用python爬取豆瓣电影Top 250
首先,打开豆瓣电影Top 250,然后进行网页分析。找到它的Host和User-agent,并保存下来。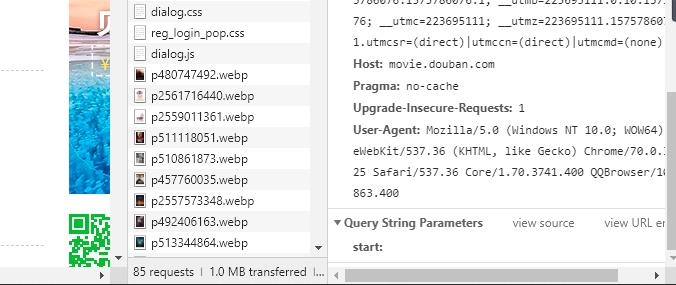 然后,我们通过翻页,查看各页面的url,发现规律:
然后,我们通过翻页,查看各页面的url,发现规律:
第一页:https://movie.douban.com/top250?start=0&filter=
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
第四页:https://movie.douban.com/top250?start=75&filter=
我们发现,每个页面的url都是https://movie.douban.com/top250?start= +25+ &filter=的规律。如此,就可以开始写代码:
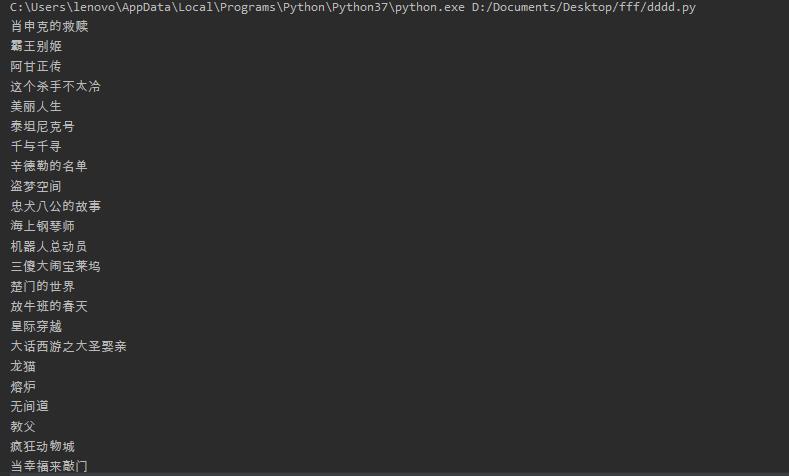
import requests from bs4 import BeautifulSoup def get_movie(): headers={ 'Host': 'movie.douban.com', 'User-Agent': 'Mozilla / 5.0(Windows NT 6.1;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 45.0.2454.101Safari / 537.36' } #防止反扒措施 movie_list=[] for i in range(10): url='https://movie.douban.com/top250?start='+str(i*25) #各页面url response=requests.get(url,headers=headers,timeout=10) soup=BeautifulSoup(response.text,'lxml') div_list=soup.find_all('div',class_='hd') for each in div_list: movie=each.a.span.text.strip() movie_list.append(movie) for j in movie_list: print(j) #按格式输出电影名称 get_movie()
下面给出运行结果: