细节:目标是构建一个多语言平行语料库来辅助单语言NER,给定未注释的平行语料库,首先注释英语(手动或自动)再投影。通过Machine translation、Bilingual dictionary匹配实体,匹配不上的通过辅音签名匹配。
算法:略
资源:
多语言平行语料库,包括英语、法语、西班牙语、德语、捷克语和俄语新闻文本平行语料库。这些语料库为命名实体注释的投影提供了基础。
基于短语的统计机器翻译系统(Moses),用于将源语言(英语)中的命名实体翻译成目标语言。
多语言命名实体数据库,包含不同语言的命名实体翻译和音译,与机器翻译系统形成互补,提高翻译质量。
编辑距离算法,用于计算源语言和目标语言命名实体之间的相似度,辅助基于字符串匹配的投影方法。
辅音签名匹配方法,通过辅音的匹配来发现目标语言中的命名实体。
英语命名实体识别系统,用于对源语言语料库进行命名实体注释。
总结
- 转移资源:早期跨语言NER工作中平行语料库是必不可少的内容,它提供了相同主题下源语言到目标语言的句子或文档级别对齐,但达到单词级别的对齐仍然需要其它手段。Universal features是常用的辅助方法,它与语言无关,例如[1]中注意到预对齐实体的出现频率在时间上相似,可以作为对齐依据,但它要求实体属于同一主题和标注时间信息。[2]使用了信息更丰富的上下文信息,包括词性代码、句子位置单词是否在引号之间。一些研究使用Language features作为判断标准,他们来源于语言学家的专业知识,例如[2]通过正字法特征对比实体的词形,[4]使用了辅音签名匹配。但上面这些方法的一个明显缺陷是需要相当的语言专业知识,无论是词性标注还是词形对比都依赖语言学,对早期大多依赖规则或手工的方式并不友好。因此有研究[2,4]在上述方法基础上增加了Bilingual dictionary和Machine translation进行单词对齐,但翻译的效果并不稳定,歧义和指代等现象经常引入错误信息。[3]注意到维基百科作为一个全球开放系统和许多NER系统的数据来源本身具有跨语言对齐的手段,即连接不同语言相同实体的内部语言链接,同时维基百科还具有分类信息,能够为大量文本语料库添加可信度极高的粗粒度NER标签。
- 转移参数:[1,2,3,4]标签,[2]特征
- 转移技术:[1]通过对单词的时间分布特征进行相似度计算来判断是否对齐。[2]使用机器学习方法AdaBoostMl和C4.5决策树学习算法,从两个数据集中抽取出语言特征和通用特征库,根据特征判断结果. [3,4]匹配/相似度。
2012~2018
5. Learning multilingual named entity recognition from Wikipedia
与3. Mining wiki resources for multilingual named entity recognition类似
文章核心观点:
这篇文章介绍了一种从维基百科自动创建命名实体标注语料库的方法,主要用于训练命名实体识别系统。主要方法是利用文章中的链接,将链接目标文章的命名实体类型标注到链接的锚文本上。为提高标注的准确性,研究人员设计了一个多语言的命名实体分类方案,并对维基百科文章进行了标注,并通过跨语言链接将标注映射到其他语言的维基百科文章。此外,研究人员还对标注后的语料库进行了进一步优化,以提高标注质量。实验结果表明,使用维基百科数据训练的命名实体识别系统,在多种语言的测试语料库上表现良好,性能可以与手工标注的语料库相媲美,为多语言命名实体识别任务提供了高效的训练语料库。
动机:对昂贵注释的依赖是我们的工作所克服的知识瓶颈
方法:我们通过将目标文章的分类投影到锚文本上,将文章之间的链接转换为NE注释。测试方法:最大熵

相关工作:XX
不足:
- 尽管我们只针对已有命名实体识别(NER)语料库的语言进行了评估,但我们的成果表明它们可以应用于维基百科所涵盖的许多资源匮乏的语言。
- 尚未采取更广泛的多语言方法来进行文章分类或派生训练数据,以测试我们的方法在不同语言和黄金标准之间的稳健性。
- XX
语言:英语、德语、法语、波兰语、意大利语、西班牙语、荷兰语、葡萄牙语和俄语。
数据集:CoNLL-02、CoBLL-03、Appen Butler Hill、self-generated
任务:多语言命名实体识别
转移资源:Parallel corpora(wiki)
转移范例:标签转移
细节:XX
算法:略
6. Learning how to active learn: A deep reinforcement learning approach
文章核心观点
这篇文章提出了一种基于深度强化学习的主动学习方法,用于学习主动学习策略。文章将主动学习形式化为马尔可夫决策过程,并通过深度Q网络学习选择策略,同时引入了跨语言转移机制,将源语言学到的策略转移到目标语言。在命名实体识别任务上的实验结果表明,该方法相比传统不确定性采样方法,在双语和多语言设置下取得了更好的性能。即使在低资源“冷启动”设置下,该方法也能利用预训练模型,优于随机采样和不确定性采样。总体来说,文章提出了一种数据驱动的主动学习策略学习方法,具有跨语言可迁移性,并在命名实体识别任务上取得了显著改进。
动机:对昂贵注释的依赖,同时大多数主动学习算法需要一个大量的“种子集”数据来学习一个基本分类器
方法:基于策略的主动学习,这是一种从数据中学习动态主动学习策略的新方法(不使用固定的启发式方法,而是学习如何主动选择数据)。使用跨语言词嵌入来学习两种语言的兼容数据表示,这样学习到的策略就可以轻松地移植到另一种语言中。

相关工作:XX
不足:XX
语言:英语 (en)、德语 (de)、西班牙语 (es) 和荷兰语 (nl)
数据集:CoNLL2002/2003
任务:多语言命名实体识别
转移资源:multilingual word embeddings
转移范例:参数转移,表示转移
细节:XX
算法:CCA训练的跨语言词向量:用于学习兼容的数据表示,从而使得学到的策略可以轻松地迁移到其他语言。具体使用的是CCA训练的40维跨语言词向量,在训练策略和模型时固定这些词向量。条件随机场/RNN分类器(分类)
7. Neural Cross-Lingual Named Entity Recognition with Minimal Resources
文章核心观点:
这篇文章主要介绍了一种基于神经网络的跨语言命名实体识别方法。文章的主要贡献包括: 1. 提出了一种新的词汇映射方法,通过双语词嵌入的共享空间来找到词汇翻译,同时避免了词嵌入空间完全对齐的困难,并获取了字符级信息。 2. 引入自注意力机制来提高模型对词序差异的鲁棒性,使模型能够处理源语言和目标语言之间词序的差异。 3. 在常用测试语言上取得了state-of-the-art或竞争性结果,并使用较少的资源。还评估了该方法在低资源语言维吾尔语上的应用。 4. 与基于词典的翻译方法相比,该方法取得了更好的效果,证实了其有效性。 5. 通过消融实验证明了词汇翻译的优势,以及目标语言字符序列的重要性。 6. 在低资源语言维吾尔语上取得了竞争性结果,展示了方法的实用性。 总的来说,文章提出了有效的跨语言命名实体识别方法,利用共享词嵌入空间和自注意力机制,取得了竞争性的跨语言结果。
摘要:不同语言之间的单词和词序差异阻碍跨语言迁移。提出了一种基于双语单词嵌入的翻译查找方法,为了提高对词序差异的鲁棒性,我们建议使用自注意力机制,这允许在词序方面有一定的灵活性。
挑战:由于不同语言具有不同的语言特性,很难,甚至不可能完美对齐两个嵌入空间。同时,由于表面形式不可用,无法使用字符级特征,导致标记准确性降低
方法:为了解决上述问题,我们提出了一种新的词汇映射方法,结合了离散词典方法和连续嵌入方法的优势(具体而言,我们首先将不同语言的嵌入投影到共享的BWE空间中,然后通过在这个投影空间中寻找最近邻来学习离散单词翻译,最后在翻译数据上训练模型。这使我们的方法能够继承嵌入方法和词典方法的优势:它的资源需求像前者一样低,但它受到嵌入空间不对齐的影响较小,并且像后者一样可以访问字符级信息)。我们的第二个贡献是通过将顺序不变的自注意力机制(Vaswani等人,2017年;Lin等人,2017年)纳入我们的神经架构来缓解这个问题。自注意力允许在特定编码序列内重新排序信息,这使得能够考虑到源语言和目标语言之间的词序差异。
相关工作:
不足:
语言:英语 (en)、德语 (de)、西班牙语 (es) 和荷兰语 (nl)
数据集:CoNLL2002/2003
任务:多语言命名实体识别
转移资源:multilingual word embeddings, Bilingual dictionary
转移范例:标签转移
细节:通过上述方法得到基于嵌入的翻译模型,由翻译模型得到目标语言数据后训练加入自注意力机制的NER模型(Bi-LSTM-CRF)
资源:
单语语料库:用于学习源语言和目标语言的词向量。
双语词典:作为种子词典,用于投影两种语言的词向量到一个共享空间,并找出词对之间的翻译。
共享词向量空间:通过优化词向量对齐,将源语言和目标语言的词向量投影到共享空间。
自注意力机制:引入自注意力层以增强模型对词序差异的鲁棒性。
字符级特征:在翻译后的目标语言数据上训练命名实体识别模型时,使用目标语言的字符序列作为模型输入的一部分。
翻译数据:将源语言训练数据翻译成目标语言,同时保留源语言中的命名实体标签,用于训练目标语言的命名实体识别模型。
一些心得
早期方法:大多采用标签转移将多语言问题转化为单语言问题,少数[7]对单语言方法进行了调整
2019~2020
8. Entity Projection via Machine-Translation for Cross-Lingual NER
文章核心观点
这篇文章介绍了一种利用机器翻译进行跨语言命名实体识别(NER)的实体投影方法。具体包括以下内容: 1. 使用机器翻译系统将源语言的注释数据集翻译成目标语言,得到未标注的目标语言数据集。 2. 通过实体对齐和标签投影,将源语言数据集中的实体及其标签映射到目标语言数据集。实体对齐通过词级匹配、构建候选实体匹配对等方法实现。标签投影则将源语言实体的标签直接映射到对齐的目标语言实体。 3. 实验证明,该方法在西班牙语、德语、汉语、印地语和泰米尔语上的跨语言NER性能优于之前的最优方法,并达到了Armenian语言的最优状态。分析显示,该方法有效减少错误标注,提高实体对齐质量。 4. 该方法不依赖平行语料,只利用了机器翻译系统和双语词典等通用资源,具有较好的可移植性。随着机器翻译质量的提高,该方法有潜力进一步提升跨语言NER性能。
摘要:尽管超过100种语言得到了强大的现成机器翻译系统的支持,但其中只有一部分语言拥有用于命名实体识别的大型注释语料库。受到这一事实的启发,我们利用机器翻译来改进跨语言命名实体识别的注释投影方法。我们提出了一个系统,通过以下方式改进了以前的实体投影方法:(a) 利用机器翻译系统两次:首先用于翻译句子,然后用于翻译实体;(b) 基于正字法和音系相似性匹配实体;以及 (c) 基于从数据集中得出的分布统计信息识别匹配项。我们的方法在5种不同语言上改进了当前最先进的跨语言命名实体识别方法,平均提高了4.1个百分点。此外,我们的方法在亚美尼亚语上取得了最先进的F1分数,甚至超过了在亚美尼亚语源数据上训练的单语言模型。© 2019 计算语言学协会。
挑战:XX
方法:谷歌翻译源数据集中的每个句子翻译到目标语言
相关工作:
语言:西班牙语(es)、荷兰语(nl)、德语(de)、印地语(hi)、泰米尔语(ta)、简体中文(zh)
数据集:CoNLL 2002、CoNLL 2003、FIRE 2013、OntoNotes 4.0
任务:多语言命名实体识别
转移资源:平行语料库,Machine translation(谷歌翻译),Language features(基于正字法和音系相似性匹配实体),Universal features(词频统计),字典
转移范例:标签转移
算法:Bi-LSTM-CRF + self-attention layer
资源:机器翻译系统:利用Google Translate将源语言(英语)的NER数据集翻译成目标语言的数据集,以获取目标语言的无标注数据集。
双语词典:使用MUSE双语词典来获取源语言实体的潜在翻译,并将其添加到候选翻译集合中。
国际音标转换工具:利用Epitran工具将源语言和目标语言的词汇转换为国际音标(IPA),并进行语音匹配。
目标语言的验证集:用于微调模型的超参数。
公开的双语平行语料库:用于评估不同投影方法的效果,如使用Europarl英语-西班牙双语语料库和IIT Bombay英语-印地语双语语料库。
9. Polyglot Contextual Representations Improve Crosslingual Transfer
文章核心观点:
这篇文章介绍了一种名为Rosita的方法,用于生成多语言上下文词表示。Rosita方法通过在多语言语料上训练单一语言模型来实现。文章进行了跨语言转移实验,比较了单语言和多语言模型在依存句法分析、语义角色标注和命名实体识别任务上的表现。结果显示,多语言上下文词表示优于单语言表示,即使在语言差异较大的情况下,如中文到阿拉伯语,多语言模型仍能提供额外的收益。这项研究为多语言表示学习提供了有价值的证据。
挑战:
方法:ELMo方法(使用字符CNN对每个词进行编码)、词级LSTM(处理上下文中的词)

相关工作:
语言:英语、繁体中文、简体中文、阿拉伯语
数据集:CoNLL 2012、Ontonotes 2013
任务:多语言命名实体识别
转移资源:参数转移
转移范例:Pre-trained multilingual language models
算法:BiLSTM-CRF NER model with the BIO tagging scheme
10. MAD-X: An Adapter-Based Framework for Multi-Task Cross-Lingual Transfer
摘要:多语言BERT和XLM-R等最新预训练多语言模型背后的主要目标是通过零样本或少样本的跨语言迁移,在低资源语言中实现NLP应用的启用和引导。然而,由于模型容量有限,它们的迁移性能在这些低资源语言和预训练期间未见过的语言上恰恰是最弱的。我们提出了MAD-X,这是一个基于适配器的框架,通过学习模块化的语言和任务表示,实现了对任意任务和语言的高可移植性和参数高效迁移。此外,我们引入了一种新颖的可逆适配器架构和一种强大的基线方法,用于将预训练的多语言模型适配到新的语言。MAD-X在命名实体识别和因果常识推理的跨语言迁移上超越了最先进的技术。
挑战:见摘要
方法:
在本文中,我们提出了一种用于跨语言迁移的多个适配器(MAD-X),这是一个模块化的框架,利用少量额外的参数来解决限制预训练多语言模型的基本容量问题。以最先进的多语言模型为基础,我们通过学习适配器(Rebuffi等人,2017年;Houlsby等人,2019年)中的模块化语言和任务特定表示,将模型适应于任意任务和语言,适配器是插入模型权重之间的小瓶颈层。特别地,使用最近高效的适配器变体(Pfeiffer等人,2020a;Ruckl¨等人,2020年),我们训练1)通过在未标记的目标语言数据上进行掩蔽语言建模(MLM)来训练语言特定的适配器模块,以及2)通过在任何源语言的标记数据上优化目标任务来训练任务特定的适配器模块。任务和语言适配器如图1所示堆叠,允许我们将预训练的多语言模型适应于模型的(预)训练数据中未涵盖的语言,通过在推理时替换目标语言适配器。
为了处理共享的多语言词汇和目标语言词汇之间的不匹配问题,我们提出了可逆适配器,这是一种新型适配器,非常适合在另一种语言中执行MLM。我们的框架超越了以往使用适配器进行跨语言迁移的工作(Bapna和Firat,2019年;Artetxe等人,2020年),通过使得在预训练期间未见的语言适应成为可能,且无需学习昂贵的语言特定的标记级嵌入。
我们工作的另一个贡献是提出了一种简单的方法,将预训练的多语言模型适应于新的语言,这比仅从标记的源语言数据转移模型的标准设置表现得更好。
总之,我们的贡献如下。1)我们提出了MAD-X,一个模块化框架,缓解了多语言性的诅咒,并将多语言模型适应于任意任务和语言。代码和适配器权重都集成到了AdapterHub.ml存储库(Pfeiffer等人,2020b年)。2)我们提出了可逆适配器,这是一种新的跨语言MLM适配器变体。3)我们展示了MAD-X在多样化的语言和任务上的强性能和鲁棒性。4)我们提出了一种简单而更有效的基线方法,用于将预训练的多语言模型适应于目标语言。5)我们揭示了当前方法在多语言预训练期间未见的语言上的行为。
相关工作:通用跨语言表示(单词->句子)
不足:XX
语言: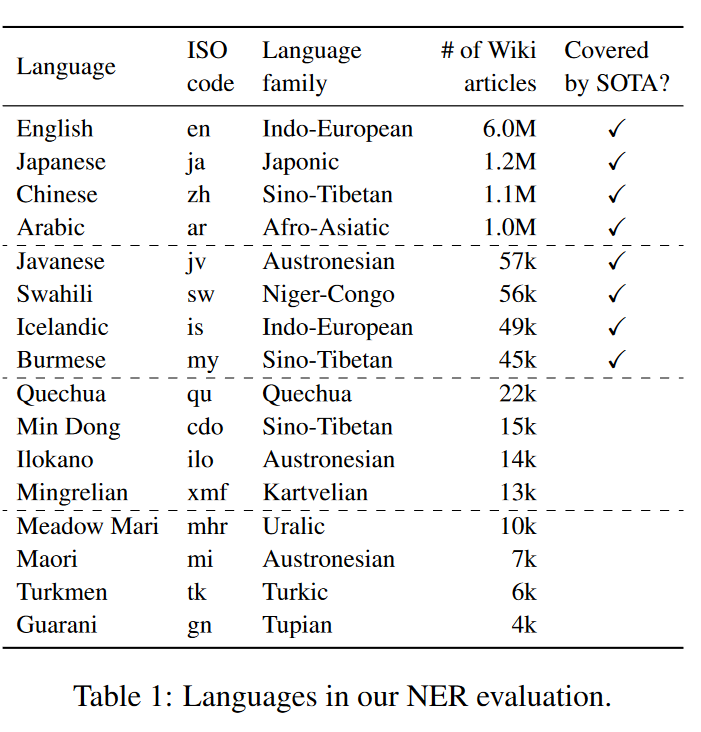
数据集:WikiANN
任务:多语言命名实体识别
转移资源:Pre-trained multilingual language models
转移范例:参数转移
细节:
使用最先进的大型多语言模型(如多语言BERT或XLM-R)进行跨语言迁移的标准方法是 1) 在源语言的下游任务的标记数据上对其进行微调,然后 2) 直接应用它在目标语言上进行推理(Hu等人,2020年)。这种设置的一个缺点是多语言初始化平衡了许多语言。因此,它不适合在推理时擅长特定语言。我们提出了一个简单的方法来改善这个问题,允许模型额外进行目标语言适应。
与在任务域上对单语言模型进行微调类似(Howard和Ruder,2018年),我们提议在源语言的特定任务微调之前,通过目标语言的未标记数据对预训练的多语言模型进行MLM微调。
结论:我们提出了MAD-X,一个用于跨任务和语言迁移的通用模块化框架。它利用少量额外的参数来缓解根本阻碍当前多语言模型的容量问题。MAD-X与模型无关,可以作为任何当前预训练多语言模型的基础进行适配。我们已经展示了它对于适应多语言模型训练模型未涵盖的语言特别有用,同时在资源丰富的语言上也取得了有竞争力的性能。在未来的工作中,我们将把MAD-X应用到其他预训练模型上,并使用特别适用于具有某些特性的语言的适配器(例如,使用不同文字系统的语言)。我们还将评估额外的任务,并研究利用来自相关语言的预训练语言适配器,以改善对真正低资源语言的迁移,这些语言的单语言数据有限。
算法:MAD-X + XLM-R
2021~2022
11. MulDA: A multilingual data augmentation framework for low-resource cross-lingual NER
文章核心观点:
这篇文章提出了一种名为MulDA的多语言数据增强框架,旨在提升低资源跨语言命名实体识别的性能。主要内容包括: 1. 提出了一种标签化序列翻译方法,将源语言训练数据翻译成目标语言,避免了许多词对齐问题,如词序变化和实体跨度确定。 2. 引入了一种基于生成的多语言数据增强方法,利用多语言语言模型生成更多样化的训练数据。 3. 通过大量实验证明,在低资源跨语言命名实体识别任务中,翻译成更多目标语言可以作为一种有效的数据增强方法,有助于提升源语言和目标语言的性能。 4. 在多种低资源设置下进行了广泛实验,结果显示该方法可显著提高跨语言命名实体识别的性能。 5. MulDA框架有效利用了预训练的多语言语言模型的跨语言迁移能力,为低资源跨语言命名实体识别提供了有效的解决方案。
挑战:1. 大多数方法假设源语言中有相当数量的训练数据可用。当我们减少训练数据的大小时,我们观察到性能显著下降。2. 减少训练集大小也会放大MT和标签投影引入的噪声的负面影响。 3. 对于基于模型的迁移,预训练模型在一个小的训练集上简单地微调它们容易导致过拟合
方法:具体来说,我们考虑了一个跨语言NER的低资源设置,其中源语言训练数据非常有限,且没有目标语言的训练/开发数据。
- 我们首先引入了一种新颖的标记序列翻译方法,将训练数据翻译成目标语言以及其他语言。这使我们能够在多语言数据上微调基于语言模型的NER模型,而不是仅在源语言数据上,这有助于防止过度拟合语言特定特征。
- 需要注意的是,基于实例的迁移方法为训练集添加的语义多样性有限,因为它们只将实体及其对应的上下文翻译成不同的语言。相比之下,数据增强已被证明是解决数据稀缺问题的成功方法。受到最近一种单语言数据增强方法的启发,我们提出了一种基于生成的多语言数据增强方法来增加多样性,其中语言模型在多语言标记数据上进行训练,然后用于生成更多的合成训练数据。
方法细节:1. 在翻译方法中用占位符替代实体,这样可以避免部分翻译过程中的词序转换。2. 在实体周围加上括号标记,这样即使词序转变后也可以找到翻译后的实体。3. 数据增强方法:提出DAGA(Ding等人,2020年)的多语言版本 4. 实现的是翻译和数据增强方法,分别在LSTM-LM和mBART模型测试。
相关工作:
不足:
语言:English, German, Dutch and Spanish
数据集:CoNLL-02/03
任务:多语言命名实体识别
转移资源:Machine translation,pre-trained
转移范例:标签转移
算法:MulDA + LSTM-LM/mBART
资源:
机器翻译(MT)系统:用于将源语言的训练数据翻译成目标语言,包括Google翻译系统和MarianMT模型。这有助于生成目标语言的标注数据。
预训练的多语言语言模型(LM):如mBART,用于在多语言数据上生成更多样化的训练数据,从而增强跨语言转移的效果。
12. Small Data? No Problem! Exploring the Viability of Pretrained Multilingual Language Models for Low-Resource Languages
摘要:预训练的多语言模型已被证明在许多语言上对各种下游自然语言处理(NLP)任务都非常有效。然而,这些模型被知晓需要大量的训练数据。这因此使得世界上很大一部分资源较少的语言被排除在外。此外,这些模型背后的一个主要动机是,低资源语言能够从与高资源语言的联合训练中受益。在这项工作中,我们挑战这一假设,并提出了首次尝试仅在低资源语言上训练多语言模型。我们展示了在不到1GB文本的情况下训练有竞争力的多语言模型是可能的。我们的模型,名为AfriBERTa,涵盖了11种非洲语言,包括这4种语言的首个语言模型。在命名实体识别和文本分类上的评估跨越了10种语言,显示我们的模型在多种语言上超过了mBERT和XLM-R,总体上非常有竞争力。结果表明,我们基于相似语言的“小数据”方法有时可能比在大数据集上与高资源语言联合训练更为有效。代码、数据和模型已在https://github.com/keleog/afriberta发布。© 2021 计算语言学协会。
挑战:目前还没有已知的尝试去研究是否可能仅在低资源语言上预训练多语言语言模型,而不从高资源语言进行任何迁移。
方法:我们介绍了AfriBERTa,这是一个基于变压器的多语言语言模型,它在11种非洲低资源语言上进行了训练。我们在包含所有语言的文本数据上进行预训练,从不同语言中采样批次。我们采样语言的方式是让模型在连续的几个批次中看不到同一种语言。我们使用SentencePiece(Kudo和Richardson,2018年)对原始文本数据进行子词分词,该工具是使用单语言模型(Kudo,2018年)训练的。我们根据Conneau和Lample(2019年)描述的采样方法,以α=0.3从不同语言中采样训练句子供分词器使用。
不足:
相关工作:
语言:阿姆哈拉语、豪萨语、伊博语、基尼亚卢旺达语、卢干达语、卢奥语、尼日利亚皮钦语、斯瓦希里语、沃洛夫语和约鲁巴语
数据集:MasakhaNER
任务:多语言命名实体识别
转移资源:Pre-trained multilingual language models
转移范例:参数转移
算法:AfriBERTa
13. MAD-G: Multilingual Adapter Generation for Efficient Cross-Lingual Transfer
文章核心观点:
这篇文章介绍了一种名为MAD-X的框架,用于跨语言迁移学习。该框架通过增加少量的额外参数,有效扩展了预训练的跨语言模型,使其能够更好地适应不同的语言和任务。该框架包含三种适配器:语言适配器、任务适配器和可逆适配器。通过学习模块化的语言和任务表示,该框架实现了高可移植性和参数效率。在实验中,该框架在NER、因果常识推理和问答等任务上表现良好,特别擅长处理预训练时未见过的语言。总体来说,MAD-X为扩展预训练跨语言模型提供了有效的框架,可以广泛应用于不同语言和任务。
挑战:适配器作为一种参数高效的方式,用于将多语言模型扩展到代表性不足的语言。通常的做法是通过掩码语言建模(MLM)在每种语言的未标记数据上训练一个语言适配器(Pfeiffer等人,2020b)。然而,这通常需要大量的单语数据,这阻止了适配器服务于资源不足的语言,在这些语言中,这种额外的特定于语言的能力将是最有用的。
方法:
为了解决这种不足,我们提出了多语言适配器生成(MAD-G),这是一种新的范式,通过跨语言共享信息,使得能够为低资源语言生成适配器。MAD-G不是为每种语言学习单独的适配器,而是利用上下文参数生成(CPG;Platanios等人,2018a;Ponti等人,2019b),也就是,它学习一个能够为任意目标语言生成语言适配器的单一模型。MAD-G的核心是一个上下文参数生成器,它将一种语言的类型学向量作为输入,并输出特定语言适配器的参数。生成器的参数是通过在95种语言的维基百科上进行MLM训练得到的,这些语言被选择是为了最大化语言多样性。与以前的CPG工作(Platanios等人,2018a;Üstün等人,2020年)不同,MAD-G生成的是任务不可知的适配器,从而允许在所有领域内进行高效和模块化的跨语言迁移,即,MAD-G语言适配器可以被用于任意下游任务(Pfeiffer等人,2020b)。
MAD-G通过以下两种方式在语言之间共享信息:(i)在隐藏表示的层面上,通过共享适配器生成器的参数;(ii)在类型学层面上,通过基于URIEL数据库(Littell等人,2017年)的特征进行条件化。后者还额外实现了对未见过的语言的零样本迁移。此外,我们提出了MAD-G的一个变体,其中我们还根据适配器的变换器层位置生成适配器(见第3.2节),使得MAD-G比以往的基于适配器的迁移方法更具参数效率。
语言适配器是一个轻量级的组件,被插入到如mBERT(Devlin等人,2019年)或XLM-R(Conneau等人,2020年)的MMT中,目的是使MMT专门用于特定语言,以便要么(a)支持MMT原始多语言预训练未涵盖的新语言(Pfeiffer等人,2020b;Artetxe等人,2020年)要么(b)恢复/提高特定(资源丰富的)语言的性能(Bapna和Firat,2019年;Rust等人,2021年)。
不足:
语言:95 languages
数据集:Wikipedias of 95 languages,CoNLL 2003
任务:多语言命名实体识别
转移资源:Pre-trained multilingual language models
转移范例:参数转移
算法:
X. SemEval-2022 Task 11: Multilingual Complex Named Entity Recognition (MultiCoNER)
评测(部分):DAMO-NLP(王等人,2022年)在多语言(MULTI)赛道以及除BN(第2名)和ZH(第4名)之外的所有单语种赛道中均排名第一。给定一段文本,他们使用一个知识检索模块从知识库(即维基百科)中检索出K个最相关的段落。段落与输入一起连接,并且标记表示通过条件随机场(CRF)传递以预测标签。他们使用了多个具有随机种子的XLMRoBERTa模型,然后使用投票策略进行最终预测。USTC-NELSLIP(陈等人,2022a)在三个赛道(MIX、ZH、BN)中排名第一,在其他所有赛道中排名第二。USTC-NELSLIP和DAMO-NLP在所有13个赛道上的平均性能差距约为3%。USTC-NELSLIP的目标是对地理名录增强的双向长短期记忆网络(BiLSTM)进行微调,使得为实体产生的表示与预训练语言模型(LM)产生的表示具有相似性。他们开发了一个两步过程和两个并行网络,其中一个地理名录-BiLSTM使用地理名录搜索为给定文本中的每个标记产生一个热标签,而BiLSTM为每个标记产生一个密集向量表示。另一个网络使用冻结的XLM-RoBERTa为每个标记产生一个嵌入向量。应用KL散度损失,使地理名录网络的输出与LM相似。这两个网络再次一起联合训练,它们的输出融合在一起进行最终预测。QTrade AI(甘等人,2022年)在MULTI中排名第三,在MIX中排名第四,在ZH中排名第八。他们使用XLM-RoBERTa编码器,并应用样本混合进行数据增强,以及通过数据噪声化的对抗性训练。对于多语言赛道,他们利用了具有共享和每种语言表示的架构。最后,他们创建了一个通过不同方法训练的模型集成。SeqL(哈桑等人,2022年)在MULTI中排名第四,在MIX中排名第五。他们训练了七个XLM-RoBERTa-large和Infoxlm-large模型,然后使用投票和分数融合的集成方法来预测最终标签。他们发现集成方法略优于最佳单一模型,分数融合比简单投票效果更好。CMB AI Lab(PU等人,2022年)在MULTI中排名第五,在MIX中排名第三,在KO中排名第四,在ZH中排名第六。他们首先使用双亲层来识别句子中潜在的实体跨度,然后提取的跨度由另一个分类器处理以获得它们的类别标签。最后,通过结合不同的预训练编码器和基于原始训练数据翻译的数据增强技术创建了一个集成。在预训练语言模型方面,他们使用了XLM-RoBERTa和mT5。
建模方法:几乎所有参赛系统都依赖于公开可用的基于Transformer(Vaswani等人,2017年)的预训练语言模型(表5)。XLM-RoBERTa(也称为XLM-R)是构建多语言模型最受欢迎的选择。参加非英语单语种赛道的大多数团队倾向于使用这个特定的模型,而不是BERT的多语言变体。其他近期的语言模型,如T5、ELECTRA、XLNet和ALBERT也被一些团队使用,但主要用于英语。我们观察到,对于非英语语言,许多团队使用了社区开发的其他语言的预训练模型,如中文、印地语、西班牙语、韩语、孟加拉语、土耳其语、俄语、波斯语、荷兰语和德语。这些模型大多数是使用BERT架构和相应语言的数据进行训练的。很多团队依赖于条件随机场(CRF;Lafferty等人,2001年)在序列标注问题上的强大性能,并采用它以获得更强的性能。很少有团队使用像LSTMs这样的架构。大多数仅仅对预训练语言模型进行微调的团队在大多数赛道上的表现与基线系统相似。除了前面提到的外部数据的作用外,另一个对强性能至关重要的组成部分是使用集成学习策略。几乎所有表现强劲的团队都训练了多个模型,并将它们集成在一起以进行最终预测。我们还观察到一些团队尝试使用对抗性训练和强化学习。
2023~2024
X. SemEval-2023 Task 2: Fine-grained Multilingual Named Entity Recognition (MultiCoNER 2)
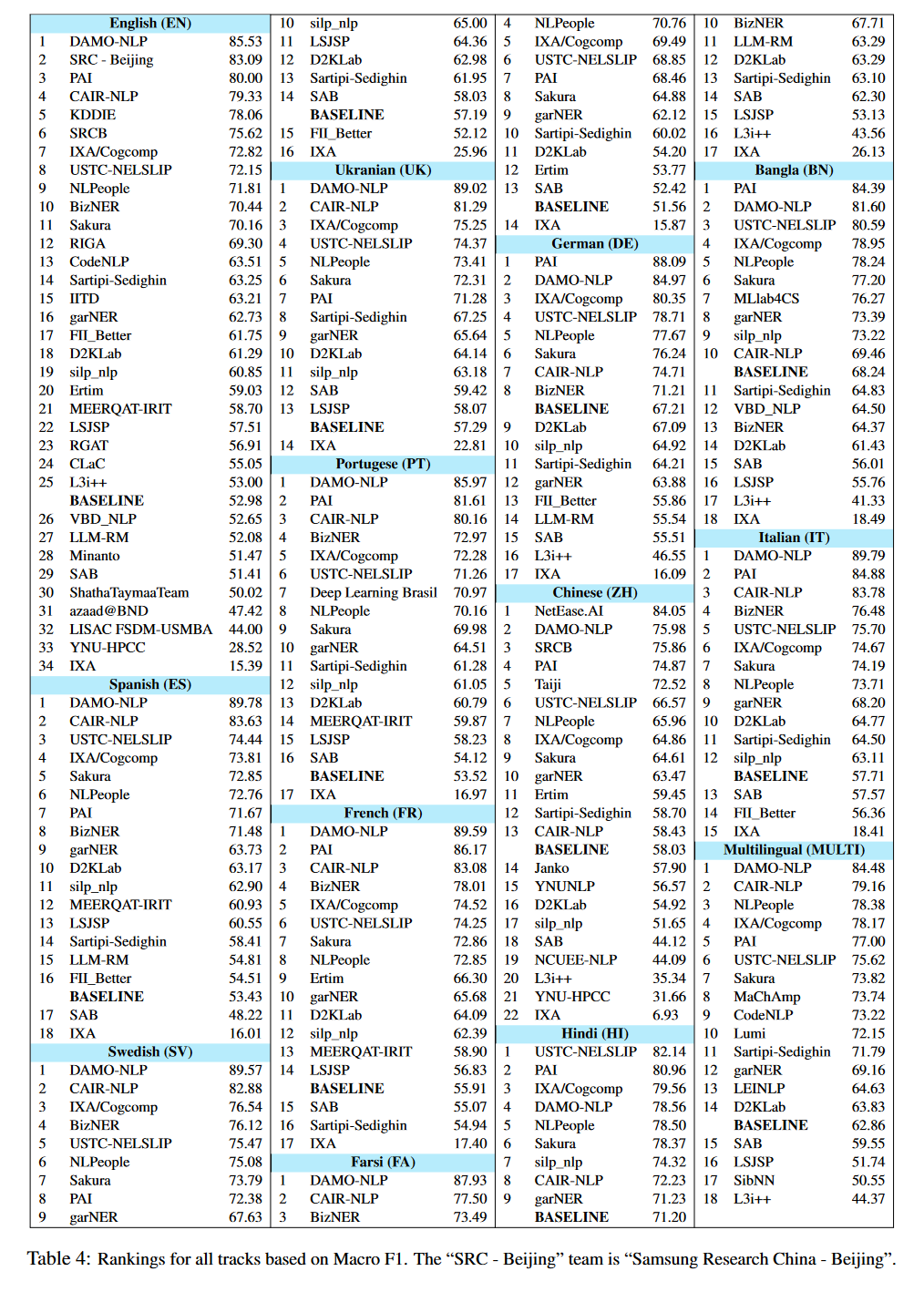
评测(部分):DAMO-NLP(Tan等人,2023年)在大多数赛道中排名第一,除了在BN、DE、ZH和4个基线中排名第二,在HI中排名第四。他们为这项任务提出了一个统一的检索增强系统(U-RaNER)。该系统使用两种不同的知识来源(维基百科段落和Wikidata知识图谱)向他们的命名实体识别(NER)模型注入额外的相关知识。此外,他们探索了一种注入方法,向模型提供关于实体的更广泛的上下文知识。PAI(Ma等人,2023b)在BN、DE中排名第一,在FR、HI中排名第二,在EN、ZH中排名第三,在MULTI中排名第四,在ES、FA、UK和SV中排名第七,在PT中排名第八。他们使用来自Wikidata的实体及其相关属性(如“instanceof”、“subclassof”和“occupation”)开发了一个知识库。对于给定的句子,他们使用检索模块通过字符串匹配收集实体的不同属性。他们通过字典融合方法在干净子集上观察到了好处。在嘈杂子集上没有观察到同样的好处。USTC-NELSLIP(Ma等人,2023a)在HI中排名第一,在BN、ES中排名第三,在DE、UK中排名第四,在IT、SV中排名第五,在FA、FR、PT、ZH、MULTI中排名第六,在EN中排名第八。他们提出了一个两阶段训练策略。在第一阶段,通过最小化他们之间表示的KL散度,调整地理名录网络和语言模型在句子和实体层面的表示。在第二阶段,两个网络一起在NER目标上进行训练。最终预测来自多个训练模型的集成。结果表明,地理名录在NER过程中准确识别复杂实体中发挥了关键作用,实施两阶段训练策略是有效的。NetEase.AI(Lu等人,2023年)在ZH中排名第一。他们提出的系统由多个模块组成。首先,使用BERT模型纠正原始输入句子中的任何潜在错误。NER模块以校正后的文本为输入,包括一个基本的NER模块和一个地理名录增强的NER模块。这种方法提高了在实体级别噪声上的性能,并使系统在其他团队中获得了明显优势(表11)。检索系统以候选实体为输入,检索额外的上下文信息,随后用作文本分类模型的输入,以计算实体类型标签的概率。一个堆叠模型被训练,根据多个模块的特征输出最终预测。
多语言模型:在多语言赛道中,大多数参与者选择使用任务的基线模型,XLM-RoBERTa。此外,一些参与者还使用了mLUKE、mDEBERTA和mBERT。在外部多语言资源方面,参与者主要使用了维基百科。
14. Improving Self-training for Cross-lingual Named Entity Recognition with Contrastive and Prototype Learning
摘要:在跨语言命名实体识别(NER)中,自训练通常被用来通过在伪标签的目标语言数据上进行训练来弥合语言差距。然而,由于在目标语言上的性能不是最优的,伪标签通常是有噪声的,限制了整体性能。在这项工作中,我们旨在通过结合表示学习和伪标签细化在一个连贯的框架中来改进跨语言NER的自训练。我们提出的方法,即ContProto,主要包括两个组成部分:(1)对比自训练和(2)基于原型的伪标签。我们的对比自训练通过分离不同类别的簇来促进跨度分类,并通过网络源语言和目标语言之间紧密对齐的表示来增强跨语言可转移性。同时,基于原型的伪标签在训练期间有效提高了伪标签的准确性。我们在多个迁移对上评估ContProto,实验结果表明我们的方法相较于当前的最先进方法带来了显著的改进。© 2023 计算语言学协会。
挑战:跨语言命名实体识别(NER)(Tsai等人,2016年;Xie等人,2018年)自从大规模多语言预训练语言模型出现以来(Devlin等人,2019年;Conneau等人,2020年),已经看到了显著的性能提升。然而,在零样本跨语言迁移和使用目标语言标记数据训练的单语言NER模型之间,仍然存在明显的差距。为了进一步弥合源语言和目标语言之间的语言差异,自训练(有时称为师生学习)被广泛采用,以利用未标记目标语言数据中丰富的语言特定信息(Wu等人,2020b;Ye等人,2020;Chen等人,2021)。使用在源语言数据上训练的弱标记器(即教师模型)为未标记的目标语言数据分配伪标签,然后与标记的源语言数据结合,训练最终模型(即学生模型)。然而,由于在目标语言上的表现不佳,伪标签数据包含大量错误,可能会限制在这些数据上训练的NER模型的性能。
解决伪标签的方法通过强化学习(Liang等人,2021a)或对抗性鉴别器(Chen等人,2021)选择用于自训练的策划伪标签数据。然而,它们没有充分利用所有可用的未标记数据。Wu等人(2020a,b)利用完整的未标记数据集,并通过从多个教师模型聚合预测来减轻伪标签中的噪声。同样,Liang等人(2021a)开发了多轮自训练,迭代地重新训练教师模型以生成更准确的伪标签。尽管它们有效,但多教师和多轮自训练都带来了巨大的计算开销。
方法:提出了ContProto作为跨语言NER的新型自训练框架。与现有的数据选择方法不同,ContProto充分利用了所有可用的未标记目标语言数据的知识。与多教师或多轮自训练相比,我们的方法在不训练单独的模型的情况下提高了伪标签的质量。此外,我们明确对齐源语言和目标语言的表示,以增强模型的跨语言迁移能力。具体来说,ContProto包括两个关键组件,即对比自训练和基于原型的伪标签。首先,我们为跨语言NER自训练引入了一个对比目标。虽然典型的监督对比学习(Khosla等人,2020)将同一类别的标记实体视为正样本对,我们进一步构建了由标记的源语言实体和当前模型预测为同一实体类型的目標语言跨度组成的伪正样本对。因此,这种对比目标不仅将不同的实体类别分开以便于分类,而且还更好地对齐了源语言和目标语言的表示,实现了增强的跨语言迁移能力。其次,我们提出了一种基于原型的伪标签,以在每个训练步骤中实时完善伪标签。我们首先根据对比自训练产生的表示构建特定于类别的原型,可以将其视为每种实体类型的聚类质心。然后,通过比较未标记跨度的表示与每个原型之间的距离,我们逐渐将其软伪标签转向最接近的类别。结果,在训练过程中动态纠正了伪标签中的错误。值得注意的是,我们对比自训练和基于原型的伪标签是相互有益的。一方面,对比学习生成的实体聚类使得确定最近的原型并正确更新伪标签变得更加容易。反过来,当在细化的伪标签上训练时,模型在分类未标记跨度时变得更加准确,并为对比学习产生更可靠的正样本对。我们的贡献总结如下:(1)所提出的ContProto显示出有竞争力的跨语言NER性能,在大多数评估的跨语言迁移对(六个中的五个)上建立了新的最先进的结果。(2)我们的对比自训练为每个类别产生清晰分离的表示聚类,以便于分类,并且还对齐了源语言和目标语言,以实现改进的跨语言迁移能力。(3)我们的基于原型的伪标签有效地去噪了伪标签数据,并极大地提高了自训练的性能。
语言:en,de,es,nl,ar,hi,zh
数据集:CoNLL2002/2003,WikiAnn
任务:多语言命名实体识别
转移资源:Pre-trained multilingual language models
转移范例:标签转移
15. Cross-Lingual Named Entity Recognition Based on Attention and Adversarial Training
摘要:命名实体识别旨在从非结构化文本中提取具有特定意义的实体。目前,深度学习方法已被广泛用于这项任务,并取得了显著的成果,但在标签数据较少的情况下往往难以取得更好的结果。为了解决这个问题,本文提出了一种基于注意力机制和对抗训练的跨语言实体识别方法,使用资源丰富的语言注释数据迁移到低资源语言的命名实体识别任务,并通过注意力机制输出变化的语义向量,有效解决了长序列语义稀释问题。为了验证所提出方法的有效性,本文中的方法被应用于基于WeiboNER数据集和People-Daily2004数据集的英汉跨语言命名实体识别任务。所获得的最佳模型的F1值为53.22%(比基线提高了6.29%)。实验结果表明,本文提出的跨语言对抗命名实体识别方法可以显著提高低资源语言命名实体识别的结果。© 2023 作者。
方法:提出了一种基于对抗训练的跨语言情况下的命名实体识别框架。首先,通过M-BERT将源语言和目标语言转换为词向量,然后反向融合自注意力机制,将从英语预训练命名实体识别模型中提取的信息转换为中文,加强关键信息的表示,使用源语言对NER模型进行微调,并使用源语言和目标语言的标签数据进行对抗训练,以提高模型在两种语言之间的对齐能力。然后,使用模型推断目标语言,测试模型对提高目标语言中的实体识别效果。
数据集:WeiboNER和People-Daily2004数据集、Conll2003
语言:English->Chinese
任务:多语言命名实体识别
转移资源:Pre-trained multilingual language models
转移范例:标签转移
16. Dataset Enhancement and Multilingual Transfer for Named Entity Recognition in the Indonesian Language
摘要:近年来,印度尼西亚语的命名实体识别(NER)已显著发展。然而,它仍然缺乏标准化的公开语料库;虽然有一个小型数据集可用,但存在注释不一致的问题。因此,我们重新注释了该数据集,以提高其一致性并惠及社区。我们的重新注释使得由双向长短期记忆(BiLSTM)和条件随机场(CRF)组成的有效基线模型获得了更好的训练结果。为了充分利用有限的可用数据,我们通过利用单语和多语预训练语言模型(如IndoBERT和XLM-RoBERTa)实现了更好的语境化并转移了外部知识。除了语言模型带来的一般性改进外,我们还观察到单语模型更为敏感,而多语模型在丰富的形态知识方面显示出优势。我们还应用了跨语言迁移学习,以利用其他语言中的高资源语料库。我们将英语、西班牙语、荷兰语和德语作为目标印尼语的源语言,并发现由于历史原因导致的形态学相似性,荷兰语在数据转移方法中扮演了特殊角色。© 2023 版权由所有者/作者持有。
数据集:
语言:
任务:多语言命名实体识别
转移资源:Pre-trained multilingual language models
转移范例:参数转移
15. DAMO-NLP at SemEval-2023 Task 2: A Unified Retrieval-augmented System for Multilingual Named Entity Recognition
摘要:MultiCoNER II共享任务旨在解决多语言命名实体识别(NER)中的细粒度和嘈杂场景问题,并且继承了MultiCoNER I任务的语义歧义和低上下文设置。为了应对这些问题,MultiCoNER I中的先前顶级系统要么整合了知识库,要么使用了地名词典。然而,它们仍然受到知识不足、上下文长度有限、单一检索策略的困扰。在本文中,我们的团队DAMO-NLP提出了一个统一的检索增强系统(U-RaNER)用于细粒度的多语言NER。我们对先前的顶级系统进行了错误分析,并揭示了它们的性能瓶颈在于知识不足。同时,我们发现有限的上下文长度导致模型无法看到检索知识。为了增强检索上下文,我们整合了以实体为中心的Wikidata知识库,同时使用注入方法扩大了模型的上下文范围。此外,我们探索了各种搜索策略,并提高了检索知识的质量。我们的系统1在MultiCoNER II共享任务的13个赛道中赢得了9个。此外,我们将我们的系统与ChatGPT进行了比较,ChatGPT是解锁了多项任务强大能力的大语言模型之一。结果表明,ChatGPT在提取任务上仍有很大的改进空间。
挑战:MultiCoNER I任务的先前顶级系统在预训练语言模型中整合了额外的知识,包括知识库和地名词典,但是知识深度不足以及受到上下文长度限制的困扰。
方法:提出了一个统一的检索增强系统(U-RaNER)用于细粒度的多语言NER。我们使用维基百科和Wikidata知识库构建我们的检索模块,以便考虑更多样化的知识,利用注入方法为模型提供更广泛的上下文视图,从而更好地利用检索到的上下文。
语言:en,es,sv,uk,pt,fr,fa,de,zh,hi,bn,it
数据集:MultiCoNER v2
转移资源:Pre-trained multilingual language models
转移范例:参数转移
16. Multi-level multilingual semantic alignment for zero-shot cross-lingual transfer learning
摘要:最近,跨语言迁移学习已经引起了学术界和工业界的广泛关注。以往的研究通常只关注单级对齐(例如,词级、句子级),基于预训练的语言模型。然而,由于缺少层次语义信息(例如,句子到词、词到词)的相关性,这导致了在低资源语言的下游任务中的次优性能。因此,在本文中,我们提出了一种新颖的多级对齐框架,该框架通过利用精心设计的对齐训练任务,层次化地学习多个级别之间的语义关联。此外,我们设计了一种基于注意力的融合机制(AFM),以从高层次注入语义信息。在主流跨语言任务(例如,文本分类、释义识别和命名实体识别)上的广泛实验表明了我们提出方法的有效性,并且也显示出我们的模型在各种基准测试中与其他强基线相比,实现了最先进的性能。
挑战:大规模预训练语言模型主要是在资源丰富的语言(例如英语、中文)上进行预训练的,这导致在资源匮乏的语言(例如保加利亚语、印地语)上的下游任务表现不佳。考虑到资源匮乏训练语料的稀缺性和预训练的高成本,实际上很难为每种资源匮乏的语言从头开始训练一个特定的模型。以往的解决方案是将源语言(即资源丰富的语言)和目标语言(即资源匮乏的语言)之间的语义空间对齐。尽管这些单层对齐方法简单明了且易于实现,但由于缺乏层次语义信息的相关性,它们未能在目标语言上取得令人满意的性能。
方法:我们提出了一种新的多层次对齐范式,包括三个对齐层次(即语言、句子和单词级),其中对齐过程是从粗粒度逐渐进行到细粒度。首先,我们引入对抗学习(Goodfellow et al., 2014; Keung et al., 2019)通过对齐语言不可知特征来缩小两种语言的语义空间。其次,利用句子间和句子内的对比学习框架来减少源语言和目标语言的平行句子对之间的表示距离。最后,我们提出了两个单词级对齐任务(即掩蔽语言建模(MLM)(Devlin et al., 2019)和单词分布对齐),以对齐平行单词对之间的语义表示。此外,为了进一步加强不同层次语义之间的相关性,我们设计了一个基于注意力的融合机制(AFM)模块来整合来自更高层次的语义信息。
语言:en,ar,de,es,fr,ru,vi
数据集:PANX
转移资源:Pre-trained multilingual language models
转移范例:参数转移

 浙公网安备 33010602011771号
浙公网安备 33010602011771号