原型与原型链以及方法的存放
为什么有JavaScript有原型
私有变量和函数
在函数内部定义的变量和函数,如果不对外提供接口,外部是无法访问到的。
function School(){ var name = "GDUT"; var fn = function(){} } var obj = new School(); console.log(obj.name); //undefined console.log(obj.fn); //undefined
静态变量和函数
当定义一个函数后通过点号 “.”为其添加的属性和函数,通过对象本身仍然可以访问得到,但是其实例却访问不到,这样的变量和函数分别被称为静态变量和静态函数。
<script type="text/javascript"> function Obj(){}; Obj.num = 72;//静态变量 Obj.fn = function(){} //静态函数 alert(Obj.num);//72 alert(typeof Obj.fn)//function var t = new Obj(); alert(t.name);//undefined alert(typeof t.fn);//undefined </script>
实例变量和函数
在面向对象编程中除了一些库函数我们还是希望在对象定义的时候同时定义一些属性和方法,实例化后可以访问,js也能做到这样
<script type="text/javascript"> function Box(){ this.a=[]; //实例变量 this.fn=function(){} //实例方法 } console.log(typeof Box.a); //undefined console.log(typeof Box.fn); //undefined var box=new Box(); console.log(typeof box.a); //object console.log(typeof box.fn); //function </script>
为实例变量和方法添加新的方法和属性
<script type="text/javascript"> function Box(){ this.a=[]; //实例变量 this.fn=function(){} //实例方法 } var box1=new Box(); box1.a.push(1); box1.fn={}; console.log(box1.a); //[1] console.log(typeof box1.fn); //object var box2=new Box(); console.log(box2.a); //[] console.log(typeof box2.fn); //function </script>
在box1中修改了a和fn,而在box2中没有改变,由于数组和函数都是对象,是引用类型,这就说明box1中的属性和方法与box2中的属性与方法虽然同名但却不是一个引用,而是对Box对象定义的属性和方法的一个复制。
这个对属性来说没有什么问题,但是对于方法来说问题就很大了,因为方法都是在做完全一样的功能,但是却又两份复制,如果一个函数对象有上千和实例方法,那么它的每个实例都要保持一份上千个方法的复制,这显然是不科学的,这可肿么办呢,prototype应运而生。
基本概念
我们创建的每个函数都有一个prototype属性,这个属性是一个指针,指向一个对象,这个对象的用途是包含可以由特定类型的所有实例共享的属性和方法。那么,prototype就是通过调用构造函数而创建的那个对象实例的原型对象。
使用原型的好处是可以让对象实例共享它所包含的属性和方法。也就是说,不必在构造函数中添加定义对象信息,而是可以直接将这些信息添加到原型中。使用构造函数的主要问题就是每个方法都要在每个实例中创建一遍。
在JavaScript中,一共有两种类型的值,原始值和对象值。每个对象都有一个内部属性 prototype ,我们通常称之为原型。原型的值可以是一个对象,也可以是null。如果它的值是一个对象,则这个对象也一定有自己的原型。这样就形成了一条线性的链,我们称之为原型链。
含义
函数可以用来作为构造函数来使用。另外只有函数才有prototype属性并且可以访问到,但是对象实例不具有该属性,只有一个内部的不可访问的__proto__属性。__proto__是对象中一个指向相关原型的神秘链接。按照标准,__proto__是不对外公开的,也就是说是个私有属性,但是Firefox的引擎将他暴露了出来成为了一个共有的属性,我们可以对外访问和设置。
<script type="text/javascript"> var Browser = function(){}; Browser.prototype.run = function(){ alert("I'm Gecko,a kernel of firefox"); } var Bro = new Browser(); Bro.run(); </script>
当我们调用Bro.run()方法时,由于Bro中没有这个方法,所以,他就会去他的__proto__中去找,也就是Browser.prototype,所以最终执行了该run()方法。(在这里,函数首字母大写的都代表构造函数,以用来区分普通函数)
当调用构造函数创建一个实例的时候,实例内部将包含一个内部指针(__proto__)指向构造函数的prototype,这个连接存在于实例和构造函数的prototype之间,而不是实例与构造函数之间。
《JavaScript高级程序设计》P148也有详细解释
<script type="text/javascript"> function Person(name){ //构造函数 this.name=name; } Person.prototype.printName=function() //原型对象 { alert(this.name); } var person1=new Person('Byron');//实例化对象 console.log(person1.__proto__);//Person console.log(person1.constructor);//指向Person的构造函数 console.log(Person.prototype);//指向原型对象Person var person2=new Person('Frank'); </script>
Person的实例person1中包含了name属性,同时自动生成一个__proto__属性,该属性指向Person的prototype,可以访问到prototype内定义的printName方法
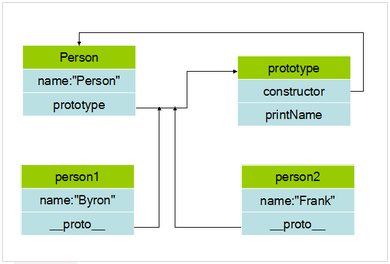
每个JavaScript函数都有prototype属性,这个属性引用了一个对象,这个对象就是原型对象。原型对象初始化的时候是空的,我们可以在里面自定义任何属性和方法,这些方法和属性都将被该构造函数所创建的对象继承。
构造函数、实例和原型对象三者之间有什么关系呢?
实例就是通过构造函数创建的。实例一创造出来就具有constructor属性和__proto__属性,其中constructor属性指向它的构造函数,__proto__属性指向原型对象。
构造函数中有一个prototype属性,这个属性是一个指针,指向它的原型对象。
原型对象内部也有一个指针(constructor属性)指向构造函数:Person.prototype.constructor = Person;
实例可以访问原型对象上定义的属性和方法。
原型链
原型链:当从一个对象那里调取属性或方法时,如果该对象自身不存在这样的属性或方法,就会去自己关联的prototype对象那里寻找,如果prototype没有,就会去prototype关联的前辈prototype那里寻找,如果再没有则继续查找Prototype.Prototype引用的对象,依次类推,直到Prototype.….Prototype为undefined(Object的Prototype就是undefined)从而形成了所谓的“原型链”。
《JavaScript高级程序设计》P162
var a = { x: 10, calculate: function (z) { return this.x + this.y + z } };var b = { y: 20, __proto__: a };var c = { y: 30, __proto__: a }; // call the inherited method b.calculate(30); // 60 c.calculate(40); // 80
我们看到b和c访问到了在对象a中定义的calculate方法。这是通过原型链实现的。
规则很简单:如果一个属性或者一个方法在对象自身中无法找到(也就是对象自身没有一个那样的属性),然后它会尝试在原型链中寻找这个属性/方法。如果这个属性在原型中没有查找到,那么将会查找这个原型的原型,以此类推,遍历整个原型链(当然这在类继承中也是一样的,当解析一个继承的方法的时候-我们遍历class链( class chain))。第一个被查找到的同名属性/方法会被使用。因此,一个被查找到的属性叫作继承属性。如果在遍历了整个原型链之后还是没有查找到这个属性的话,返回undefined值。
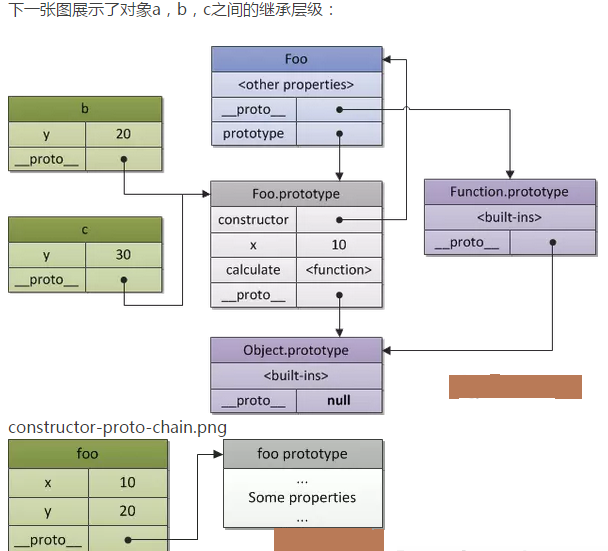
在总结一下,当要查找对象的属性或者方法的时候,会先在对象的实例中查找,没找到的话再到构造函数中查找,构造函数中找不到就到原型对象中查找,在找不到就到原型对象的__protoc__中查找,即上一级对象。这样就构成了一条原型链出来。如下图所示:

构造函数内的方法与构造函数prototype属性上方法的对比
理解什么情况下把函数的方法写在JavaScript的构造函数上,什么时候把方法写在函数的prototype属性上;以及这样做的好处。
为了阅读方便,我们约定一下:把方法写在构造函数内的情况我们简称为函数内方法,把方法写在prototype属性上的情况我们简称为prototype上的方法。
首先我们先了解一下这篇文章的重点:
- 函数内的方法: 使用函数内的方法我们可以访问到函数内部的私有变量,如果我们通过构造函数
new出来的对象需要我们操作构造函数内部的私有变量的话, 我们这个时候就要考虑使用函数内的方法. - prototype上的方法: 当我们需要通过一个函数创建大量的对象,并且这些对象还都有许多的方法的时候;这时我们就要考虑在函数的
prototype上添加这些方法. 这种情况下我们代码的内存占用就比较小. - 在实际的应用中,这两种方法往往是结合使用的;所以我们要首先了解我们需要的是什么,然后再去选择如何使用.
我们还是根据下面的代码来说明一下这些要点吧,下面是代码部分:
// 构造函数A function A(name) { this.name = name || 'a'; this.sayHello = function() { console.log('Hello, my name is: ' + this.name); } } // 构造函数B function B(name) { this.name = name || 'b'; } B.prototype.sayHello = function() { console.log('Hello, my name is: ' + this.name); }; var a1 = new A('a1'); var a2 = new A('a2'); a1.sayHello(); a2.sayHello(); var b1 = new B('b1'); var b2 = new B('b2'); b1.sayHello(); b2.sayHello();
我们首先写了两个构造函数,第一个是A,这个构造函数里面包含了一个方法sayHello;第二个是构造函数B, 我们把那个方法sayHello写在了构造函数B的prototype属性上面.
需要指出的是,通过这两个构造函数new出来的对象具有一样的属性和方法,但是它们的区别我们可以通过下面的一个图来说明:
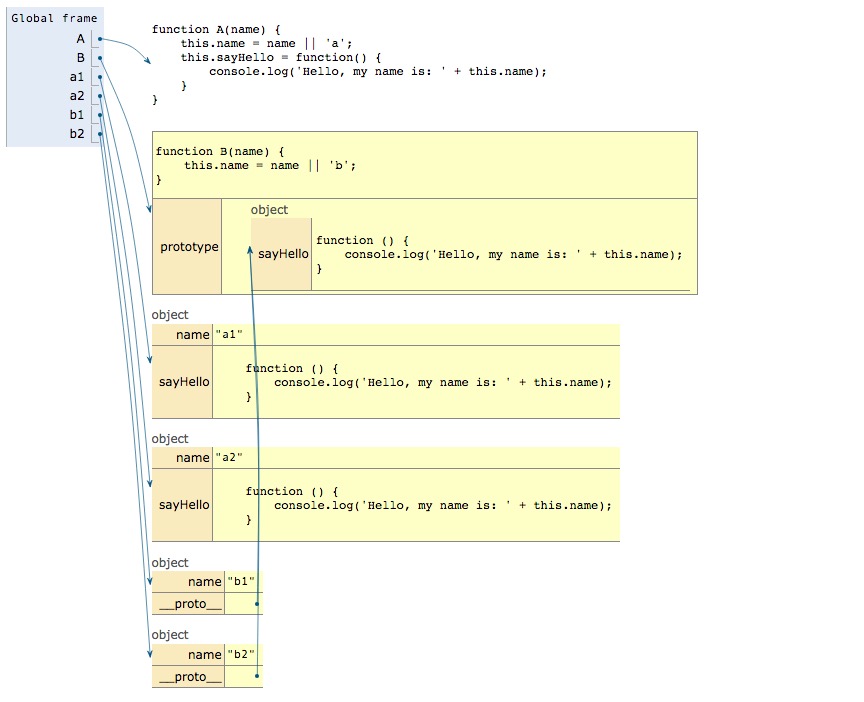
我们通过使用构造函数A创建了两个对象,分别是a1,a2;通过构造函数B创建了两个对象b1,b2;我们可以发现b1,b2这两个对象的那个sayHello方法 都是指向了它们的构造函数的prototype属性的sayHello方法.而a1,a2都是在自己内部定义了这个方法. 定义在构造函数内部的方法,会在它的每一个实例上都克隆这个方法;定义在构造函数的prototype属性上的方法会让它的所有示例都共享这个方法,但是不会在每个实例的内部重新定义这个方法. 如果我们的应用需要创建很多新的对象,并且这些对象还有许多的方法,为了节省内存,我们建议把这些方法都定义在构造函数的prototype属性上。
当然,在某些情况下,我们需要将某些方法定义在构造函数中,这种情况一般是因为我们需要访问构造函数内部的私有变量。
下面我们举一个两者结合的例子,代码如下:
function Person(name, family) { this.name = name; this.family = family; var records = [{type: "in", amount: 0}]; this.addTransaction = function(trans) { if(trans.hasOwnProperty("type") && trans.hasOwnProperty("amount")) { records.push(trans); } } this.balance = function() { var total = 0; records.forEach(function(record) { if(record.type === "in") { total += record.amount; } else { total -= record.amount; } }); return total; }; }; Person.prototype.getFull = function() { return this.name + " " + this.family; }; Person.prototype.getProfile = function() { return this.getFull() + ", total balance: " + this.balance(); };
在上面的代码中,我们定义了一个Person构造函数;这个函数有一个内部的私有变量records,这个变量我们是不希望通过函数内部以外的方法 去操作这个变量,所以我们把操作这个变量的方法都写在了函数的内部.而把一些可以公开的方法写在了Person的prototype属性上,比如方法getFull和getProfile.
把方法写在构造函数的内部,增加了通过构造函数初始化一个对象的成本,把方法写在prototype属性上就有效的减少了这种成本. 你也许会觉得,调用对象上的方法要比调用它的原型链上的方法快得多,其实并不是这样的,如果你的那个对象上面不是有很多的原型的话,它们的速度其实是差不多的
另外,需要注意的一些地方:
- 首先如果是在函数的
prototype属性上定义方法的话,要牢记一点,如果你改变某个方法,那么由这个构造函数产生的所有对象的那个方法都会被改变. - 还有一点就是变量提升的问题,我们可以稍微的看一下下面的代码:
func1(); // 这里会报错,因为在函数执行的时候,func1还没有被赋值. error: func1 is not a function var func1 = function() { console.log('func1'); }; func2(); // 这个会被正确执行,因为函数的声明会被提升. function func2() { console.log('func2'); }
- 关于对象序列化的问题.定义在函数的
prototype上的属性不会被序列化,可以看下面的代码:我们可以看到输出结果是function A(name) { this.name = name; } A.prototype.sayWhat = 'say what...'; var a = new A('dreamapple'); console.log(JSON.stringify(a));
{"name":"dreamapple"}
构造函数内的方法与构造函数prototype属性上方法的对比

